Les Xeon 14 nm Broadwell-EP arrivent. Ils apportent leur lot d’optimisations et de fonctionnalités permettant à Intel de garder son avantage sur ce marché très juteux.
Broadwell-EP, le 14 nm s’invite sur les serveurs d’Intel
 Le die du Broadwell-EP
Le die du Broadwell-EP
Intel officialise aujourd’hui ses Broadwell-EP, ses nouveaux processeurs Xeon v4 qui remplacent les Haswell-EP (Xeon v3). Sans surprise, le passage au 14 nm permet l’ajout de plus de coeurs tout en maintenant le même TDP. Le processeur est aussi compatible avec le socket LGA2011–3, à condition de mettre à jour le BIOS de la carte mère. C’est pour cela qu’on retrouve le QPI, les lignes PCI-Express ou le contrôleur Ethernet de l’Haswell-EP.
Des fréquences moins traumatisées par l’AVX
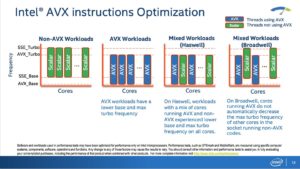 L’architecture a toutefois changé. L’une des grandes nouveautés est l’optimisation de la gestion des fréquences lors de l’exécution d’instructions AVX. En effet, un processeur traitant des instructions classiques ou SSE tournera à une fréquence plus élevée que si on lui envoie des commandes AVX. Sur notre exemplaire de test (un Xeon E5–2697 v4 disposant de 18 coeurs), la fréquence était normale était de 2,3 GHz. Elle descendait à 2 GHz lors de l’utilisation d’instruction AVX.
L’architecture a toutefois changé. L’une des grandes nouveautés est l’optimisation de la gestion des fréquences lors de l’exécution d’instructions AVX. En effet, un processeur traitant des instructions classiques ou SSE tournera à une fréquence plus élevée que si on lui envoie des commandes AVX. Sur notre exemplaire de test (un Xeon E5–2697 v4 disposant de 18 coeurs), la fréquence était normale était de 2,3 GHz. Elle descendait à 2 GHz lors de l’utilisation d’instruction AVX.
La raison est que les instructions AVX consomment plus d’énergie et demandent plus de condensateurs dynamiques, ce qui oblige le processeur à tourner à des fréquences moins rapides. Ce n’est pas un problème dans les faits, puisque l’optimisation apportée par l’instruction surpasse l’impact lié à la plus faible cadence. Sur les Haswell, lorsque certains coeurs recevaient des instructions AVX, l’ensemble des coeurs du processeur baissaient leurs fréquences, y compris ceux qui n’avaient que des instructions classiques ou SSE à prendre en charge. Avec les Broadwell-EP et les optimisations apportées aux régulateurs de tension intégrés, chaque coeur peut adapter sa fréquence en fonction des instructions à traiter. Ainsi, la réception par un, deux ou trois coeurs d’instructions AVX n’aura pas d’impact sur la fréquence des autres coeurs.
A lire aussi :
– Intel Core i7–5775C et Core i5–5675C : Broadwell débarque !
Des calculs optimisés en virgule flottante
Le passage au Broadwell a permis l’exécution de 5,5 % d’instructions de plus par cycle d’horloge en moyenne. Intel a particulièrement optimisé les calculs en virgule flottante. La latence des multiplications vectorielles en virgule flottante passe ainsi de 5 cycles d’horloge à 3. La nouvelle puce peut aussi traiter 32 bits par cycle lors de ses divisions (Radix–1024) grâce, en partie, à l’utilisation d’un pipeline partiel, c’est-à-dire qu’il est possible d’envoyer une information dans le pipeline avant que l’ancienne donnée déjà envoyée ait terminé son trajet dans le pipeline.
Un contrôleur mémoire mis à jour
Le nouveau contrôleur mémoire prend enfin en charge de la mémoire plus rapide offrant un gain de performance d’environ 15 %, selon Intel. Il est compatible avec la DDR4 Write CRC, une nouvelle forme de correction d’erreur optimisée pour ce type de mémoire. Il est aussi compatible 3DS LRDIMM, une RAM utilisant des dies empilés et une architecture composée de dies maîtres et de dies esclaves. Seul un die maître communique avec le contrôleur mémoire. Les autres dies (esclaves) reçoivent leurs informations du die maître ce qui permet d’améliorer les timings, optimiser la gestion du bus mémoire et accroître la bande passante totale.
| Caractéristiques | Xeon E5–2600 v3 (Haswell-EP) | Xeon E5–2600 v4 (Broadwell-EP) |
|---|---|---|
| Finesse | 22 nm | 14 nm |
| Architecture | Haswell | Broadwell |
| Coeurs/Threads par CPU | Jusqu’à 18/36 | Jusqu’à 22/44 |
| Cache L3 | Jusqu’à 45 Mo | Jusqu’à 55 Mo |
| QPI | 2 canaux QPI 1.1 à 6,4, 8 ou 9,6 GT/s | |
| Lignes PCI | 40 PCI-Express 3.0 (2,5, 5, 8 GT/s) | |
| Contrôleur mémoire | 4 canaux de DDR4 (2 133 MT/s) | 4 canaux de DDR4 (2 400 MT/s) |
| Configurations mémoire | Jusqu’à 8 canaux, 24 slots et une capacité de 1 538 Go | |
| Chipset | Intel C610 Wellsburg PCH | |
| Contrôleur Ethernet | Jusqu’à 40 Gbit (Intel XL710 Fortville) | |
| TDP | de 160 W pour les stations de travail à 55 W | |
L’architecture en anneau des Xeon E5 v4
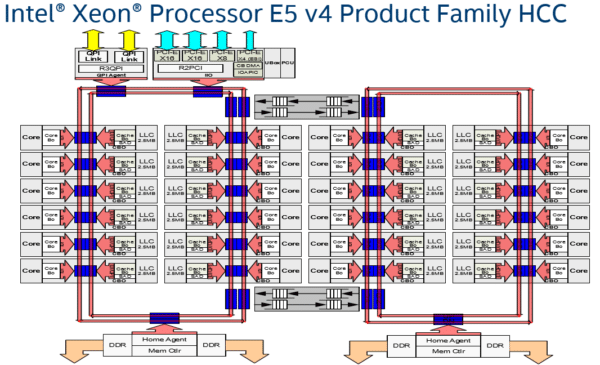 Les XeonBroadwell-EP sont déclinés en trois versions : les HCC (High Count Cores) qui mesurent 18,1 mm x 25,1 mm et qui disposent de 7,2 milliards de transistors. Il y a ensuite les MCC (Medium Core Count) qui mesurent 16,2 mm x 18,9 mm et incluent 4,7 milliards de transistors. Enfin, les LCC (Low Core Count) disposent de 3,2 milliards de transistors pour un die de 16,2 mm x 15,2 mm. Ils utilisent tous une architecture dite en anneau (ring), c’est-à-dire que les coeurs sont structurés en deux colonnes communiquant entre eux à l’aide d’un anneau qui passe aussi par le contrôleur mémoire et le module QPI/PCI-Express.
Les XeonBroadwell-EP sont déclinés en trois versions : les HCC (High Count Cores) qui mesurent 18,1 mm x 25,1 mm et qui disposent de 7,2 milliards de transistors. Il y a ensuite les MCC (Medium Core Count) qui mesurent 16,2 mm x 18,9 mm et incluent 4,7 milliards de transistors. Enfin, les LCC (Low Core Count) disposent de 3,2 milliards de transistors pour un die de 16,2 mm x 15,2 mm. Ils utilisent tous une architecture dite en anneau (ring), c’est-à-dire que les coeurs sont structurés en deux colonnes communiquant entre eux à l’aide d’un anneau qui passe aussi par le contrôleur mémoire et le module QPI/PCI-Express.
Nouvelle symétrie des anneaux pour plus de performances
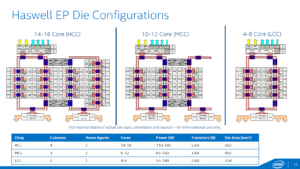 Cette disposition des coeurs n’est pas nouvelle, mais contrairement au Haswell-EP, les colonnes sont maintenant symétriques. Sur les Haswell-EP, la version HCC avait deux coeurs de plus à droite qu’à gauche. Intel propose maintenant le même nombre de coeurs des deux côtés pour optimiser les interconnexions et les accès aux mémoires cache. Concrètement, le HCC offre deux anneaux de 2 x 11 coeurs, le MCC intègre un anneau de 10 coeurs et un demi-anneau de 5 cores. Enfin, la version LCC offre un anneau pouvant monter jusqu’à 10 coeurs.
Cette disposition des coeurs n’est pas nouvelle, mais contrairement au Haswell-EP, les colonnes sont maintenant symétriques. Sur les Haswell-EP, la version HCC avait deux coeurs de plus à droite qu’à gauche. Intel propose maintenant le même nombre de coeurs des deux côtés pour optimiser les interconnexions et les accès aux mémoires cache. Concrètement, le HCC offre deux anneaux de 2 x 11 coeurs, le MCC intègre un anneau de 10 coeurs et un demi-anneau de 5 cores. Enfin, la version LCC offre un anneau pouvant monter jusqu’à 10 coeurs.
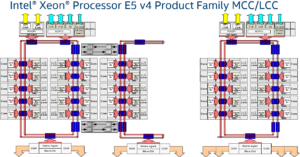 Chaque coeurs dispose de 2,5 Mo de cache L3 partagé sur l’anneau et un accès à cette mémoire demande en moyenne 12 cycles d’horloge. Chaque anneau dispose de son propre scheduler qui va s’occuper de coordonner les accès. L’anneau fut créé pour être bidirectionnel. On peut donc décider de le monter ou le descendre pour trouver l’information le plus rapidement possible. Intel propose plusieurs anneaux sur ses configurations HCC et MCC pour réduire les temps d’accès à la mémoire cache et les paralléliser si les informations sont sur des anneaux différents. Le trafic entre les anneaux est assuré par un pont et passer d’un anneau à l’autre représente une pénalité d’environ 5 cycles d’horloge.
Chaque coeurs dispose de 2,5 Mo de cache L3 partagé sur l’anneau et un accès à cette mémoire demande en moyenne 12 cycles d’horloge. Chaque anneau dispose de son propre scheduler qui va s’occuper de coordonner les accès. L’anneau fut créé pour être bidirectionnel. On peut donc décider de le monter ou le descendre pour trouver l’information le plus rapidement possible. Intel propose plusieurs anneaux sur ses configurations HCC et MCC pour réduire les temps d’accès à la mémoire cache et les paralléliser si les informations sont sur des anneaux différents. Le trafic entre les anneaux est assuré par un pont et passer d’un anneau à l’autre représente une pénalité d’environ 5 cycles d’horloge.
Un Broadwell-EP peut cacher un autre processeur
Les plus perspicaces auront noté que le schéma de la version HCC présente un total de 24 coeurs, mais que le Xeon E5 v4 le plus performant n’a « que » 22 cores. Intel admet en avoir désactivé deux, mais qu’il y a bien 24 coeurs sur le die. On imagine que le fondeur va sortir une déclinaison plus performante de son Broadwell utilisant les deux coeurs aujourd’hui désactivés.
Il est enfin intéressant de noter qu’il y a un contrôleur mémoire par anneau et qu’ils ont tous quatre canaux. Cela signifie donc qu’il pourrait y avoir huit canaux sur les versions HCC et MCC, mais qu’Intel n’utilise que deux canaux par contrôleur dans ces configurations, sans doute pour assurer la compatibilité avec les cartes mère Haswell-EP. L’utilisation de deux contrôleurs augmente les performances, puisque chacun d’eux a son scheduler. Ainsi, même si les contrôleurs sont identiques, on s’attend à ce que l’ensemble soit plus performant que sur la configuration LCC qui ne dispose que d’un contrôleur. Enfin, seul l’anneau de gauche a accès aux QPI et aux lignes PCI-Express. 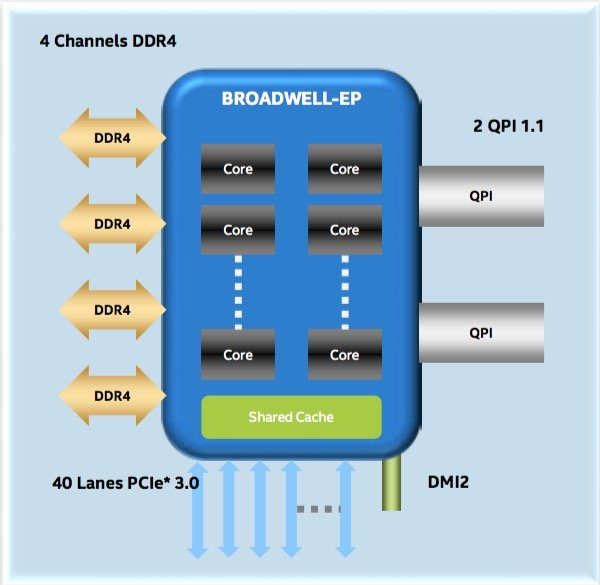
Optimisations de la consommation et la virtualisation
Intel a présenté plusieurs technologies destinées à améliorer les performances de son Broadwell-EP en entreprise.
Hardware Controlled Power Management (HWPM)
 Normalement, le système d’exploitation d’un serveur va prévenir le processeur que certaines tâches ne demandent pas beaucoup de ressources et lui conseiller d’abaisser sa fréquence. Même si le processeur accepte, le temps que prend cette communication est souvent trop long. Avec le HWPM, la puce n’a pas besoin de passer par le système d’exploitation. Il suffit d’activer la fonctionnalité dans le BIOS en sélectionnant un des quatre profils prédéfinis pour profiter d’une gestion de la consommation entièrement déterminée par le processeur.
Normalement, le système d’exploitation d’un serveur va prévenir le processeur que certaines tâches ne demandent pas beaucoup de ressources et lui conseiller d’abaisser sa fréquence. Même si le processeur accepte, le temps que prend cette communication est souvent trop long. Avec le HWPM, la puce n’a pas besoin de passer par le système d’exploitation. Il suffit d’activer la fonctionnalité dans le BIOS en sélectionnant un des quatre profils prédéfinis pour profiter d’une gestion de la consommation entièrement déterminée par le processeur.
Les communications au sein du die étant nettement plus rapides, cela permet d’économiser ou augmenter la fréquence plus rapidement lorsque la charge du processeur change. Les profils vont de « puissance maximum » à « consommation minimum ». De plus, le processeur utilise des informations qui ne sont pas disponibles aux logiciels, ce qui offre une optimisation exemplaire, selon Intel. La présence de profils montre que le fondeur continue d’optimiser cette technologie.
En effet, selon nos benchmarks, pour un nombre de coeurs et des fréquences identiques, le Broadwell-EP offre une consommation légèrement inférieure à un Haswell-EP. Il est fort probable que la finesse de gravure y soit pour quelque chose, mais il ne faut pas balayer trop vite le HWPM. Ce dernier pourrait être un système important pour Intel, quand le fondeur l’aura perfectionné.
Posted Interrupts
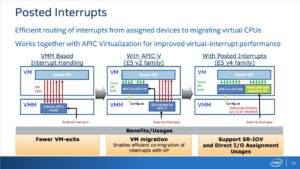 En informatique, une interruption (interrupt en anglais) est un message d’alerte envoyé au processeur pour dire qu’un évènement demande son attention immédiate. Cela provoque traditionnellement la suspension de l’exécution d’un programme, la sauvegarde de l’état en cours et le lancement d’une fonction qui va s’occuper de l’évènement qui a causé cette interruption. Certaines interruptions sont complètement bénignes, tandis que d’autres sont nettement plus sérieuses et peuvent être causées par des erreurs graves.
En informatique, une interruption (interrupt en anglais) est un message d’alerte envoyé au processeur pour dire qu’un évènement demande son attention immédiate. Cela provoque traditionnellement la suspension de l’exécution d’un programme, la sauvegarde de l’état en cours et le lancement d’une fonction qui va s’occuper de l’évènement qui a causé cette interruption. Certaines interruptions sont complètement bénignes, tandis que d’autres sont nettement plus sérieuses et peuvent être causées par des erreurs graves.
A lire aussi :
– Comparatif virtualisation : les solutions gratuites
La fonctionnalité posted interrupt des nouveaux Xeon permet au processeur de gérer les interruptions pouvant survenir au sein d’environnements virtualités. Auparavant, une interruption externe passait obligatoirement par l’hyperviseur qui la faisait remonter à la machine virtuelle concernée. Cela avait le grand désavantage d’obliger le système à quitter la machine virtuelle pour passer à l’hyperviseur et retourner ensuite sur le système d’exploitation virtuelle. Avec la fonctionnalité posted interrupt, c’est le processeur qui se charge d’envoyer directement l’interruption à la machine virtuelle qui s’en occupera lorsqu’elle sera de nouveau active. Cela permet de grandement réduire les temps de latence et accroître les performances.
Des résultats modestes dans nos benchmarks
Sysbench CPU
Sysbench CPU est un test théorique très généraliste qui tente de mesurer les performances de l’ensemble du système. Sous ce benchmark, l’E5–2699 v3 prend une légère avance sur l’E5–2697 v4 sans qu’elle soit suffisamment importante pour que cela témoigne d’un problème. Les deux puces systèmes sont juste très proches l’un de l’autre.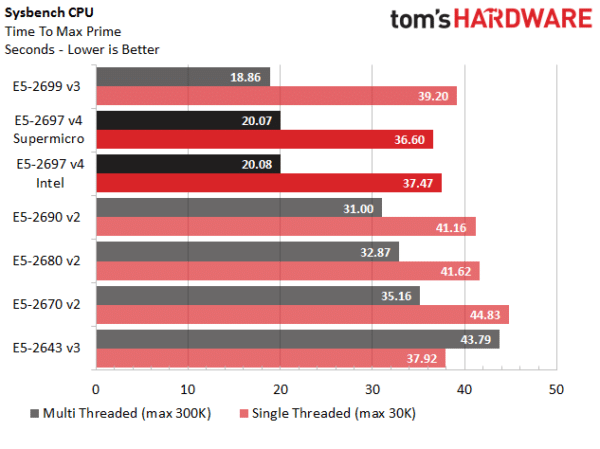
Unix Bench
Sur Unix Bench, le test Whetstone met en avant les performances du processeur lors des calculs en virgule flottante. Il montre un gain de 20 % lorsque l’on passe sur les Broadwell-EP, comparativement aux Haswell-EP, probablement en raison des optimisations apportées à l’architecture. Sur le test Dhrystone 2, qui n’a aucun calcul en virgule flottante, l’augmentation se limite par contre à environ 4 %.
NAMD et NAS Parallel
Le test NAMD est destiné à mesurer les performances lors de l’exécution d’un logiciel optimisé pour tirer partie du parallélisme des puces. Les optimisations apportées par l’architecture en anneau des Broadwell-EP offre ici un gain d’environ 14 %. Par contre, tous les logiciels ne témoignent pas du même gain. Sous NAS (NASA Advanced Supercomputing) Parallel, qui est censé mesurer la même chose, il n’y a pratiquement aucun gain entre l’architecture Haswell-EP et le nouveau Broadwell-EP.
Redis
Redis (REmote Dictionary Server) est un benchmark qui teste la bande passante mémoire et les performances du processeur. Il montre que l’utilisation d’un contrôleur mémoire plus rapide, en combinaison avec les modifications de l’architecture, offre un gain de performance se situant entre 8 % et 12 %, suivant les opérations.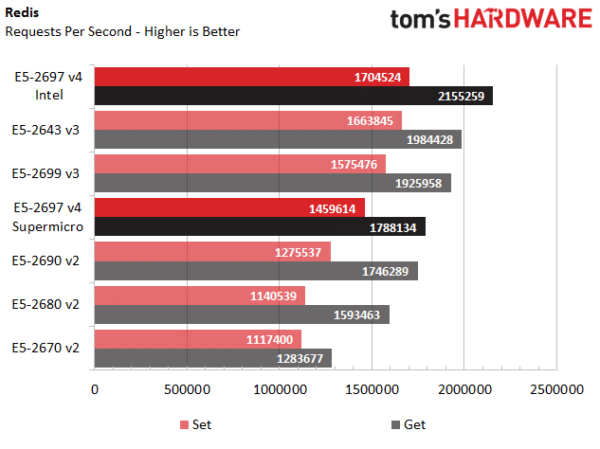
Conclusions
 Un Xeon Broadwell-EP et ses mémoires
Un Xeon Broadwell-EP et ses mémoires
Les nouvelles puces pour serveurs Xeon E5 v4 (Broadwell-EP) apportent de nouvelles fonctionnalités intéressantes et de belles optimisations architecturales. Néanmoins, cela ne se traduit généralement que par un gain de performances assez faible, voire inexistant dans certains cas, mais Intel joue à un jeu différent.
Intel ne joue pas le jeu des performances
Les Broadwell-EP ne sont pas là pour gagner la couronne des performances, puisqu’Intel la possède déjà, et personne ne remet son hégémonie en question. Les serveurs ARM ou PowerPC sont une espèce à part. Les Opteron d’AMD sont tellement loin que personne n’y pense. Bref, le but des Broadwell-EP n’est pas d’établir de nouveaux records. Dans le meilleur des cas, ils sont 20 % plus performants, surtout lorsque l’application tire parti des optimisations apportées aux calculs en virgule flottante. Dans la plupart des situations traditionnelles, on devrait avoir un gain de 10 % ou moins.
Intel parle le langage des entreprises
Intel devrait par contre séduire beaucoup d’entreprises désirant mettre à jour leurs systèmes Ivy Bridge et Sandy Bridge ou garder leurs systèmes Haswell-EP et simplement mettre leur processeur à jour pour allonger la durée de vie de leurs serveurs ou stations de travail. Ceux qui chercheront plus de coeurs en trouveront 4 de plus (et 6 dans un futur plus ou moins proche). Ceux qui souhaitent optimiser leurs machines virtuelles ou la sécurité de leurs systèmes trouveront des fonctionnalités intéressantes. Ceux qui ont besoin de remplacer leurs systèmes Skylake ou Ivy Bridge auront un gain de performance suffisant pour justifier leur achat. Au final, on voit que le fondeur a vraiment compris comment parler aux entreprises pour qu’elles restent fidèles à son écosystème. L’hégémonie d’Intel n’est pas prête de s’éroder.
Intel CM8065802483001









