Gigantesque !
 La nouvelle architecture Volta La nouvelle architecture Volta |
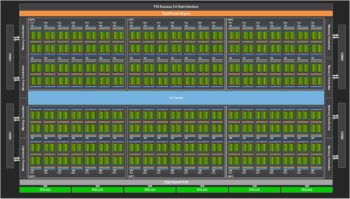 |
Le GV100 est le plus gros GPU jamais fabriqué par Nvidia, et le plus gros du marché puisque ses 21 milliards de transistors gravés en 12 nm occupent une surface de 815 mm2. La nouvelle puce, la première basée sur l’architecture Volta se distingue par la présence de nouveaux coeurs complètement inédit, les coeurs Tensor. Destinés à optimiser l’apprentissage automatique, ils accélèrent certains calculs FP16 et FP32 au point d’atteindre une puissance théorique sur ces instructions spécifiques de 120 TFLOPS par GPU.
| À lire aussi : – Comparatif : les cartes graphiques du moment au banc d’essai |
5376 coeurs CUDA
 L’architecture GV100 dispose de six Graphics Processing Cluster contenant chacun 14 Volta Streaming Multiprocessor. Chaque Streaming Multiprocessor a 64 coeurs CUDA FP32, ce qui fait un total de 5376 coeurs CUDA.
L’architecture GV100 dispose de six Graphics Processing Cluster contenant chacun 14 Volta Streaming Multiprocessor. Chaque Streaming Multiprocessor a 64 coeurs CUDA FP32, ce qui fait un total de 5376 coeurs CUDA.
La première carte à utiliser le GV100, la Tesla V100, utilise une version légèrement bridée contenant quatre Streaming Multiprocessor désactivés pour un total de 5120 coeurs CUDA. Sa puissance de calcul FP32 générique, hors coeurs Tensor, est de 15 TFlops, soit 40 % de mieux que la Tesla P100.
Deux cartes
NVIDIA proposera dans un premier temps deux cartes graphiques embarquant sa nouvelle mouture. La première aura un design single slot et un TDP de seulement 150 W, contre 300 W pour le modèle double slot. La firme n’a pas de donnée de détails supplémentaires, mais on imagine que les deux auront des fréquences très différentes.
 |
 |
| Caractéristiques | Tesla K40 | Tesla M40 | Tesla P100 | Tesla V100 |
|---|---|---|---|---|
| GPU | GK110 (Kepler) | GM200 (Maxwell) | GP100 (Pascal) | GV100 (Volta) |
| Streaming Multiprocessors (SM) | 15 | 24 | 56 | 80 |
| Texture Processor Cluster | 15 | 24 | 28 | 40 |
| Coeurs CUDA FP32 / SM | 192 | 128 | 64 | 64 |
| Coeurs CUDA FP32 / GPU | 2880 | 3072 | 3584 | 5120 |
| Coeurs CUDA FP64 / SM | 64 | 4 | 32 | 32 |
| Coeurs CUDA FP64 / GPU | 960 | 96 | 1792 | 2560 |
| Coeurs CUDA Tensor / SM | NA | NA | NA | 8 |
| Coeurs CUDA Tensor / GPU | NA | NA | NA | 640 |
| Fréquence Boost | 810/875 MHz | 1114 MHz | 1480 MHz | 1455 MHz |
| Puissance théorique FP32 (TFLOPS) | 5,04 | 6,8 | 10,6 | 15 |
| Puissance théorique FP64 (TFLOPS) | 1,68 | 2,1 | 5,3 | 7,5 |
| Puissance théorique TensorOp (TFLOPS) | NA | NA | NA | 120 |
| Unités de Texture | 240 | 192 | 224 | 320 |
| Interface mémoire | GDDR5 384 bits | GDDR5 384 bits | HBM2 4096 bits | HBM2 4096 bits |
| VRAM | jusqu’à 12 Go | jusqu’à 24 Go | 16 Go | 16 Go |
| Cache L2 | 1536 ko | 3072 ko | 4096 ko | 6144 ko |
| Mémoire partagée / SM | 16 ko/32 ko/48 ko | 96 ko | 64 ko | jusqu’à 96 ko |
| TDP | 235 W | 250 W | 300 W | 300 W |
| Transistors | 7,1 milliards | 8 milliards | 15,3 milliards | 21,1 milliards |
| Surface GPU | 551 mm² | 601 mm² | 610 mm² | 815 mm² |
| Finesse | 28 nm | 28 nm | 16 nm FinFET+ | 12 nm FFN TSMC |