En 1993, le supercalculateur le plus performant de l’époque était moins puissant qu’un Ryzen ou qu’un processeur Core actuel !
Le classement TOP500 fut publié pour la première fois en juin 1993, il y a presque 30 ans. À cette époque, le plus puissant ordinateur du monde était un CM5, fabriqué par Connection Machines, installé au Los Alamos National Laboratory, un laboratoire de l’Université de Californie géré par le ministère de l’énergie américain. Sa puissance, démesurée à l’époque, fait pâle figure aujourd’hui : un Ryzen 7 de première génération fait mieux à lui tout seul. Depuis, la puissance des superordinateurs a progressé de manière quasi-exponentielle.

Avec ses 1024 processeurs SuperSparc à 32 MHz, le CM5/1024 était donc le premier superordinateur à prendre la tête de ce classement. Sa puissance théorique était de 131 GFlops, mais il atteignait moins de la moitié (59,7 GFlops) sous le benchmark LINPACK utilisé pour établir le classement TOP500. Le CM5 connu une autre consécration en 1993, puisqu’il fut choisi par Steven Spielberg pour “incarner” le cerveau de la salle de contrôle de Jurassic Park.
À lire > Guide d’achat processeurs : AMD Ryzen ou Intel Core, quel CPU acheter ?
Juin 1994 : XP/S140
En juin 1994, le CM5 fut destitué par l’Intel Paragon XP/S140. Ce supercalculateur acheté par le Sandia National Laboratories au Nouveau Mexique, employait 3680 processeurs Intel i860 XP, une des rares puces à jeu d’instruction RISC fabriquées par Intel.

Le i860 était très innovant pour l’époque, intégrant une unité arithmétique 32 bits et une unité de calcul sur les flottants 64 bits. Chacune accédait à 32 registres 32 bits, qui pouvaient être utilisés aussi comme 16 registres 64 bits ou 8 registres 128 bits. Le jeu d’instructions exécutable par la FPU comprenait également des instructions de type SIMD qui ont jeté les bases du MMX introduit plus tard sur les Pentium.
Chaque processeur i860 cadencé à 50 MHz délivrait une puissance brute de 0,05 GFlops. La puissance théorique du XP/S140 était de 184 GFlops, et il atteignait en pratique 143,4 GFlops sous Linpack.
Novembre 1994 : le Japon prend le vent
En novembre 1994, le plus puissant calculateur du monde devient le Numerical Wind Tunnel fabriqué par Fujitsu pour le laboratoire national d’aérospatial du Japon. Cette machine marque une rupture avec ses prédécesseurs puisqu’elle tire sa puissance de seulement 140 processeurs vectoriels et non scalaires. Ces puces tournaient à 105 MHz étaient particulièrement adaptées aux simulations d’écoulement des fluides. Elles possédaient chacune quatre pipelines indépendants, capables de traiter deux instructions Multiply-Add par cycle.

Mais ces processeurs étaient en fait des cartes composées de 121 puces distinctes, arrangées selon une matrice de 11 x 11. Chaque puce possédait une fonction dédiée. Un “processeur” consommait à lui seul 3 000 W, et nécessitait un refroidissement à eau. Chaque CPU délivrait une puissance théorique de 1,7 GFlops. Au total, le Numerical Wind Tunnel fut le premier calculateur à franchir la barre des 200 GFlops théoriques, même si sa performance sous Linpack était un peu inférieure (124 GFlops, puis 170 GFlops et enfin 192 GFlops au fil des upgrades).
Juin 1996 : Hitachi bat Fujitsu
Un an plus tard, le TOP500 sacre encore une fois le Japon, la première place du classement étant occupée par le SR2201/1024 construit par Hitachi pour l’université de Tokyo. Le Japon occupe alors les deux premières places du TOP500, reléguant les USA en troisième position.

Cette machine remet les supercalculateurs scalaires RISC à l’honneur : elle contient 1024 CPU HARP-1E (vu ci-dessus en coupe aux UV) basés sur l’architecture PA-RISC. Cadencés chacun à 150 MHz, ces CPU offraient une puissance théorique individuelle de 300 MFlops : le SR2201/1024 cumulait donc 300 GFlops. Les HARP-1E introduisaient un mécanisme baptisé Pseudo Vector Processing permettant de précharger des données directement dans les registres des CPU sans passer par le cache. Grâce à lui, entre autres, le rendement du SR2201/1024 était très bon. Sous Linpack il atteignit 232 GFlops, 72 % de sa puissance théorique.
Juin 1997 : le TéraFlops est vaincu
Afin de conserver leur avance technologique, les États-Unis ont lancé en 1992 le programme Accelerated Strategic Computing Initiative, ou ASCI. La première réussite de ce programme fut la mise au point de l’ASCI Red, un supercalculateur construit par Intel pour le Sandia Lab (le même qui possédait déjà l’XP/S140). L’ASCI Red a marqué les esprits car il fut le premier ordinateur de l’histoire a franchir la barrière du téraflops.

Grâce à ses 7264 Pentium Pro 200 MHz, il offrait une puissance théorique de 1,453 TFlops, et 1,068 TFlops en pratique sous Linpack. L’ASCI Red était un des premiers supercalculateurs à utiliser des composants de grande série. Son architecture modulaire et évolutive lui permis de rester en tête du TOP500 pendant plusieurs années.
Juin 1999 : ASCI Red 2.0, puissance doublée
En 1999, Intel met à jour l’ASCI Red en remplaçant les Pentium Pro 200 MHz par des Pentium II OverDrive à 333 MHz (des Pentium II pouvant prendre place dans le socket 8 des Pentium Pro). Cette opération, associée à une légère augmentation du nombre de CPU (9472), double la puissance théorique de l’ASCI Red : il dépasse les 3,1 TFlops. Sa puissance pratique double aussi pour atteindre les 2,121 TFlops.

Trois ans après son premier sacre, le monstre s’est encore amélioré (9632 CPU), et réalise 3,207 TFlops théoriques et 2,379 TFlops pratiques. L’ASCI Red occupe désormais une surface de 230 m2 et engloutit 850 kW, sans compter l’énergie nécessaire au système de refroidissement.
Juin 2001 : ASCI White, passage à IBM et aux clusters
Un ASCI chasse l’autre. En novembre 2000, le Red cède sa place au White, installé au coeur du Lawrence Livermore National Laboratory. À moitié opérationnel fin 2000, l’ASCI White est complété en juin 2001.

Avec lui, IBM prend sa revanche sur Intel. L’ASCI White tire sa puissance de 8192 processeurs IBM Power3 à 375 MHz. L’ASCI White lance une nouvelle tendance en adoptant une architecture en clusters. Elle est utilisée aujourd’hui par 85 % des supercalculateurs listés au TOP500.
L’ASCI White regroupe en réalité 512 serveurs RS/6000 SP contenant chacun 16 CPU. Chaque CPU offrant une puissance 1,5 GFlops, l’ASCI White était en théorie capable d’atteindre 12,3 TFlops. Son rendement s’avéra malheureusement faible puisqu’il n’atteignit que 7,2 TFlops sous Linpack (7,3 TFlops à partir de 2003). L’ASCI White réclame 3 MW (3000 kW) pour fonctionner. 3 MW de plus sont consommés par son système de refroidissement.
Juin 2002 : Earth Simulator fait trembler la concurrence
En juin 2002, le TOP500 est bouleversé par la mise en marche de Earth Simulator. Construit au Earth Simulator Center de Yokohama, ce monstre dépasse ses concurrents de la tête et des épaules : il parvient à réaliser 35,86 TFlops sous Linpack, soit environ 5 fois plus que l’ASCI White.

Son rendement est également excellent à 87,5 %. L’Earth Simulator, dédié à des simulations climatiques, est construit à partir de processeurs NEC spécifiques contenant une unité superscalaire et une unité vectorielle. Cadencé en partie à 500 MHz et en partie à 1 GHz, chacun de ces CPU délivre une puissance théorique de 8 GFlops et consomme 140 W. L’Earth Simulator est organisé en 640 noeuds de 8 processeurs. Chaque noeud avalait 10 kW.
Juin 2003 : ASCI Q sur processeurs Alpha
L’Earth Simulator avait tellement d’avance qu’il resta en tête du TOP500 jusqu’en juin 2004. Entre-temps, les concurrents ont néanmoins progressé. Ainsi, en juin 2003, le numéro deux est l’ASCI Q, construit par HP au Los Alamos National Laboratory.

L’ASCI Q devait à l’origine être composé de trois segments, comptant chacun 1024 serveurs AlphaServer ES45 d’HP. Le TOP500 ne fait cependant apparaître que la machine dotée de 2 segments. Chaque serveur contient deux processeurs Alpha 21264 cadencés à 1,25 GHz. La puissance théorique totale du système s’établissait à 20,5 TFlops, ce qui se traduisait par 13,9 TFlops sous Linpack.
Novembre 2003 : L’intrus : System X, alias Big Mac
Descendons encore un peu dans le classement du TOP500 pour parler d’une initiative unique. Au cours de l’été 2003, l’université Virginia Tech décide de se construire supercalculateur à “bas prix” à partir de machines grand public. Son choix se porte sur les PowerMac G5 d’Apple.

La construction du Big Mac, ou System X de son nom officiel, n’aura pris que trois mois et coûté que 5,2 millions de dollars (contre 400 millions de dollars pour l’Earth Simulator). Au classement TOP500 de novembre 2003, le Big Mac se hissa à la troisième place, avec 10,3 TFlops calculés sous Linpack.
Le Big Mac comptait 1100 PowerMac G5, équipés chacun de 2 CPU PowerPC 970 à 2 GHz (8 GFlops/CPU). Le Big Mac fut mis à jour en 2004 en remplaçant ses PowerMac par des Xserve, ce qui boosta sa puissance à 12,25 TFlops.
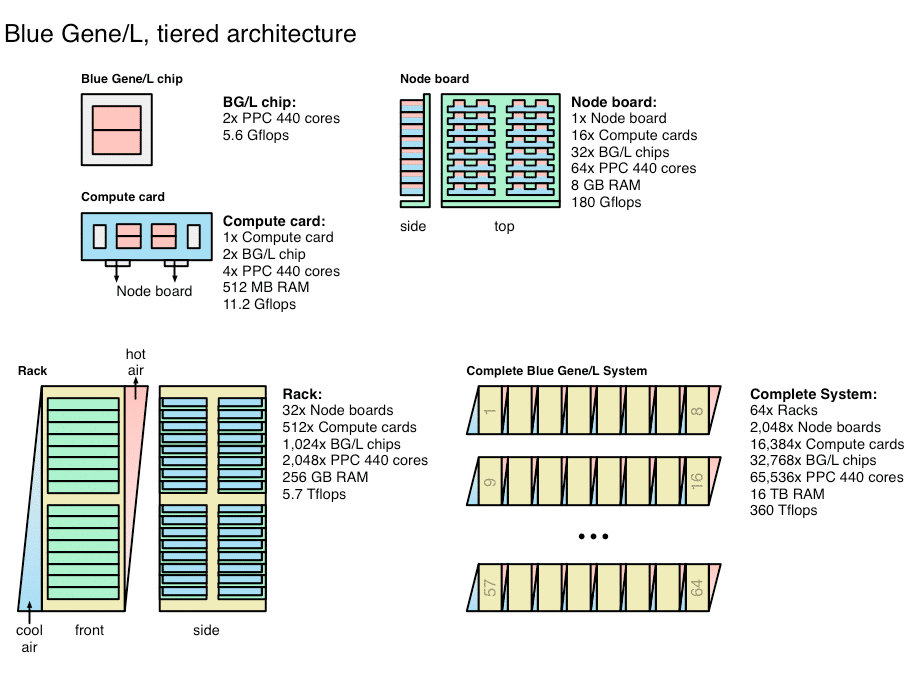
Novembre 2004 : Blue Gene/L détrône enfin Earth Simulator
En septembre 2004, la suprématie de l’Earth Simulator fut enfin vaincue par le BlueGene/L d’IBM. Encore en construction, il atteignait déjà 36 TFlops. En Novembre 2004, il montait à 70,7 TFlops le double de l’Earth Simulator. Au classement de juin 2005, le BlueGene/L réalisa le record de 136,8 TFlops sous Linpack, presque 4 fois plus que l’Earth Simulator. Le BlueGene/L fut alors le premier à passer la barre des 100 TFlops.

Pour atteindre ce record, IBM employa 65536 processeurs PowerPC 440 à 700 MHz. Déjà à l’époque, ces puces ne faisaient plus partie des plus puissantes du marché. Mais elles étaient compactes et consommaient relativement peu ce qui permettait à IBM de les installer deux par deux sur de petits cartes (ci-dessus) enfichées dans la carte mère de chaque rack. Le BlueGene/L révéla également un très bon rendement : sa puissance sous Linpack correspond à 75 % de sa puissance théorique.
Juin 2006 : BlueGene/L 2.0, la progression fulgurante
Fin 2005, le BlueGene/L du Lawrence Livermore National Laboratory a vu sa capacité doubler : le nombre de processeurs atteint 131 072. Il n’a donc pas eu de mal à garder la tête du TOP500, et son efficacité sous Linpack fut même légèrement augmentée. Sa performance enregistrée au classement est de 280,6 TFlops. Le pari d’IBM d’utiliser un très grand nombre de puces assez peu puissantes paie en outre au niveau de la consommation : le BlueGene/L ne consomme que 1,2 MW.
À l’époque, le BlueGene/L était toujours le seul à dépasser les 100 TFlops, le second système du TOP500 plafonnant à 91,3 TFlops. Remarquons également qu’en juin 2006, le Tera 10 français se classe 6e avec 42,9 TFlops sous Linpack.
Juin 2007 : Jaguar, AMD dans la cours des grands
Deux ans après sa consécration, le BlueGene/L est toujours premier. Il est néanmoins rejoint dans le club des “plus de 100 TFlops” par deux autres machines, le Jaguar (n°2) et le Red Storm (n°3). Jaguar dont nous allons avoir l’occasion de reparler.

En juin 2007, Jaguar, qui existe et évolue sans cesse depuis 2005 est un assemblage de serveurs Cray XT4 et XT3. Il marque l’entrée dans la cour des grands d’AMD : les Cray utilisent des Opteron dual core à 2,6 GHz. Au total, Jaguar compte à l’époque 11508 processeurs et atteint 101,7 TFlops sous Linpack.
Juin 2008 : Roadrunner, premier hybride, premier pétaFLOPS
Bip ! Bip ! IBM succède à IBM. Le Roadrunner succède au BlueGene/L et est le premier de l’histoire à dépasser le seuil du pétaflops. Roadrunner est en outre une vraie rupture technologique : il est le premier supercalculateur hybride, utilisant à la fois des processeurs généralistes et des “accélérateurs”.

IBM a bien sûr utilisé une technologie maison : le processeur Cell, inauguré par la PlayStation 3. Il est ici employé comme coprocesseur auprès de CPU X86 classiques, des Opteron d’AMD. Roadrunner contient alors 122 400 coeurs de calcul, répartis entre 6562 Opteron dual core à 1,8 GHz et 12 240 PowerXCell 8i 3200 (8+1 coeurs, 3,2 GHz) dans des serveurs lame LS21 et QS22 (ci-dessus). La puissance théorique totale est de 1,38 PFlops. Roadrunner prit la tête du TOP500 de juin 2008 avec 1,04 PFlops sous Linpack.
Un des avantages des architectures hybrides est leur meilleur rendement énergétique. Roadrunner consomme seulement 2,35 MW, soit 437 MFlops/W. Le monstre pèse 227 tonnes et occupe une surface de 483 m2 dans le laboratoire de Los Alamos où il est installé.
Juin 2009 : Roadrunner se muscle
Comme l’ASCI Red ou le BlueGene/L avant lui, le Roadrunner a conservé la tête du TOP500 plusieurs mois de suite grâce à des mises à jour qui ont augmenté sa puissance. Ainsi, depuis novembre 2008, le nombre total de coeurs de calcul est monté à 129 600 (6480 Opteron DC et 12960 PowerXCell 8i) et la performance sous Linpack à 1,1 PFlops.

Cette légère hausse a tout juste suffi à Roadrunner pour se maintenir au TOP500 : son dauphin, le Jaguar mis à jour (des Cray XT5 ont remplacé les précédents XT4 et XT3) a été flashé à 1,059 PFlops. Jaguar et Roadrunner sont alors les deux seuls à dépasser le pétaflops.
Juin 2010 : Jaguar 3.0, AMD Opteron reprend la tête, sans config hybride
En novembre 2009, Jaguar réussit enfin à déloger Roadrunner de la première place. Il est depuis composé de deux “partitions” : une ancienne composée de 7832 Cray XT4 contenant chacun un processeur Opteron 1345 quad core Budapest à 2,1 GHz et une nouvelle, faite de 18 868 Cray XT5 contenant chacun deux processeurs Opteron 2435 hexacore Istanbul à 2,6 GHz.

La seule partition XT5 réunit donc 224 162 coeurs de calcul. Sa puissance théorique de 2,33 PFlops (10,4 GFlops par Istanbul) s’est traduite par 1,76 PFlops sous Linpack. La partition XT4 affiche quant à elle une puissance théorique de 263 TFlops. Contrairement au Roadrunner, Jaguar n’a pas un très bon rendement énergétique : il consomme à peu près 7 MW (253 MFlops/W).
2010 en France : Tera-100, CEA, le premier pétaFLOPS européen
En 2010, le Tera-100 utilisé par le CEA (Commissariat à l’Énergie Atomique) se hisse directement à la sixième place du TOP500 grâce à sa puissance théorique de 1,254 PFlops. En pratique, ce supercalculateur Bullx Super-Node S6010/S6030 fabriqué par Bull (groupe Atos) affiche une puissance réelle de 1,05 PFlops. Il s’agit alors du premier supercalculateur “pétaflopique” conçu et développé en Europe.

Le Tera-100 se compose de 17296 processeurs Intel Xeon X7560 octo-cores (Nehalem-EX) cadencés à 2,26 GHz, soit un total de 138368 cores, de 300 To de mémoire et de 20 Po d’espace de stockage. L’ensemble affiche une consommation de 4,59 MW et fonctionne sous Linux. Ce supercalculateur est destiné au programme Simulation du CEA.
2010 : Tianhe-1A, éveil de la Chine et des GPU
2010 aura marqué l’entrée de la Chine dans la cour des grands du calcul à très hautes performances. Deux systèmes chinois ont pris la tête du TOP500. En juin 2010, le Nebulae affichait la plus grande puissance théorique (2,98 PFlops), même si sa performance sous Linpack restait inférieure à celle du Jaguar. Le Tianhe-1A prit du top de novembre 2010 à la fois en puissance théorique (4,7 PFlops) et sous Linpack (2,57 PFlops).

Les performances de Tianhe-1A et Nebulae consacrent également les GPU comme processeurs de calcul généralistes. Comme Roadrunner, ces deux machines sont en effet hybrides et associent des processeurs x86 Intel Xeon X5600 (X5650 dans Nebulae, X5670 dans Tianhe-1A) à des processeurs graphiques Nvidia Tesla “Fermi” (C2050 pour Nebulae, M2050 pour Tianhe-1A). Le GPGPU a enfin trouvé ses lettres de noblesse ! Grâce à cette association, les deux supercalculateurs chinois affichent un rendement énergétique excellent : Tianhe-1A consomme seulement 4 MW, soit 640 MFlops/W.
Juin 2011 : K Computer, le Japon se fâche
En juin 2011, le Japon a repris la couronne des performances avec le K Computer de Fujitsu, installé dans l’institut des sciences informatiques avancées RIKEN. Il est une des rares machines de ce genre à disposer d’une puissance théorique proche de sa puissance pratique. À plus de 8 PFLOPS, le K Computer utilise 68 544 processeurs SPARC64 VIIIfx possédant chacun 8 cores, ce qui fait un total de 548 352 cores. Son architecture est aussi originale, parce que le système ne fait pas autant appel aux GPU que les supercalculateurs modernes.

Sa consommation est son principal défaut : à 9 899 kW, elle est deux fois supérieure au Tianhe–1A, alors second au TOP500. Ce point ne s’est pas amélioré lorsque Fujitsu a rajouté un peu moins de 200 000 cores, ce qui a propulsé la consommation au-dessus de la barre des 12 000 kW. Juin 2011 fut un moment symbolique pour les supercalculateurs, puisque pour la première fois toutes les machines du top 10 dépassaient le pétaFlops.
Juin 2012 : Sequoia BlueGene/Q, 1,5 million de coeurs IBM PowerPC !
Le Sequoia BlueGene/Q est le premier supercalculateur à dépasser le million et demi de coeurs CPU. Malgré le fait qu’il ait plus de deux fois le nombre de coeurs que le K Computer, il consomme presque deux fois moins puisqu’il tourne à 7 890 kW.

La machine utilisait des PowerPC à 1,6 GHz pour un résultat convaincant puisque c’est la première fois qu’un supercalculateur dépassait la barre symbolique des 20 PFlops (théoriques). En pratique, le système tournait à 16 PFlops. La machine fut installée dans un des laboratoires nationaux du département américain de l’énergie. Elle est aussi importante, car elle marque le retour des États-Unis à la tête de ce classement.
Novembre 2012 : Cray XK7 (Titan), l’alliance CPU AMD, GPU NVIDIA
En novembre 2012, IBM fut devancé par Cray et son XK7 (Titan) doté de presque 300 000 Opteron 6274 et plus de 260 000 K20x de NVIDIA. Il marque le retour d’AMD en haut de l’affiche depuis le dernier supercalculateur Jaguar 3.0 qui dominait le tableau en juin 2010.

Il n’a pas dépassé le BlueGene/Q de beaucoup puisque sa puissance pratique tournait à 17,6 PFlops et il consommait un peu plus à 8 209 kW. Il fut installé dans le laboratoire national Oak Ridge du département américain de l’énergie. Autre événement du TOP500 de novembre 2012, l’entrée des Xeon Phi dans le top 10.
2012 en France : Zumbrota, EDF (BlueGene/Q)
Le supercalculateur Zumbrota d’EDF est arrivé en 30e place en juin 2012 lors de sa mise en route. Zumbrota est basé sur un supercalculateur BlueGene/Q d’IBM, il utilise donc les mêmes processeurs PowerPC A2 cadencés à 1,6 GHz que le Sequoia.

Avec ses 4096 processeurs dotés de 16 cores (18 plus exactement, mais un core est dédié au système d’exploitation, et un core est utilisé comme « spare » ), soit un total de 65536 cores, Zumbrota affiche une puissance théorique de 839 TFlops. En pratique, la puissance dépasse 715 TFlops, pour une consommation culminant à 328,75 kW. Sans surprise, le Zumbrota fonctionne sous Linux.
Ce supercalculateur a est utilisé – entre autres – par le département Matériaux et Mécanique des Composants d’EDF pour l’étude et la modélisation des mécanismes de vieillissement des matériaux aux côtés d’Ivanoé, le précédent supercalculateur d’EDF, inauguré en 2010 et transféré en 2016 à l’Université Pierre et Marie Curie. Zumbrota a de son côté quitté le Top 500 à la fin de l’année 2018.
2012 en France : Turing, CNRS (BlueGene/Q)
Également basé sur un supercalculateur BlueGene/Q d’IBM et par conséquent équipé des mêmes processeurs PowerPC A2 cadencés à 1,6 GHz que le Sequoia et le Zumbrota, le Turing est utilisé par le CNRS. Il est installé à l’IDRIS (l’Institut du développement et des ressources en informatique Scientifique, l’un des centres nationaux de calcul).

À sa mise en fonction, il atteignait la 29e place du TOP500 avec une puissance théorique de 838,9 TFlops et une puissance pratique de 690,2 TFlops. À l’époque, il était équipé de 4096 processeurs, soit 65536 cores (et une consommation de 328,75 kW). Mis à jour en 2014, le supercalculateur Turing est désormais équipé de 6144 processeurs, soit un total de 98304 coeurs, accompagnés par 96 To de mémoire et 2,2 Po d’espace de stockage (partagés avec le supercalculateur Ada). Il atteint maintenant une puissance théorique de 1258 TFlops et une puissance pratique de 1073 TFlops.
2012 en France : Curie Thin nodes, CEA (Bullx B510)
Aux côtés du Tera-100, le CEA utilise un autre supercalculateur conçu par Bull sur une base de Bullx B510 : Curie Thin nodes. Regroupant 5040 nœuds Bullx B510, soit un total de 9648 processeurs octo-cores Xeon E5-2680 (Sandy Bridge-EP) cadencés à 2,7 GHz, le Curie Thin nodes affiche une puissance théorique de 1,667 PFlops et atteint une puissance pratique de 1,359 PFlops, pour une consommation de 2,25 MW. Ces performances lui permettent de prendre la neuvième place du TOP500 en juin 2012. Trois ans plus tard, il n’est plus « que » 44e de ce même classement.

Curie Thin nodes fonctionne sous Bullx SUperCOmputer Suite A.E.2.1 et utilise la bibliothèque Intel Math Kernel. Ce supercalculateur est en effet dédié au passage de codes parallèles MPI. Bien qu’utilisé et hébergé par le CEA au TGCC (Très grand Centre de Calcul), Curie Thin nodes appartient à la société civile GENCI (Grand Equipement National de Calcul Intensif).
Juin 2013 : Tianhe-2 (MilkyWay-2) explose le record avec du Xeon Phi
En juin 2013, la Chine explose tous les records. Pour la première fois, le Tianhe-2 dépasse les 50 PFlops théoriques avec une puissance de 54,9 PFlops. Il atteint en pratique 33,8 PFlops, ce qui est presque deux fois plus que le XK7 de Cray.

Pour arriver à ses fins, il utilise 3,12 millions de cores (deux fois plus que le K Computer de Fujitsu qui détenait le record). Cela signifie aussi que le système demande 17 808 kW, ce qui est deux fois plus que le XK7 et 5 000 kW de plus que le K Computer. Installée dans le centre national de Guangzho, la machine a surpris tout le monde en arrivant deux ans plus tôt que prévu. Chaque noeud utilise deux Xeon E5–2692 de 12 cores à 2,2 GHz et trois Xeon Phi 31S1P, ce qui explique le nombre impressionnant de cores.
2013 en France : Pangea, Total Exploration Production (SGI ICE X)
À cette époque, le supercalculateur français le plus puissant se nomme Pangea. Onzième supercalculateur le plus puissant au monde en juin 2013, il était tombé à la 29e place du TOP500 avant de doubler en taille – il s’accroche aujourd’hui à la 19e place. Utilisé par Total Exploration Production comme un outil d’aide à la décision pour l’exploration de zones géologiques complexes et pour accroître l’efficacité de la production d’hydrocarbures, il repose sur une base SGI ICE X et affiche aujourd’hui une puissance théorique de 6,712 PFlops (soit trois fois sa puissance initiale), pour une puissance réelle atteignant 5,283 PFlops.

La première moitié de Pangea se compose de 13800 processeurs Xeon E5-2670 (octo-cores cadencés à 2,6 GHz). La seconde moitié, mise en service en début d’année comprend 9200 Xeon E5-2680 v3 (dodécacoeurs, à 2,5 GHz). Au total, Total dispose de 220 800 coeurs CPU, accompagnés par un total de 54 To de mémoire et 26 Po d’espace de stockage. L’ensemble consomme près de 4,5 MW.
2014 en France : OCCIGEN, CINES (Bullx DLC)
Utilisé par le Centre Informatique National de l’Enseignement Supérieur mais propriété du Grand Equipement National de Calcul Intensif, le supercalculateur OCCIGEN est en fonction depuis le deuxième semestre 2014. Il prend la succession de JADE.

Arrivé à la 26e place du TOP500 grâce à ses 4212 processeurs Xeon E5-2690v3 (12 cores par processeur Haswell, soit un total de 50544 cores) cadencés à 2,6 GHz et répartis en 2106 nœuds de calcul, OCCIGEN développe une puissance théorique de 2,1 PFlops, pour une puissance pratique de 1,63 PFlops. Fonctionnant sous Redhat Enterprise Linux 6.4, OCCIGEN consomme « seulement » 935 kW. Il est destiné aux simulations diverses dans des domaines comme la climatologie, la combustion, l’astrophysique, la chimie quantique, la médecine et la biologie, la physique des plasmas ou encore la science des matériaux.
Près de 48 000 cores pour le nouveau calculateur de Météo France
Juin 2016 : la Chine largement battue par… la Chine !
Après trois ans de domination le supercalculateur chinois Tianhe-2 a enfin perdu sa première place au TOP500. Il a été détrôné par un compatriote, Sunway TaihuLight.

Ce nouveau supercalculateur chinois est extraordinaire a plus d’un titre. D’abord parce qu’il développe 125 PFlops de puissance brute et 93 PFlops en pratique sous Linpack. C’est presque trois fois plus que le Tianhe-2. Son rendement est de 6 GFlops/W, ce qui le place parmi les meilleurs supercalculateurs au monde sur ce critère.
De manière remarquable, ces excellents résultats sont obtenus par des processeurs entièrement conçus et fabriqués en Chine. Le Sunway TaihuLight compte 40960 processeurs ShenWei SW26010, chacun dotés de 260 cœurs RISC 64 bits à 1,45 GHz – soit tout de même 10,6 millions de coeurs. En 2022, il est toujours dans le Top 10 des plus puissants supercalculateurs.
Juin 2017 : Piz Daint, la Suisse sort les USA du top 3 !
Le podium est toujours dominé par Sunway TaihuLight et Tianhe-2, mais un outsider fait une entrée fracassante en 3e position : le suisse Piz Daint. Cette très grosse calculette est de type hybride. Ses 5320 noeuds Cray XC50, sont chacun équipé de deux CPU Intel Xeon E5-2690 v3 (Haswell, 12 coeurs, 24 Threads, 3,5 GHz max.) et d’un GPU Nvidia Tesla P100. Avec 19,6 TFlops sous Linpack, Piz Daint devient alors le supercalculateur hybride le plus rapide du monde.

À sa puissance maximale, le Piz Daint n’utilise que 2,3 MW. Il délivre donc une efficacité record pour une machine de cette taille (8,6 GFlops/W). Piz Daint a relégué en quatrième position le Titan américain, lui aussi un hybride, et c’est la première fois depuis 1996 que les USA sont évincés du top 3. Toutefois, deux systèmes américains dépassant les 100 PFlops sont attendus à ce moment là : Summit et Sierra. Ces deux monstres seront également des hybrides, basés sur des CPU IBM Power9 et des GPU Nvidia V100 (Volta).
2017 en France : Tera 1000, 25 PFlops français
Depuis la fin 2015, une nouvelle machine est installée au CEA : le Tera 1000. Au début, seule la première tranche a été installée, le Tera 1000-1. Elle comprend deux sous-systèmes : le premier à base de processeurs Intel Xeon E5 v3, le second à base de processeurs Intel Xeon Phi.

Le Tera 1000-1 compte 4392 CPU Intel Xeon E5-2698v3 (16 coeurs, 2,3 GHz) et atteint 1,871 PFlops sous Linpack. Il offre ainsi presque le double de puissance du Tera 100, pour une consommation divisée par 4,5. Le Tera 1000-1 hybrid fut testé dans une configuration provisoire réunissant des Xeon E5 2698v3 et cartes Nvidia Tesla K80 pour une puissance de calcul de 293 TFlops seulement. Une fois équipé de ses milliers de Xeon Phi 7250 68C, le Tera 1000-1 atteint 23,4 PFlops, ce qui lui a permis de se hisser en 2018 à la quatorzième place du Top 500.
Juin 2018 : Summit, les USA reviennent en tête avec IBM et NVIDIA
Il aura fallu deux ans aux Etats-Unis pour reprendre la tête face au monstre chinois Sunway TaihuLight et ses 10 millions de coeurs. Le premier supercalculateur Sierra le surpasse de très peu (125 PFlops), mais le second, nommé Summit, culmine en cassant une nouvelle barre : 200 PFlops !


Le Summit est armé d’un joli système de refroidissement à eau sur ses CPU IBM POWER9 à 22 coeurs et ses GPU NVIDIA Tesla V100 (GPU Volta). Ces derniers sont surmontés de jolis waterblocks couvrant leur étage d’alimentation, l’énorme GPU et sa RAM HBM. Ces deux supercalculateurs ont les exactement les mêmes composants, mais le Summit en regroupe beaucoup plus : 27 648 GPU et 9216 CPU (soit 202 752 coeurs). Il est par ailleurs le superordinateur offrant l’un des meilleurs rendements du secteur en termes de GFlops/Watts.
2019 en France : Total signe un record national
La machine fait pâle figure face au 200 PFlops du premier du classement 2019, mais elle se hisse tout de même en 11ème position, forte de ses 25 PFlops. Il s’agit du PANGEA III, chez Total, qui sert principalement à la découverte de pétrole par exploration sismique, gérer les risques, et optimiser la production.

Il utilise encore les mêmes composants que les deux plus puissants supercalculateurs de 2019, mais en quantité bien plus modeste : 1116 CPU POWER9 (18 coeurs cette fois), et 3348 GPU Tesla V100.
2020 : le premier champion à base d’ARM
En prennant directement la tête du Top 500 en 2020, le superordinateur japonais Fugaku ne fait pas qu’évincer le Summit américain de sa place de leader. Il embarque en effet des SoC A64FX à 48 coeurs de Fujitsu, ce qui en fait le premier champion du Top 500 à reposer sur une architecture ARM. Il a en particulier été utilisé pour la lutte contre le Covid-19.

©Raysonho (CC BY-SA 4.0)
Ce supercalculateur affiche à son démarrage une puissance de calcul en pic de 513.85 PFLOPS, puis 537 PFLOPS une fois achevé (415 puis 442 PFLOPS dans le bench High Performance Linpack). Grâce à ses 7,63 millions de coeurs, il est presque trois fois plus rapide que le Summit, second de la liste ! Le Fugaku est actuellement installé à l’institut des sciences informatiques avancées RIKEN à Kobe, où il y consomme 29,9 MW.
2022 : la barre de l’ExaFLOPS officiellement franchie
En l’absence de chiffres officiels pour les Sunway Oceanlite et Tianhe-3 chinois, c’est au Frontier que revient l’honneur d’être déclaré le premier supercalculateur à franchir la barre de l’ExaFLOPS. En plus d’une puissance de calcul de 1,102 EFLOPS dans le bench HPL, et même jusqu’à 1,685 EFLOPS en pic, il affiche une efficacité énergétique de 62,68 GFLOPS/watt, ce qui en fait à la fois le plus rapide et le plus économe en énergie au monde.

Installé à l’Oak Ridge Leadership Computing Facility (OLCF), ce superordinateur se compose de 74 modules de 64 unités constituées de deux nœuds HPE Cray EX, chacun d’eux embarquant un processeur EPYC 7A53s (64 cœurs) et quatre GPU Instinct MI250X d’AMD. En tout, Frontier est composé de 37 888 GPU et 606 208 coeurs CPU, pour une consommation de 21,1 MW. Le supercalculateur rencontre toutefois encore quelques soucis de jeunesses.
JUPITER sera le premier supercalculateur européen à atteindre l’exaflops
Une puissance multiplié par 18 millions en 29 ans !
GFlops, TFlops, PFlops, millions de coeurs, kW, MW… depuis le début de ce dossier, nous avons jonglés avec les chiffres, sans forcément se rendre compte de ce qu’ils voulaient dire. La courbe ci-dessous permet de mieux réaliser la fabuleuse progression de la puissance de ces monstres de calculs. Pour la première fois en juin 2019, la totalité des serveurs du TOP 500 dépassait chacun le pétaFLOPS de puissance de calcul, et le supercalculateur le plus puissant du monde a dépassé l’ExaFLOPS en 2022 ! Une belle progression depuis les 59,7 GFlops du CM5/1024…
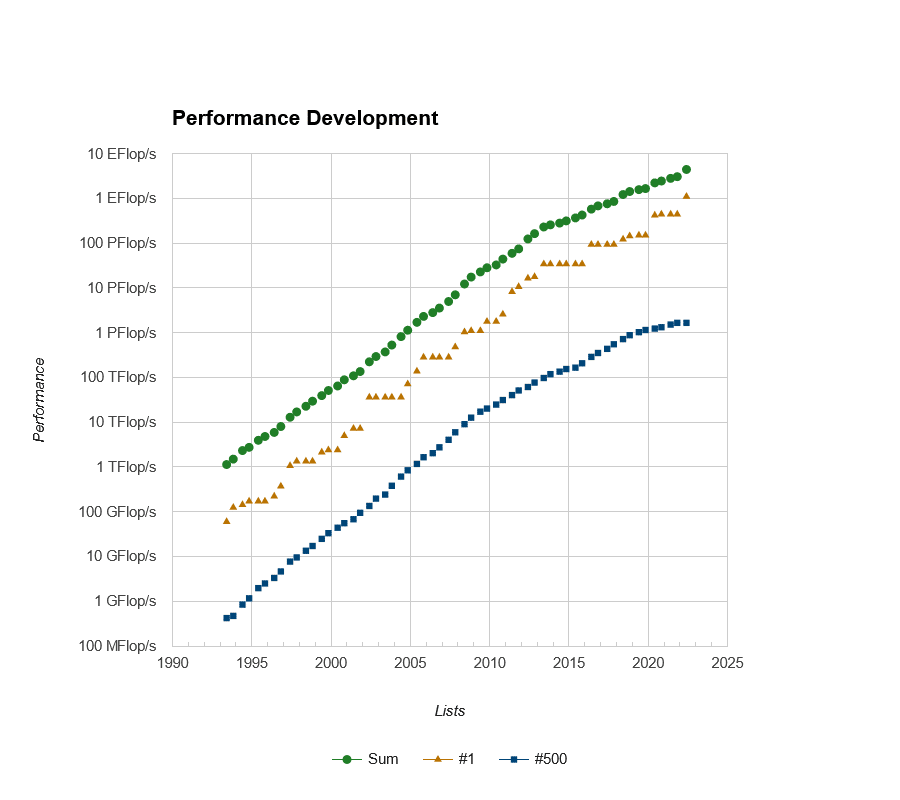
De juin 1993 à juin 2022, la performance réelle des supercalculateurs a été multipliée par 18,4 millions ! Il est frappant de constater à quel point la courbe suit une croissance logarithmique régulière, multipliant par 10 tous les trois ans et demi à peu près. Mais depuis 2014 environ, la progression subit un ralentissement sensible, ce malgré l’arrivée des GPU dans la course. En attendant la prochaine révolution technologique ?
Source : TOP500.org