Introduction
Nous avons beau tester quantité de nouveaux GPU à longueur d’année, certaines architectures parviennent tout de même à nous surprendre. C’était le cas du R300 de la Radeon 9700 Pro en 2002 ou plus proche de nous du G80 de la GeForce 8800 GTX en 2006. Dans les deux cas ces puces étaient à la fois à la pointe de l’innovation en étant les premières à supporter la nouvelle version de l’API 3D de Microsoft, mais en plus elles se révélaient redoutablement efficaces dans les jeux actuels. Dans les deux exemples que nous venons de citer, ces GPU avaient volé la vedette à deux architectures très attendues sur lesquelles les constructeurs avaient largement communiqué : le NV30 (GeForce FX 5800) et le R600 (Radeon HD 2900 XT). Chat échaudé craint l’eau froide, aussi lorsque l’information autour d’un GPU commence à circuler bien avant la disponibilité du produit (on parle de paperlaunch) la méfiance est de mise.
 Les constructeurs l’ont vite compris, particulièrement NVIDIA qui a longtemps été poursuivi par la campagne “Are You Ready ?” et depuis cette époque la firme Californienne a décidé de ne plus réaliser que des hardlaunch (avec plus ou moins de succès). Pourtant lorsque le Cypress (Radeon HD 5800) d’AMD a été présenté, quelle ne fut pas notre surprise de voir NVIDIA en profiter pour dévoiler les premiers éléments sur sa nouvelle architecture baptisée Fermi ! Ce choix de communication s’est avéré à double tranchant, d’un côté il permettait à NVIDIA d’occuper le terrain et de voler un peu la vedette à AMD mais de l’autre il soulignait aussi le fait que bien que le GF100 arrivait et s’annonçait puissant, à l’heure actuelle NVIDIA n’avait rien à proposer en face de la solution d’AMD… et pour un long moment. De plus le fait de choisir comme axe principal de communication CUDA et le GPGPU et de laisser de côté toutes les composantes graphiques de l’architecture n’a pas été bien perçu par la communauté des joueurs qui a vu là un abandon pur et simple de ce marché au profit des supercalulateurs (marché de niche mais aux marges bien plus importantes). Dans son obsession de lutter avec Intel, NVIDIA avait il perdu de vue son marché principal ?
Les constructeurs l’ont vite compris, particulièrement NVIDIA qui a longtemps été poursuivi par la campagne “Are You Ready ?” et depuis cette époque la firme Californienne a décidé de ne plus réaliser que des hardlaunch (avec plus ou moins de succès). Pourtant lorsque le Cypress (Radeon HD 5800) d’AMD a été présenté, quelle ne fut pas notre surprise de voir NVIDIA en profiter pour dévoiler les premiers éléments sur sa nouvelle architecture baptisée Fermi ! Ce choix de communication s’est avéré à double tranchant, d’un côté il permettait à NVIDIA d’occuper le terrain et de voler un peu la vedette à AMD mais de l’autre il soulignait aussi le fait que bien que le GF100 arrivait et s’annonçait puissant, à l’heure actuelle NVIDIA n’avait rien à proposer en face de la solution d’AMD… et pour un long moment. De plus le fait de choisir comme axe principal de communication CUDA et le GPGPU et de laisser de côté toutes les composantes graphiques de l’architecture n’a pas été bien perçu par la communauté des joueurs qui a vu là un abandon pur et simple de ce marché au profit des supercalulateurs (marché de niche mais aux marges bien plus importantes). Dans son obsession de lutter avec Intel, NVIDIA avait il perdu de vue son marché principal ?
Non bien sûr, au final ces craintes n’étaient pas fondées et NVIDIA a rectifié le tir en donnant des détails sur l’architecture graphique quelques mois plus tard. Mais le hardware n’était toujours pas disponible et ces retards commençaient à inquiéter. De plus les déboires de TSMC avec le Cypress n’encourageaient pas à l’optimisme sur les yields du GF100, GPU encore plus gros et plus complexe que son concurrent. De nombreux nuages s’accumulaient donc au dessus du GF100 et certains oiseaux de mauvais augure annonçaient déjà un ratage dans des proportions dignes du NV30. NVIDIA allait-il déjouer les pronostics et nous surprendre ? C’est ce que nous allons voir.
GF100 : une vue d’ensemble
Un simple coup d’oeil au diagramme du GF100 permet de mesurer l’ampleur de modifications apportées par rapport au GT200.
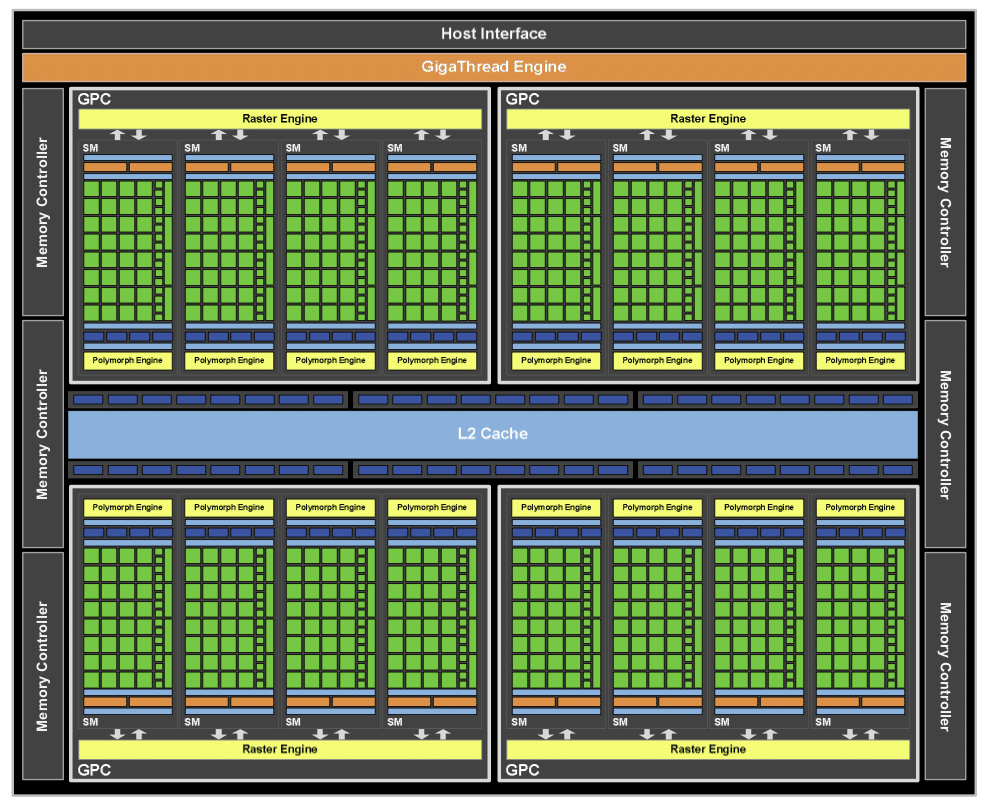
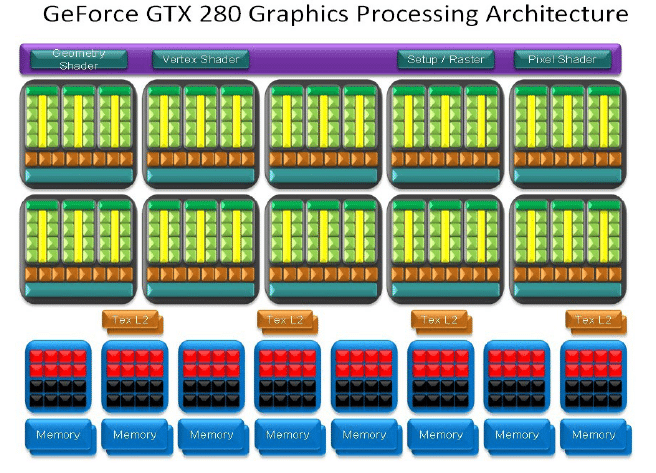
Sur le diagramme du GT200 on observe ainsi d’une part un ensemble de fonctions partagées par tout le GPU comme notamment le setup engine et d’autre part un ensemble d’unités de calculs : le Streaming Processors Array. A l’inverse sur le GF100 on peut distinguer 4 gros blocs : les Graphics Processing Cluster (GPC), et chaque GPC est largement indépendant.
Autre point remarquable la présence d’une large mémoire cache de niveau 2 partagée par l’ensemble du GPU. Intéressons nous maintenant aux caractéristiques des deux nouvelles cartes proposées par NVIDIA :
| GeForce GTX 480 | GeForce GTX 470 | |
| Fréquence GPU | 700 MHz | 607 MHz |
| Fréquence ALU | 1401 MHz | 1215 MHz |
| Fréquence RAM | 924 MHz | 837 MHz |
| ALU | 480 | 448 |
| Unités de textures | 60 | 56 |
| ROP (Raster OPeration unit) | 48 | 40 |
| Contrôleur mémoire | 384 bits (6 x 64 bits) | 320 bits (5 x 64 bits) |
| Type de RAM | GDDR5 | GDDR5 |
Première mauvaise surprise : le nombre d’ALU. Alors qu’au mois d’octobre, lors de la première présentation de l’architecture Fermi, NVIDIA nous parlait de 512 “cuda cores” il faudra au final se contenter de 480 unités sur le nouveau haut de gamme de la famille GeForce, la GTX 480. NVIDIA avait pris ses précautions, précisant que Fermi était une architecture et en aucun cas la description d’une implémentation spécifique, de plus les documents précisaient bien jusqu’à 512 cores. Enfin en décembre dernier les premiers détails sur les cartes Tesla dérivées de l’architecture Fermi nous avaient là aussi préparé à voir des unités désactivées, mais malgré tout beaucoup seront déçus. On pouvait en effet s’attendre à ce que NVIDIA ait pris des marges conservatrices sur sa gamme Fermi mais soit plus ambitieux avec le marché graphique où la concurrence est rude.
Si l’on prends en compte la fréquence finale de ces cores on obtient donc une puissance de calculs de 1,344 TFlops dans le cas de l’utilisation de FMA (Fused Multiply-Add) contre 2,72 TFlops pour le Cypress. Il faut toutefois relativiser ce résultat en rappelant que la puissance de calculs ne fait pas tout dans un GPU : ce n’est qu’un facteur parmi de nombreux autres. Le GT200 était déjà plus faible à ce niveau que le RV770 ce qui ne l’empêchait pas de dominer ce dernier dans la plupart des jeux. L’architecture d’AMD est en effet moins flexible que celle de NVIDIA dans sa façon de traiter les instructions en parallèle, elle repose sur des unités VLIW qui nécessitent un compilateur performant pour extraire le parallélisme. En contrepartie AMD est en mesure de proposer un nombre d’unités de calculs très important.
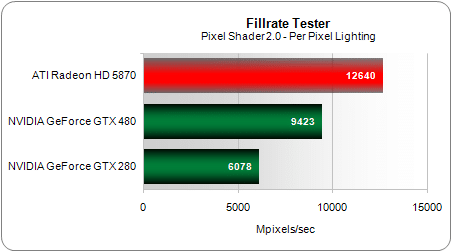
Concernant la fréquence des ALU là aussi petite déception : celle-ci est revue à la baisse par rapport à la GTX 285, avec 1401 MHz contre 1476 MHz pour le précédent haut de gamme de NVIDIA. En revanche la fréquence GPU a augmentée passant de 648MHz à 700MHz. Si nous avons largement critiqué à plusieurs reprises AMD pour ses augmentations trop modestes du nombre d’unités de texture et de ROP nous n’avions jusqu’ici jamais eu à nous plaindre de NVIDIA. Pourtant avec le GF100, pour la première fois un nouveau GPU de NVIDIA se retrouve avec moins d’unités de textures que le précédent : 60 contre 80. En pratique toutefois ces unités ont été remaniées notamment au niveau du sous-système mémoire et elles sont également cadencées plus rapidement. Mais malgré tout dans certains tests spécifiques cette différence devrait avoir un impact notable. Vérifions le par exemple via un simple test de quad texturing :
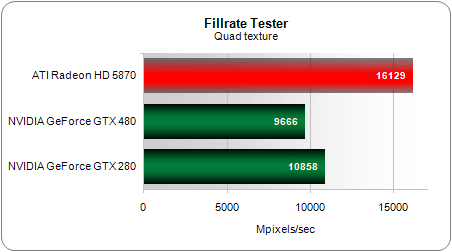
Ici l’écart entre la GeForce GTX 480 et la GeForce GTX 280 atteint -11 %, ce qui confirme la théorie. Sur ce test très simple, la Radeon HD 5870 s’avère également 67 % plus puissante que la nouvelle carte NVIDIA. Nous allons toutefois revenir sur ce point plus loin.
Pas de mauvaise surprise au niveau des ROP en revanche, si l’utilisation d’un bus 384 bits contre 512 bits sur le GT200 laissait craindre là encore une diminution du nombre d’unités, NVIDIA a plus que compensé le problème en doublant le nombre de ROP par partition. Ainsi le GT200 disposait de 8 partitions de 4 ROP chacune, alors que désormais le GF100 se voit équipé de 6 partitions de 8 ROP chacune pour un total de 48 ROP donc, ce qui permet à NVIDIA de reprendre l’avantage sur AMD qui venait tout juste de le rattraper à ce niveau avec le Cypress.
L’architecture en détail
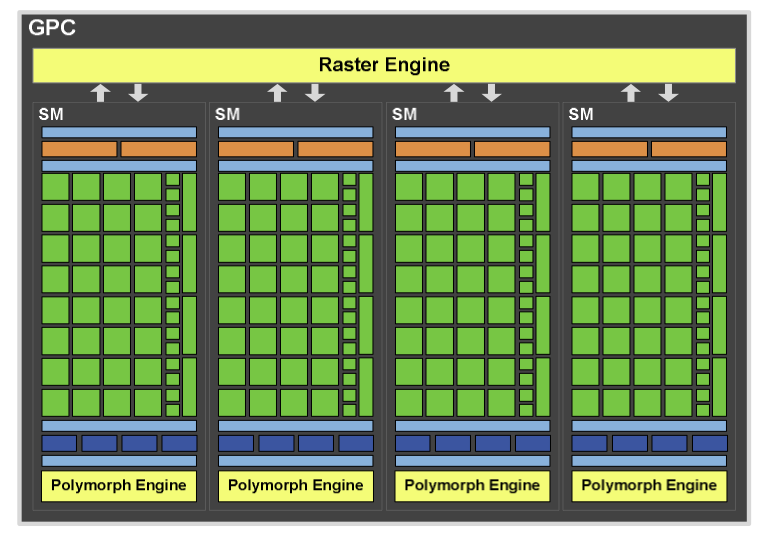
Si AMD avait pu se contenter de quelques retouches avec son RV870, NVIDIA a pour sa part du changer radicalement son architecture introduite avec le G80 il y a plus de 3 ans et qui était désormais en fin de cycle. L’organisation des différentes unités a été complètement remaniée.Ainsi le GT200 offrait ce que NVIDIA appelle des TPC (Texture Processor Cluster) qui étaient constitués d’une unité de textures et de 3 unités de calculs : les Streaming Multiprocessor. Si NVIDIA conserve le terme de Streaming Multiprocessor avec le GF100, ces derniers sont désormais beaucoup plus puissants.
Les Streaming Multiprocessors
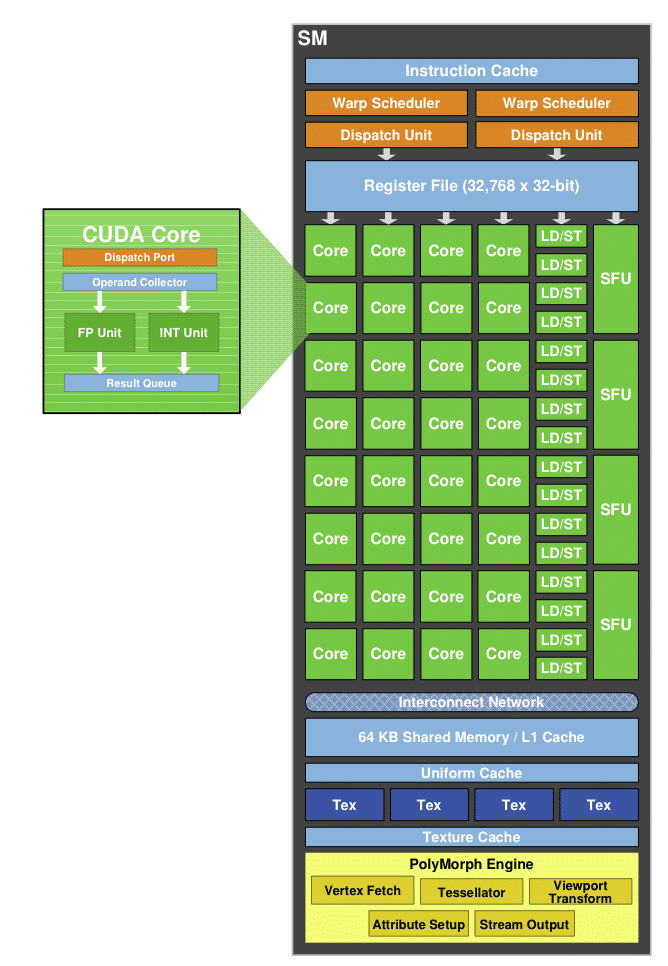 Alors que sur le GT200 un Streaming Multiprocessor était constitué d’une unité SIMD 8 voies, de deux unités spécialeset d’une unité double précision, sur le GF100 il est désormais équipé de deux unités SIMD 16 voies et de quatre unités spéciales. Il n’y a donc plus d’unité de calculs dédiée spécifiquement à la double précision, les calculs FP64 étant désormais effectués par les mêmes unités à un débit deux fois moins élevé.
Alors que sur le GT200 un Streaming Multiprocessor était constitué d’une unité SIMD 8 voies, de deux unités spécialeset d’une unité double précision, sur le GF100 il est désormais équipé de deux unités SIMD 16 voies et de quatre unités spéciales. Il n’y a donc plus d’unité de calculs dédiée spécifiquement à la double précision, les calculs FP64 étant désormais effectués par les mêmes unités à un débit deux fois moins élevé.
L’augmentation de la puissance de calcul n’est pas la modification la plus notable, en effet désormais les unités de texture sont directement implémentées dans le SM alors qu’auparavant elles étaient découplées : 3 SM partageant huit unités de texture. Sur le GF100 chaque multiprocesseur dispose de ses 4 propres unités de texture ce qui explique également pourquoi leur nombre global a diminué par rapport à l’architecture précédente (8 unités par TPC sur le GT200 soit 80 en tout, contre 4 unités par SM sur le GF100 soit 60 sur la GTX 480). Autre nouveauté : l’apparition de 16 unités de chargement/rangement (load/store) permettant de calculer des adresses en mémoire cache ou en RAM pour 16 threads à chaque cycle.
Concrètement cette réorganisation permet à NVIDIA de proposer une architecture beaucoup plus élégante et plus efficace que la précédente, désormais les SM sont vraiment des processeurs indépendants alors qu’auparavant ils reposaient sur un sous-système mémoire partagé par groupe de 3 SM.
La taille du fichier de registres a également augmenté. Ainsi de 16 384 registres 32 bits par multiprocesseur on passe désormais à 32 768, dans le même temps le nombre de threads actifs par multiprocesseur a également augmenté par rapport au GT200, de 1024 threads (24 warps de 32 threads) on passe désormais à 1536 (48 warps de 32 threads). Le nombre de registres disponibles par threads est donc désormais de 21 contre 16 auparavant (et 10 sur le G80). Vérifions maintenant l’augmentation de cette puissance de calculs via quelques shaders.
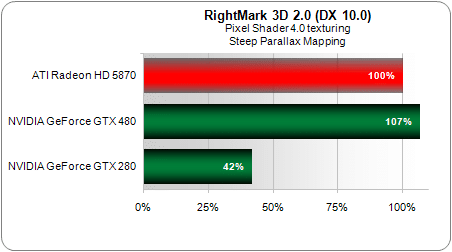
Sur un shader désormais très simple d’éclairage par pixel de niveau DirectX9, la dernière carte de NVIDIA s’avère 55 % plus performante que la GeForce GTX 280. Cet écart grimpe toutefois à 82 % avec un shader plus lourd de textures procédurales :
Dual Scheduler, unités de texture
Dual Scheduler
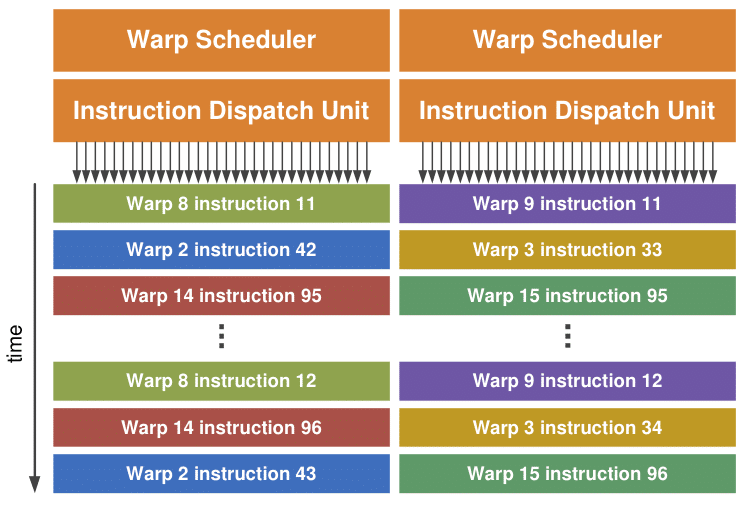
Depuis l’apparition du G80 NVIDIA affirme que ses multiprocesseurs sont capables d’exécuter deux instructions par cycle dans certaines circonstances : un MUL et un MAD, cette capacité était impossible à isoler sur les premières versions de l’architecture et même sur le GT200 elle restait particulièrement délicate à mettre en avant. En pratique le fameux dual-issue tant vanté par NVIDIA n’était pas observable et le chip ne pouvait exécuter qu’un MAD par cycle.
Tout ceci n’a plus beaucoup d’importance car aujourd’hui NVIDIA propose avec le GF100 deux schedulers permettant l’exécution de deux instructions par cycle et sans les contraintes qui bridaient ses architectures précédentes. Comme nous l’avons vu, les 32 unités de calcul de chaque multiprocesseur sont en fait arrangées en deux groupes de 16 unités et chacun de ces groupes peut exécuter une instruction indépendante. L’histoire des CPU récents nous a prouvé que l’exécution superscalaire est particulièrement complexe à mettre en oeuvre mais NVIDIA dispose d’un avantage de taille à ce niveau : le GF100 ne tente pas d’extraire du parallélisme d’un seul flux d’instructions, avec tous les aléas que ça implique. Le multiprocesseur sélectionne en fait deux warps et lance l’exécution d’une instruction de chacun d’entre eux sur les unités SIMD. Les warps étant totalement indépendants ils peuvent être exécutés en parallèle sans aucun risque.
La plupart des instructions peuvent être exécutés simultanément qu’il s’agisse d’instructions de calculs FP32, d’entiers ou de chargement/rangement. La seule exception à la règle concerne les instructions de calculs double précision qui réquisitionnent l’ensemble des 32 unités de calculs et ne peuvent être exécutées simultanément avec aucun autre type d’instructions.
Unités de texture
Si le nombre d’unités de textures a diminué, NVIDIA a profité de sa nouvelle architecture pour revoir complètement leur design afin d’améliorer leurs performances. Comme nous l’avons indiqué ces dernières sont désormais intégrées aux multiprocesseurs ce qui évite de devoir les partager entre plusieurs multiprocesseurs avec toutes les pertes d’efficacité que cela implique. Le cache de niveau 1 dédié aux unités de texture a également été revu, même si sa taille reste inchangé par rapport au GT200 (12Ko) NVIDIA annonce que celui-ci est désormais nettement plus efficace. Enfin les unités de texture sont désormais cadencées à la fréquence du GPU alors qu’auparavant elles fonctionnaient dans un domaine de fréquence plus faible.
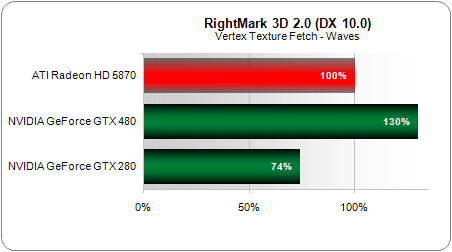
Résultat : sur ce test qui mesure les performances d’accès aux textures (utile pour le displacement mapping notamment), la GeForce GTX 480 s’avère 75 % plus efficace que la GTX 280.
Évidemment les nouvelles unités supportent les nouveaux formats de compression BC6H et BC7H ainsi que les instructions de Gather requises par Direct3D 11. Au final les performances augmentent bel et bien avec des pixel shaders plus contemporains, même s’il s’agit plus d’un rattrapage à ce niveau…
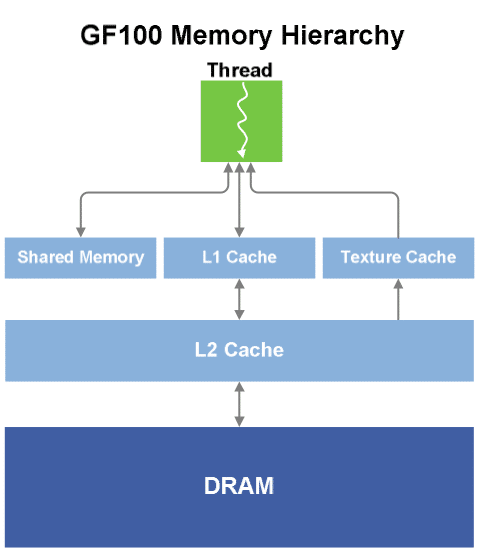
Une hiérarchie mémoire digne d’un CPU
Pendant longtemps le sous-système mémoire a été le parent pauvre des GPU.Il faut dire que les accès mémoires des premiers GPU étaient tellement simples qu’une hiérarchie mémoire n’avait pas vraiment sa place : un simple cache de texture et un petit cache de sommets (pre et post transformation) et le tour était joué. Avec l’avènement du GPGPU les choses se sont nettement complexifiées et un sous-système mémoire aussi basique ne faisait plus l’affaire.
Pour répondre à ces nouvelles exigences NVIDIA avait introduit la Shared Memory avec son G80. La Shared Memory est une petite zone de mémoire extrêmement rapide intégrée à chaque multiprocesseur et permettant de partager des données entre les threads. Bien que l’utilisation de cette zone mémoire était totalement à la charge du programmeur et demandait donc un effort supplémentaire, le concept a été bien accueilli et s’est d’ailleurs retrouvé dans les GPU AMD qui ont suivi.Finalement Microsoft l’a intégré à Direct3D 11 et Khronos a OpenCL.
 Mais si ce genre de mémoire gérée manuellement par le programmeur offre d’excellentes performances dans les algorithmes ayant des accès mémoires bien prédictibles, elle ne peut en revanche pas supplanter une mémoire cache dés lors que les accès mémoires sont irréguliers. Avec le GF100 NVIDIA tente donc de combiner le meilleur des deux mondes en proposant une zone mémoire de 64 Ko par multiprocesseur. Cette zone mémoire peut être configurée de deux façons différentes :
Mais si ce genre de mémoire gérée manuellement par le programmeur offre d’excellentes performances dans les algorithmes ayant des accès mémoires bien prédictibles, elle ne peut en revanche pas supplanter une mémoire cache dés lors que les accès mémoires sont irréguliers. Avec le GF100 NVIDIA tente donc de combiner le meilleur des deux mondes en proposant une zone mémoire de 64 Ko par multiprocesseur. Cette zone mémoire peut être configurée de deux façons différentes :
- 16Ko de cache L1 et 48Ko de Shared Memory
- 48Ko de cache L1 et 16Ko de Shared Memory
Ce cache L1 peut être utilisé comme un buffer pour sauvegarder les registres lorsque ceux-ci viennent à manquer, ce qui n’est pas un mal car si leur nombre a augmenté par rapport au GT200 comme nous l’avons vu, l’augmentation ne s’est pas faite dans la même proportion que celle du nombre d’unités de calculs.
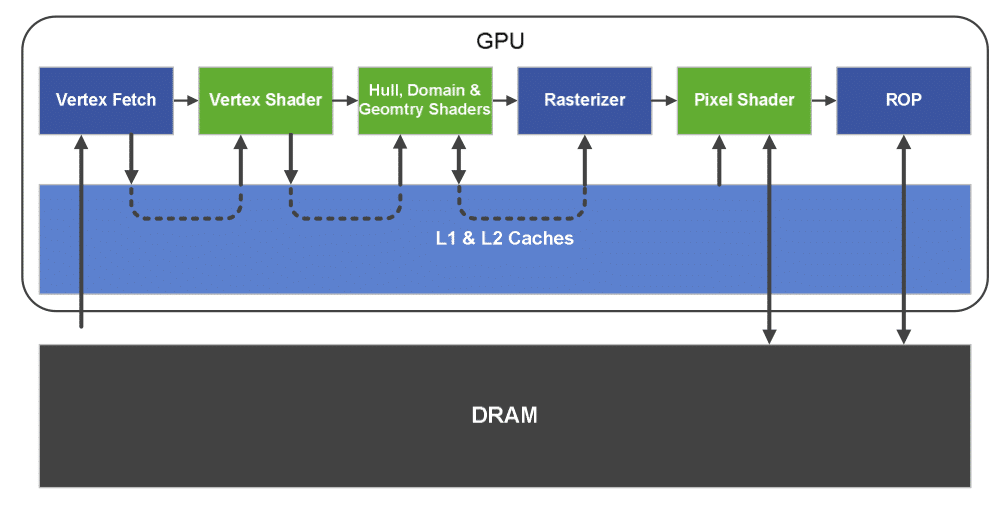 Mais ce n’est pas tout, comme nous l’avons vu plus haut NVIDIA a également ajouté une véritable mémoire cache de niveau 2 à son GPU. En effet le GT200 contenait déjà un cache de niveau 2 de 256Ko mais celui-ci n’était accessible qu’en lecture et uniquement par les unités de texture. Avec le GF100 NVIDIA a dôté son GPU d’un cache de niveau 2 généraliste c’est à dire accessible en lecture/écriture aussi bien aux instructions de texture qu’aux instructions de chargement/rangement. Ce cache remplace également le cache des ROP mais aussi les pre et post vertex transform cache des GPU précédents. Le cache de texture de niveau 1 de par son fonctionnement un peu particulier reste toutefois présent et conserve la même taille que sur le GT200 : 12Ko.
Mais ce n’est pas tout, comme nous l’avons vu plus haut NVIDIA a également ajouté une véritable mémoire cache de niveau 2 à son GPU. En effet le GT200 contenait déjà un cache de niveau 2 de 256Ko mais celui-ci n’était accessible qu’en lecture et uniquement par les unités de texture. Avec le GF100 NVIDIA a dôté son GPU d’un cache de niveau 2 généraliste c’est à dire accessible en lecture/écriture aussi bien aux instructions de texture qu’aux instructions de chargement/rangement. Ce cache remplace également le cache des ROP mais aussi les pre et post vertex transform cache des GPU précédents. Le cache de texture de niveau 1 de par son fonctionnement un peu particulier reste toutefois présent et conserve la même taille que sur le GT200 : 12Ko.
Setup engine et tesselation
Un setup engine enfin parallélisé !
Enfin la limite du triangle généré par cycle a été abolie ! Nous attendions ça depuis longtemps, en fait depuis l’avènement des architectures unifiées grâce auxquelles la puissance géométrique avait connu un véritable bond en avant. L’espace d’un instant nous avions même pensé que le RV870 avait ouvert la voie mais la déception n’en fut que plus grande. Aujourd’hui pourtant NVIDIA a répondu à nos attentes en multipliant le nombre d’unités de setup, et la firme Californienne n’a pas fait les choses à moitié car on ne retrouve pas seulement deux rasterizers mais quatre !
C’est là que le nouvelle organisation des unités prends tout son sens. En effet comme nous l’avions indiqué chaque GPC contient la plupart des fonctions d’un GPU (à part les ROP) et peut donc fonctionner de façon indépendante. Cela signifie donc que chaque GPC dispose de sa propre unité de setup qui peut rastériser un triangle à chaque cycle (à raison de 8 pixels par cycle). En pratique la performance de crête reste donc inchangée : on parle toujours de 32 pixels générés à chaque cycle comme sur le GT200 ou sur le RV870 mais l’efficacité de la nouvelle architecture sera visible lors de l’utilisation de nombreux petits triangles.
NVIDIA, dont le département marketing n’est jamais en reste pour nous inventer des noms exotiques, regroupe l’ensemble des opérations effectuées sur les sommets au sein d’un GPC sous le nom de PolyMorph Engine.
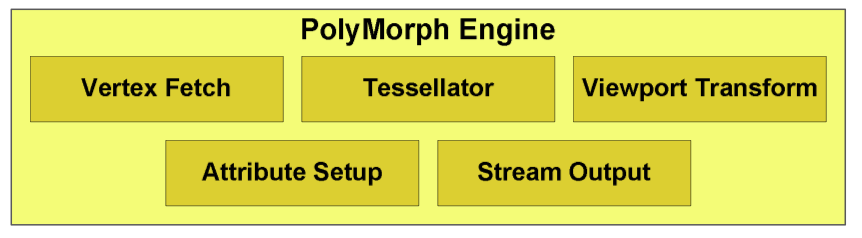 Le pipeline géométrique est donc le suivant : les sommets sont récupérés depuis un buffer puis passé aux multiprocesseurs qui effectuent le vertex shading. Le résultat est ensuite passé à l’étape suivante du PolyMorph Engine : le tesselator qui n’est pour sa part pas directement programmable mais dont le fonctionnement peut être contrôlé par le Hull Shader effectué en amont et le Domain Shader effectué en aval sur les multiprocesseurs.
Le pipeline géométrique est donc le suivant : les sommets sont récupérés depuis un buffer puis passé aux multiprocesseurs qui effectuent le vertex shading. Le résultat est ensuite passé à l’étape suivante du PolyMorph Engine : le tesselator qui n’est pour sa part pas directement programmable mais dont le fonctionnement peut être contrôlé par le Hull Shader effectué en amont et le Domain Shader effectué en aval sur les multiprocesseurs.
 Tesselation
Tesselation
Un petit rappel sur la tesselations’impose à ce niveau. Avec Direct3D 11 Microsoft a introduit trois nouveaux étages à son pipeline graphique (en vert dans l’illustration): le Hull Shader, le Tesselator et le Domain Shader. Contrairement aux autres étapes du pipeline ceux-ci ne fonctionnent pas avec des triangles comme primitives mais en utilisant des patchs. Le Hull shader prend donc en entrée les points de contrôle d’un patch, détermine certains paramètres du Tesselator qui est une unité fixe, comme par exemple le TessFactor qui indique la finesse de la tesselation. Le Tesselator est une unité fixe, par conséquent le programmeur ne contrôle pas comment est opéré la tesselation, celui-ci renvoie les points générés au domain shader qui peut appliquer des opérations sur ces derniers.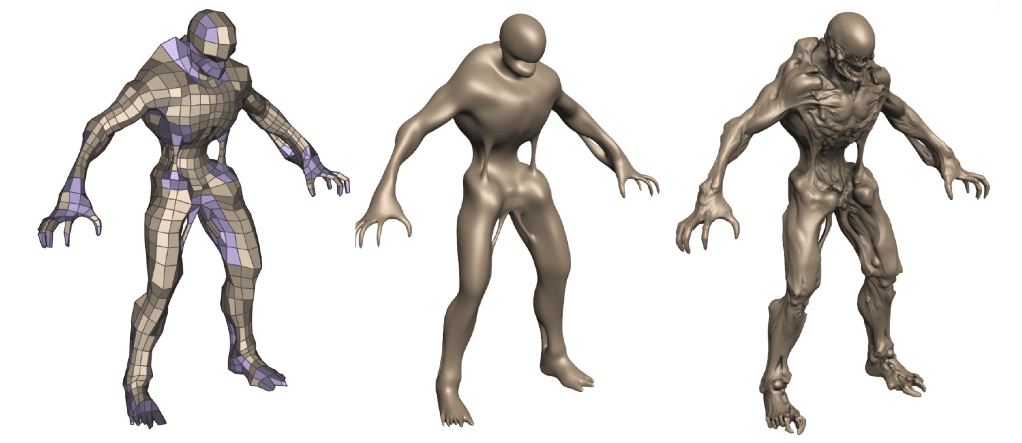 Les avantages de la tesselation sont multiples.Elle permet un stockage particulièrement compact des données géométriques : seuls les points de contrôle du mesh sont stockés en mémoire, les sommets supplémentaires générés restent dans le pipeline graphique, ce qui permet d’économiser de la mémoire et de la bande passante. Autre avantage, la tesselation permet d’utiliser des LOD (niveaux de détails) dynamiques : plus un mesh est près de la caméra, plus il a besoin d’être détaillé.A l’inverse, s’il est loin, utiliser énormément de triangles est non seulement superflu mais cela peut en plus s’avérer extrêmement pénalisant au niveau des performances car les rasterizers et les unités de shading n’apprécient pas les triangles trop petits.
Les avantages de la tesselation sont multiples.Elle permet un stockage particulièrement compact des données géométriques : seuls les points de contrôle du mesh sont stockés en mémoire, les sommets supplémentaires générés restent dans le pipeline graphique, ce qui permet d’économiser de la mémoire et de la bande passante. Autre avantage, la tesselation permet d’utiliser des LOD (niveaux de détails) dynamiques : plus un mesh est près de la caméra, plus il a besoin d’être détaillé.A l’inverse, s’il est loin, utiliser énormément de triangles est non seulement superflu mais cela peut en plus s’avérer extrêmement pénalisant au niveau des performances car les rasterizers et les unités de shading n’apprécient pas les triangles trop petits.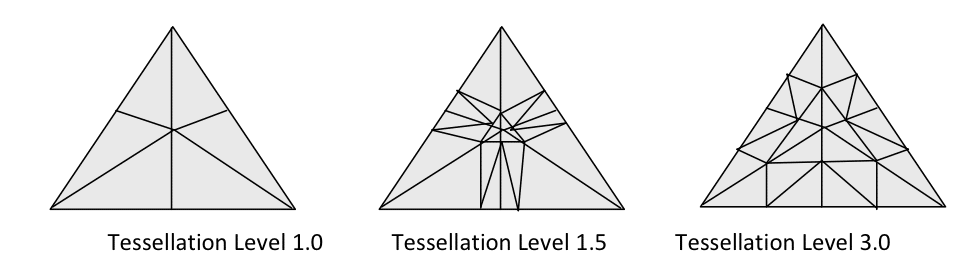 La tesselation a également des avantages en termes d’animation, les données d’animation ne sont nécessaires que pour les points de contrôle (le mesh “grossier” pour simplifier) alors que sur un mesh très complexe elles devraient être disponibles à chaque sommet. Par conséquent les gains effectués à ce niveau peuvent être utilisés en utilisant plus de données d’animation par point de contrôle, améliorant par la même la qualité de l’animation.
La tesselation a également des avantages en termes d’animation, les données d’animation ne sont nécessaires que pour les points de contrôle (le mesh “grossier” pour simplifier) alors que sur un mesh très complexe elles devraient être disponibles à chaque sommet. Par conséquent les gains effectués à ce niveau peuvent être utilisés en utilisant plus de données d’animation par point de contrôle, améliorant par la même la qualité de l’animation.
Toutefois soyons clairs : si Microsoft, AMD et NVIDIA dépeignent tous une situation idyllique, en pratique la tesselation n’est pas un coup de baguette magique qui va automatiquement augmenter le niveau de détails géométriques de nos jeux. Implémenter correctement la tesselation dans un moteur reste complexe et nécessite du travail pour éviter d’observer des artefacts visuels, notamment aux intersections entre deux surfaces ayant des facteurs de tesselation différents.
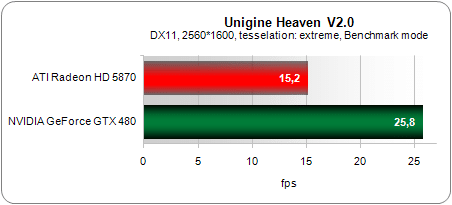
Afin d’évaluer les cartes sur la tesselation, nous avons eut recourt au benchmark Unigine Heaven. La première version, déjà impressionnante visuellement mais assez peu gourmande, fait apparaître de prime abord un faible écart entre les deux cartes.
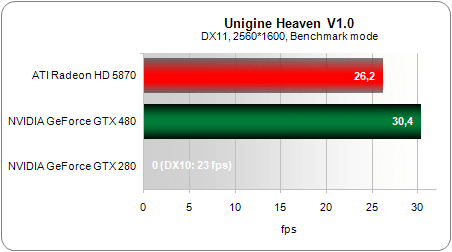
En revanche, la nouvelle version dispose de quelques scènes supplémentaires et surtout d’un nouveau mode faisant un usage bien plus intensif de la tesselation. L’écart grimpe alors à 70 % d’avance pour la GeForce GTX 480 (contre 16 % précédemment) !
Geometry Shader, ROP et antialiasing
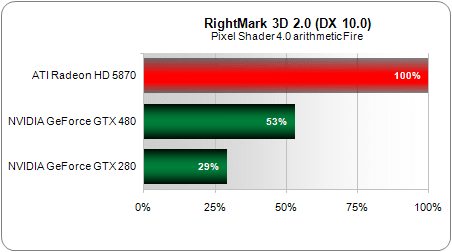
Après ce petit aparthée sur la tesselation reprenons notre cheminement le long du pipeline géométrique.La dernière étape est constituée par le Geometry Shader apparu avec Direct3D 10 et qui permet d’ajouter ou de supprimer des sommets ou des primitives. Ah qu’il est loin le temps du T&L de notre bonne vieille GeForce (10 ans déjà) !
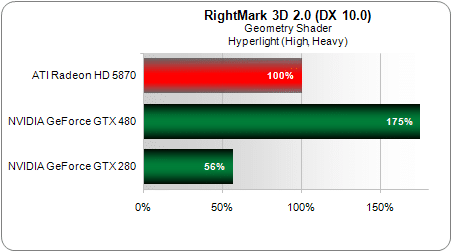
Celui-ci constitue un domaine où la nouvelle GeForce GTX 480 évolue le plus par rapport à l’ancienne architecture, avec pas moins de 311 % de progression sur Hyperlight de RoghtMark 3D !
 En dernier lieu le PolyMorph Engine effectue les calculs de transformation du viewport et de correction de perspective avant de passer les sommets et tous leurs attributs au Raster Engine. Ce dernier est constitué de trois étapes principales : dans un premier temps les équations des arêtes du triangle sont calculées et les triangles qui ne font pas face à la caméra sont rejetés. Enfin le rasterizer génère les pixels (et les samples dans le cas du MSAA) couverts par le triangle avant de passer le tout à l’unité de Z-Cull qui est désormais bien connue et qui permet d’éviter d’effectuer le pixel shading sur des pixels masqués grâce à un ZBuffer hiérarchique.
En dernier lieu le PolyMorph Engine effectue les calculs de transformation du viewport et de correction de perspective avant de passer les sommets et tous leurs attributs au Raster Engine. Ce dernier est constitué de trois étapes principales : dans un premier temps les équations des arêtes du triangle sont calculées et les triangles qui ne font pas face à la caméra sont rejetés. Enfin le rasterizer génère les pixels (et les samples dans le cas du MSAA) couverts par le triangle avant de passer le tout à l’unité de Z-Cull qui est désormais bien connue et qui permet d’éviter d’effectuer le pixel shading sur des pixels masqués grâce à un ZBuffer hiérarchique.
Des ROP remaniés
Comme nous l’avons vu NVIDIA a augmenté le nombre de ROP mais la firme Californienne leur a également apporté plusieurs retouches. Si leurs performances “graphiques” n’ont pas été modifiées (1 pixel int 32 bit par cycle, un pixel fp16 tous les deux cycles et un pixel fp32 tous les quatre cycles) NVIDIA a largement optimisé les opérations atomiques c’est à dire les opérations mémoires effectuées en une seule transaction, sans interruption possible. Ce type d’opération est extrêmement utile en programmation parallèle lorsque plusieurs threads peuvent tenter d’accéder à une même ressource. NVIDIA annonce des gains très importants : jusqu’à 20 fois dans le cas d’opération atomiques à une même adresse et 7,5x dans le cas de régions contigues même si en pratique ces gains résultent probablement plus de l’utilisation du cache L2 pour ce type d’opérations que d’une modification substantielle des ROP.
NVIDIA annonce également une amélioration substantielle de ses algorithmes de compression permettant une meilleure efficacité dans le cadre de l’antialiasing 8x. Enfin signalons l’apparition d’un nouveau mode CSAA 32x et de la possibilité de combiner CSAA et Transparency Multisampling pour améliorer l’antialiasing des surfaces transparentes. Détail intéressant : alors que jusqu’ici le nombre de pixels générés par le setup engine et le nombre de ROP augmentait de concert, ce n’est pas le cas sur le GF100 qui dispose de 48 ROP alors que son rasterizer ne peut générer que 32 pixels par cycle. Si au premier abord ce choix peut s’avérer curieux, en pratique les jeux actuels ne sont plus envisageables sans MSAA et utilisent souvent des frame buffers flottants ce qui impose une charge de travail plus importante sur les ROP qui mettent plusieurs cycles à traiter ces pixels. La présence d’un plus grand nombre de ROP se justifie donc, mais dans certaines passes de rendu très simples ils seront sous exploités par les rasterizers.
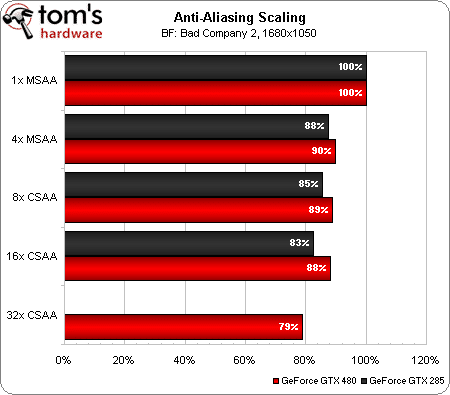
Pour vérifier les performances, nous avons utilisé Battlefield: Bad Company 2 en 1680×1050 (afin de ne pas faire rentrer en jeu la quantité de mémoire supérieure de la GeForce GTX 480). Evidemment, la GeForce GTX 480 est plus rapide que la GTX 285, aussi avons-nous calculé la perte de performance relative pour chaque carte. On constate alors qu’avec un CSAA 16X, le framerate ne baisse que de 12 % sur la GTX 480 (contre 17 % sur la GTX 285). Mieux : même dans le nouveau mode 32X, la perte de performance ne dépasse pas 21 %. Autrement dit, sur la plupart des jeux actuels et à moins que vous ne disposiez d’un moniteur 30 pouces, voilà un bon moyen d’exploiter une partie de la puissance de cette carte graphique (même si suivant le jeu, l’impact pourra être plus important).
Un GPGPU plus qu’un GPU ?
 Difficile de parler du GF100 et de faire l’impasse sur le GPGPU tant NVIDIA a mis l’accent dessus lors de la présentation de sa nouvelle architecture. Lorsque NVIDIA a conçu le G80, le marché GPGPU était encore balbutiant et tout restait à faire. Les choix de la firme Californienne se sont avérés plutôt payants tant d’un point de vue hardware (comme nous avons vu avec la Shared Memory) que software étant donné que les Compute Shader ou OpenCL offrent des paradigmes de programmation proches de CUDA. Mais il est impossible de proposer une solution parfaite du premier coup et NVIDIA a continué à faire évoluer CUDA en ajoutant notamment le support de la double précision et des instructions atomiques avec le GT200. Mais ce n’était que des améliorations incrémentales.Avec Fermi NVIDIA a pu bénéficier de toute l’expertise de plusieurs années de travail avec CUDA pour proposer une solution beaucoup plus puissante.
Difficile de parler du GF100 et de faire l’impasse sur le GPGPU tant NVIDIA a mis l’accent dessus lors de la présentation de sa nouvelle architecture. Lorsque NVIDIA a conçu le G80, le marché GPGPU était encore balbutiant et tout restait à faire. Les choix de la firme Californienne se sont avérés plutôt payants tant d’un point de vue hardware (comme nous avons vu avec la Shared Memory) que software étant donné que les Compute Shader ou OpenCL offrent des paradigmes de programmation proches de CUDA. Mais il est impossible de proposer une solution parfaite du premier coup et NVIDIA a continué à faire évoluer CUDA en ajoutant notamment le support de la double précision et des instructions atomiques avec le GT200. Mais ce n’était que des améliorations incrémentales.Avec Fermi NVIDIA a pu bénéficier de toute l’expertise de plusieurs années de travail avec CUDA pour proposer une solution beaucoup plus puissante.
Premier point largement amélioré avec le GF100 et qui va directement bénéficier aux applications GPGPU : le support de la double précision. Comme nous l’avons vu, l’ajout de la double précision au GT200 ressemblait vraiment à une solution “quick & dirty” pour occuper le terrain : avec une seule unité 64 bits contre huit unités 32 bits, les performances du précédent GPU de NVIDIA en double précision n’étaient vraiment pas à la hauteur. Sans utiliser d’unités dédiées, AMD parvenait même à prendre l’avantage en divisant les performances de son GPU “seulement” par quatre, soit un impact deux fois plus faible que sur l’architecture NVIDIA.
Avec le GF100 NVIDIA a complètement retravaillé son architecture, exit donc l’unité dédiée. Désormais les mêmes unités se chargent des calculs simples et double précision et le débit de ces dernières n’est plus divisé que de moitié. L’impact sur les performances est donc nettement plus raisonnable et comparable à celui observé sur les CPU lors de l’utilisation du SSE, l’avantage des GPU sur ce type de calculs devrait donc être désormais suffisamment intéressant pour motiver les programmeurs à réécrire leurs programmes.
Tant que nous évoquons le sujet des calculs flottants, notez que le GF100 supporte la toute dernière norme IEEE 754-2008 avec tous les modes d’arrondis requis ainsi que l’instruction de multiplication-addition fusionnée (FMAD). Elle maintient la précision du calcul tout du long et n’effectue qu’un seul arrondi final au contraire d’une multiplication-addition (MAD) classique qui effectue deux arrondis. Notons toutefois que son concurrent direct, le RV870, n’est pas en reste à ce niveau car il gère également la dernière norme flottante ainsi que l’instruction FMAD.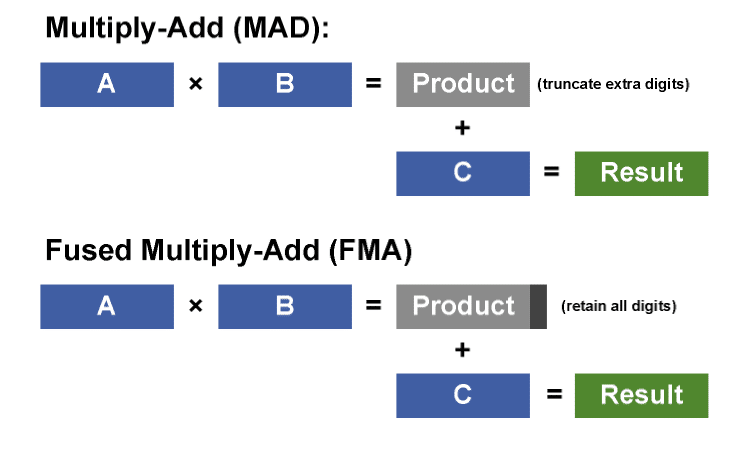 Autre avantage pour le GPGPU que nous avons décrit au-dessus : la nouvelle hiérarchie mémoire.Si dans certains cas une petite “scratchpad RAM” peut faire des miracles, en pratique rien ne remplace parfois une mémoire cache. Notons également que le GF100 offre un support optionnel pour la mémoire ECC, la mémoire à code de correction d’erreur et toutes les mémoires internes du GPU (qu’il s’agisse des caches de niveau 1, niveau 2 ou de la mémoire partagée) sont également protégées.
Autre avantage pour le GPGPU que nous avons décrit au-dessus : la nouvelle hiérarchie mémoire.Si dans certains cas une petite “scratchpad RAM” peut faire des miracles, en pratique rien ne remplace parfois une mémoire cache. Notons également que le GF100 offre un support optionnel pour la mémoire ECC, la mémoire à code de correction d’erreur et toutes les mémoires internes du GPU (qu’il s’agisse des caches de niveau 1, niveau 2 ou de la mémoire partagée) sont également protégées.
GPGPU : exécution parallèle, bilan théorique
NVIDIA a également corrigé deux goulets d’étranglement qui pouvaient brider les performances de ses puces en mode GPGPU. A l’image d’un CPU, un GPU donne l’illusion d’exécuter plusieurs tâches en parallèle en alternant entre elles, chaque tâche ayant droit à une portion de temps du GPU. La principale différence entre le CPU et le GPU est que sur ces derniers, changer de tâche est extrêmement coûteux. Avec le GF100 NVIDIA s’est attelé à ce problème et a optimisé les opérations de changement de contextes qui prennent désormais moins de 25 microsecondes. Avec une telle optimisation il est désormais envisageable d’avoir des communications inter-Kernel fréquentes ce qui n’était pas le cas avant.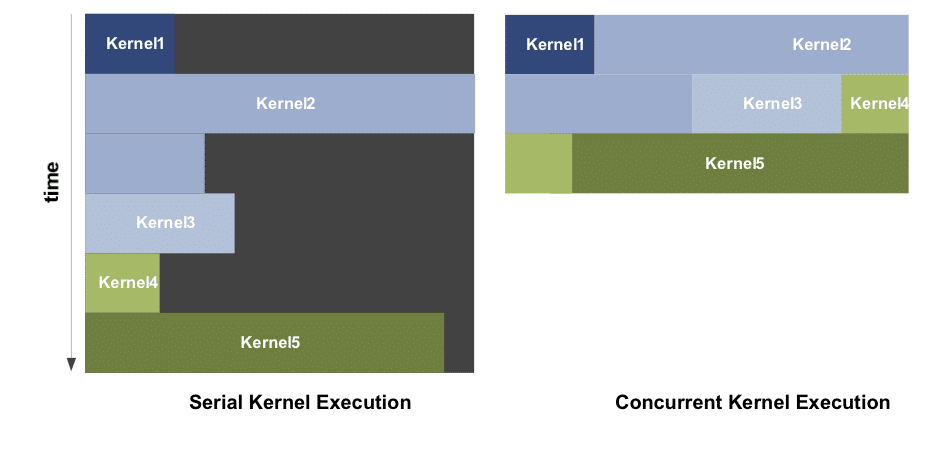 Autre grosse amélioration, jusqu’ici le GPU ne pouvait exécuter qu’un seul kernel à la fois sur l’ensemble du GPU. Lors de l’utilisation de kernels importants ça ne posait pas de problème et toutes les ressources étaient occupées, mais dans le cas de petits kernels il était possible de laisser une partie du GPU inoccupée. Le GF100 est désormais capable d’exécuter de façon parallèle plusieurs kernels, en pratique jusqu’à 1 par multiprocesseur ce qui permettra une meilleure efficacité du GPU, même dans le cas de gros kernels. Car lorsque ces derniers arrivent à la fin de leur exécution, il est possible qu’ils ne disposent pas d’un nombre de blocs suffisants pour occuper tout le GPU.
Autre grosse amélioration, jusqu’ici le GPU ne pouvait exécuter qu’un seul kernel à la fois sur l’ensemble du GPU. Lors de l’utilisation de kernels importants ça ne posait pas de problème et toutes les ressources étaient occupées, mais dans le cas de petits kernels il était possible de laisser une partie du GPU inoccupée. Le GF100 est désormais capable d’exécuter de façon parallèle plusieurs kernels, en pratique jusqu’à 1 par multiprocesseur ce qui permettra une meilleure efficacité du GPU, même dans le cas de gros kernels. Car lorsque ces derniers arrivent à la fin de leur exécution, il est possible qu’ils ne disposent pas d’un nombre de blocs suffisants pour occuper tout le GPU.
La gestion des branchements a été optimisée avec le support des instructions de prédication. Celles-ci reposent sur l’exécution des deux portions de codes divergentes en parallèle avant de déterminer laquelle conserver. Elles évitent ainsi le surcoût de l’instruction de branchement ce qui peut s’avérer avantageux lorsque le code à exécuter est limité.
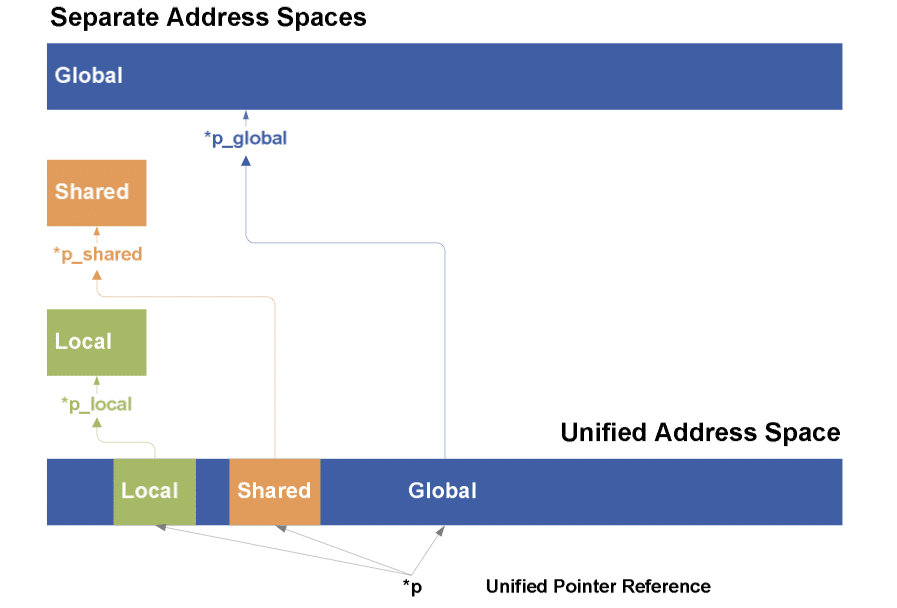
Enfin dernière nouveauté, un espace d’adressage mémoire unifié. Jusqu’ici l’ISA PTX 1.0 (le jeu d’instructions virtuel vers lequel les programmes CUDA sont compilés) disposait de 3 espaces d’adressage : l’espace global visible par tous, l’espace local privé de chaque thread et l’espace partagé par tous les threads d’un même bloc. La cible d’une instruction de chargement/rangement devait donc être déterminée à la compilation ce qui rendait difficile l’implémentation complète des pointeurs dont la cible peut changer dynamiquement à l’exécution. Avec l’ISA PTX 2.0 supporté par le GF100, un seul espace d’adressage est utilisé ce qui rend notamment possible le support de programmes C++. Les objets C++ reposent en effet largement sur l’utilisation des pointeurs pour implémenter les fonctions virtuelles, les fonctions dont le comportement peut changer à l’exécution en fonction du type dynamique de l’objet.
 Bilan
Bilan
Si nous avions été largement emballés par les performances du RV870 équipant les Radeon HD 5800, nous n’avions pu nous empêcher de regretter l’absence de nouveautés au niveau de l’architecture. Avec le GF100 NVIDIA nous a gâté en proposant une architecture entièrement nouvelle qui nous réservait son lot de bonnes surprises comme les 4 setup engine. Malgré tout certains points laissent penser que NVIDIA s’est peut être montré trop ambitieux avec le GF100, que ce soit en termes de planning (le GF100 arrive bien tard sur le marché) mais aussi en termes de hardware proposé : les fréquences sont bien plus faibles qu’espérées et un multiprocesseur est désactivé même sur le haut de gamme. Paradoxalement on sent que l’architecture est bien conçue et taillée pour l’avenir mais contrairement à un G80, la première implémentation ne semble pas en mesure d’exploiter toutes ses promesses dans les jeux actuels comme nous allons le voir.
Cependant ne boundons pas notre plaisir : après plusieurs mois de stagnation, le petit monde de la 3D s’est enfin réveillé, nous disposons désormais de deux architectures Direct3D 11 conçues avec des visions bien différentes et il est désormais temps de les départager en pratique avec les derniers jeux à la mode.
Les cartes
Bien que les GeForce GTX 480 et la 470 soient dotées du même GPU (comme les Radeon HD 5870 et 5850 chez ATI), elles sont conçues de manière fondamentalement différente.

GeForce GTX 480
La GeForce GTX 480 est une carte de 26,7 cm, soit un bon centimètre de moins que la Radeon HD 5870. Côté alimentation, elle a besoin d’un connecteur à huit broches et d’un autre à six broches en plus du port PCI Express. Nvidia recommande une alimentation de 600 watts minimum et annonce pour sa carte un TDP de 250 watts. C’est nettement moins que la Radeon HD 5970, qui passe tout juste sous le plafond de 300 watts imposé par le PCI-SIG.
Mais les chiffres officiels ne disent pas tout : bien que sur papier, la GeForce GTX 480 soit moins gourmande que le produit phare d’ATI (nous verrons ce qu’il en est réellement plus loin), elle a l’inconvénient de chauffer énormément, à tel point que son ventirad est l’un des plus impressionnants que nous ayons jamais vu sur une carte de référence. La chaleur du GPU et des puces mémoire est transmise via 4 caloducs à une batterie d’ailettes en aluminium, où elle est dissipée par un ventilateur repoussant l’air hors du boîtier, par l’arrière de la carte.

Le plus interpellant reste probablement le fait que la surface de la carte, par-dessus les ailettes, fait en réalité partie du ventirad ! Il s’agit normalement d’un élément que l’on peut prendre en main lorsqu’on désire extraire la carte de l’ordinateur, mais après nous être brûlés en effectuant cette opération, nous nous sommes dits qu’il pourrait être intéressant d’en mesurer la température. Il en ressort que dans les jeux (en situation réelle sous Crysis, donc, pas sous un benchmark artificiel comme FurMark), la température du métal de couverture dépasse les 71 °C. Cela aura évidemment un impact sur le fonctionnement en SLI, mais c’est un sujet que nous aborderons plus tard.
| GeForce GTX 480 | GeForce GTX 470 | |
|---|---|---|
| Graphics Processing Clusters (GPC) | 4 | 4 |
| Streaming Multiprocessors (SM) | 15 | 14 |
| ALU | 480 | 448 |
| Unités de texture | 60 | 56 |
| ROP | 48 | 40 |
| Fréquence GPU | 700 MHz | 607 MHz |
| Fréquence ALU | 1401 MHz | 1215 MHz |
| Fréquence mémoire | 924 MHz | 837 MHz |
| Quantité de mémoire | 1,5 Go GDDR5 | 1,25 Go GDDR5 |
| Interface mémoire | 384 bits | 320 bits |
| Bande passante mémoire | 177,4 Go/s | 133,9 Go/s |
| Fillrate | 42 GTexels/s | 34 GTexels/s |
| Finesse de gravure | 40nm (TSMC) | 40nm (TSMC) |
| Sorties vidéo | 2 x DVI dual-link, 1 x mini-HDMI | 2 x DVI dual-link, 1 x mini-HDMI |
GeForce GTX 470

La GeForce GTX 470 est plus élégante que sa grande sœur : longue de 24,1 cm (soit, une fois encore, un bon centimètre de mois que sa concurrente, l’ATI Radeon HD 5850), elle ne nécessite « plus que » deux connecteurs à six broches en plus du port PCI Express et consomme donc un maximum de 215 watts, c’est-à-dire environ 30 watts de moins que la Radeon HD 5870.Les caloducs et le radiateur exposé font place à un boîtier recouvrant l’ensemble de la carte et contenant un ventilateur extrayant l’air chaud par une grille adjacente aux sorties vidéo.
Les températures au repos et en charge ne sont pas aussi élevées que celles de la GTX 480, bien que le GPU des deux cartes soit prévu pour supporter des chaleurs pouvant atteindre les 105 °C. Il est intéressant d’observer leur comportement thermique en temps réel : en charge, la température monte graduellement jusqu’à atteindre son niveau maximal (97 et 96 °C respectivement pour la GTX 480 et la GTX 470), et c’est à ce moment que le ventilateur accélère d’un cran afin de réduire la chaleur de quatre ou cinq degrés.Pour comparaison, la plupart des autres grosses cartes que nous avons testées deviennent également de plus en plus chaudes mais n’enclenchent leur ventilateur qu’à l’approche de leur enveloppe thermique, et les températures finissent par se stabiliser à ce niveau.

NVIDIA Surround, sorties graphiques et vidéo
Pour ceux qui se sont habitués à la technologie Eyefinity d’AMD, le Nvidia Surround est quelque peu décevant.
Alors certes, avec la GeForce GTX 480, Nvidia dispose enfin d’une puissance de traitement suffisante pour que le jeu en 2560 x 1600 ne mette plus l’unique GPU à genoux. Comme AMD, la firme californienne propose donc d’afficher les jeux sur plusieurs écrans (trois maximum ici).
La bonne nouvelle est que le logiciel prévu à cet effet, Nvidia Surround, prend en charge la correction des cadres d’écran : on a donc plus l’impression de regarder à travers une fenêtre dont les croisées masqueraient une partie de la vue que d’avoir en face de soi une série de tableaux juxtaposés.Comme il fonctionne également sur les anciennes GeForce GTX 200, tout possesseur de cartes de cette génération en SLI peut bénéficier du multi-écrans.
La mauvaise nouvelle, car il y en a une, est que les cartes à base de processeur GF100 (comme les GT 200) sont limitées à 2 écrans chacune, et qu’il faut donc deux cartes pour profiter de ses trois écrans. On est donc bien loin des trois (et bientôt six !) écrans par carte d’AMD ! Nous admettrons que les personnes possédant trois écrans sont encore relativement rares, mais ce n’est pas une raison.
Il faut toutefois mettre au crédit de Nvidia que la société prévoit de prendre en charge la stéréoscopie sur trois écrans. Si vous avez les fonds nécessaires pour vous offrir trois écrans LCD 120 Hz, deux cartes graphiques et un kit GeForce 3D Vision, ce sera la fête. Une fête chère mais extrêmement enviable, et pour laquelle Nvidia sera le seul fabricant à fournir le matériel. La 3D Vision Surround n’est pas intégré aux pilotes GeForce 197 mais devrait faire son apparition dans la version 256.xx dans le courant du mois prochain. Comptez sur nous pour tester cette fonction dès qu’elle sera disponible.
Sorties vidéo
Comme vous l’aurez probablement déduit en lisant les lignes qui précèdent, le GF100 possède deux pipelines d’affichage. Contrairement aux cartes de générations précédentes, qui utilisaient une puce NVIO annexe, ceux-ci sont intégrés au GPU.Les GeForce GTX 480 et 470 sont dotées de deux sorties DVI Dual Link et d’une sortie mini-HDMI. Sur ces trois prises, il est possible d’en utiliser deux simultanément.

Rien de bien spécial à ce niveau donc, le DVI étant toujours omniprésent et le plafond fixé à deux écrans par carte restant la norme en dehors des Radeon HD 5000.La raison pour laquelle AMD accorde tant d’importance au DisplayPort tient essentiellement à la manière dont l’Eyefinity gère l’affichage sur plus de trois écrans.
Accélération vidéo : le GF100 dans votre PCHC
Tout le monde se focalisant sur les performances du GF100 en matière de calcul et de jeux, presque personne ne s’est intéressé aux capacités audiovisuelles de la puce.Bien entendu, personne ne penserait sérieusement à mettre une GeForce GTX480 ou 470 dans un PCHC, mais il pourrait en être tout autrement des cartes dérivées qui ne vont sans aucun doute pas tarder à arriver sur le marché.
La GF100 est doté du moteur d’affichage VP4, lancé en octobre dernier sur les GeForce GTX 220.Celui-ci prend en charge l’accélération du MPEG-4 ASP (Advanced Simple Profile) en plus de celle des MPEG-2, VC-1 et H.264 déjà gérés par le VP3.
Il n’est par ailleurs plus nécessaire d’utiliser un câble S/PDIF pour gérer l’entrée audio HDMI : comme les GT 220 et 240, le GF100 prend en charge l’audio HDMI via PCI Express, ce qui permet d’utiliser le LPCM multicanal.Il n’est toutefois pas possible d’obtenir le bitstream de TrueHD ni de DTS-HD Master Audio, contrairement à ce qu’autorisent les ATI Radeon HD 5000 et les processeurs Intel Core i3/i5 de type Clarkdale.Enfin, les cartes à base de GF100 ne prennent pas en charge l’audio lossless, mais cela n’aura probablement pas la moindre importance tant que l’architecture Fermi n’aura pas été sérieusement miniaturisée.
Configuration de test
| Configuration de test | |
|---|---|
| Processeur | Intel Core i7-980X Extreme (Gulftown) 3,33 GHz, 6,4 GT/s, 12 Mo de cache L3, fonctions d’économie d’énergie activées |
| Carte-mère | Gigabyte X58A-UD5 (LGA 1366) X58/ICH10, BIOS F5 |
| Mémoire | Kingston HyperX T1 Series 6 Go (3 x 2 Go) DDR3-2000 8-8-8-24 @ 1600 MHz |
| Disque dur | Intel SSDSA2MH160G2C1 160 Go SATA 3 Gb/s |
| Réseau | Realtek RTC8111D, 1 Gbit/s |
| Cartes graphiques | Nvidia GeForce GTX 480 1,53 Go |
| Nvidia GeForce GTX 470 1,28 Go | |
| Nvidia GeForce GTX 295 1,79 Go | |
| Nvidia GeForce GTX 285 1 Go | |
| ATI Radeon HD 5970 2 Go | |
| ATI Radeon HD 5870 1 Go | |
| ATI Radeon HD 5850 1 Go | |
| ATI Radeon HD 4870 X2 2 Go | |
| Alimentation | Cooler Master UCP 1100 watts |
| Ventirad CPU | Intel DBX-B |
| Logiciels et pilotes | |
| OS | Microsoft Windows 7 Édition Intégrale x64 |
| DirectX | DirectX 11 |
| Pilote de carte-mère | Intel INF Chipset Update Utility 9.1.1.1019 |
| Pilotes de carte graphique | Nvidia GeForce 197.17 (GTX 480/470) |
| Nvidia GeForce 197.13 (GTX 295/285) | |
| AMD Catalyst 10.3a | |
Jeux | |
Crysis | High Quality Settings, No AA / No AF, 4xAA / No AF, vsync off, 1680×1050 / 1900×1200 / 2560×1600, DirectX 10, Patch 1.2.1, version 64 bits |
S.T.A.L.K.E.R.: Call of Pripyat | Extreme Quality Settings, No AA / No AF, 4xAA / AF désactivé, vsync désactivé, 1680×1050 / 1920×1200 / 2560×1600, DirectX 10, outil de benchmark |
Call of Duty: Modern Warfare 2 | Ultra High Settings, No AA / No AF, 4xAA / No AF, 1680×1050 / 1920×1200 / 2560×1600, Second Sun, séquence de 45 secondes, FRAPS |
DiRT 2 | Ultra High Settings, No AA / No AF, 4xAA / No AF, 1680×1050 / 1920×1200 / 2560×1600, benchmark intégré (Démo), DirectX 9 forcé |
Metro 2033 | High Quality Settings, AAA / No AF, 4x MSAA / No AF, vsync off, PhysX off, 1680×1050 / 1920×1200 / 2560×1600, Chapter 1: Chase, séquence de 150 secondes, FRAPS |
Battlefield: Bad Company 2 | Custom (Highest) Quality Settings, 1xAA / No AF, 8x MSAA / No AF, vsync off, 1680×1050 / 1920×1200 / 2560×1600, cinématique d’introduction, séquence de 145 secondes, FRAPS |
3DMark Vantage | Performance Default, High Quality, Extreme Quality, PPU désactivé |
Call of Duty: Modern Warfare 2 (DirectX 9)
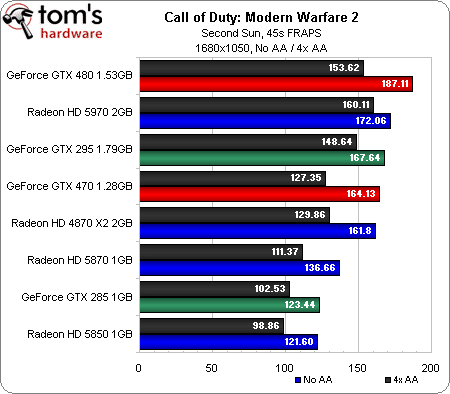
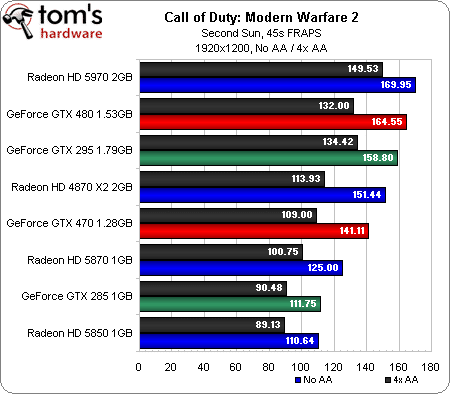
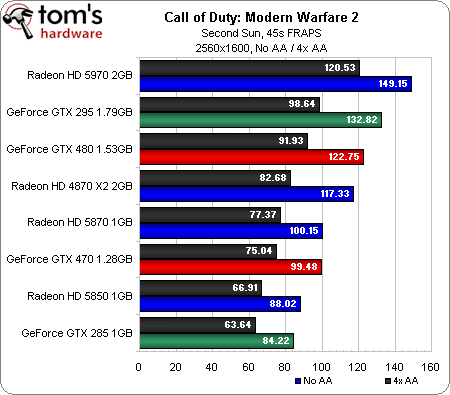
Nous avons longtemps considéré Call of Duty comme un titre dont les performances dépendaient essentiellement du processeur, ses graphismes n’étant pas particulièrement complexes (un peu comme Left 4 Dead à cet égard). Avec un Core i7-980X, on dispose toutefois d’une puissance de traitement qui permet aux cartes graphiques de respirer et de se différencier les unes des autres.
La GeForce GTX 480 commence par prendre la tête mais perd une position à chaque fois que nous augmentons la résolution, pour finir à la troisième place en 2560 x 1600, derrière la Radeon HD 5970 d’ATI et même la GeForce GTX 295. Cela reste toutefois relativement impressionnant : si l’on se contentait des résultats de ce benchmark, la GTX 480 concurrencerait plus la Radeon HD 5970 que la 5870.
Ceci étant dit, la carte graphique la plus intéressante est probablement la GeForce GTX 470, qui parvient à se mesurer à la Radeon HD 5870, ne lui concédant sa place qu’en 2560 x 1600 (avec et sans antialiasing).
On note également que les Radeon HD 4870, bien que n’étant plus disponibles dans le commerce, continuent à très bien se défendre : elles affichent des performances plus que correctes dans l’absolu, et ce, jusqu’en 2560 x 1600.
DiRT 2 (DirectX 9)
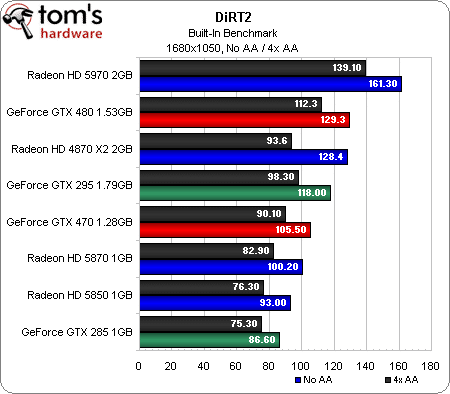
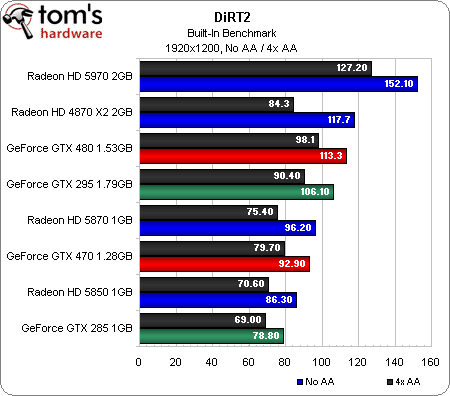
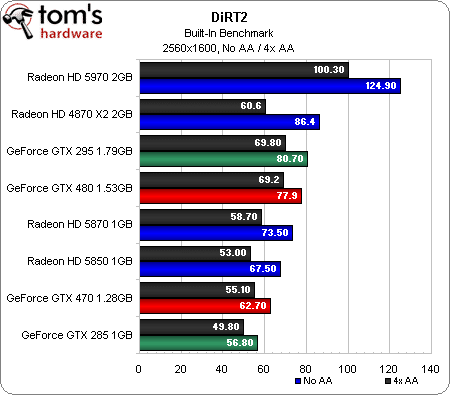
Nous avons bien failli faire passer ce benchmark à la trappe. Il faut savoir que notre protocole de test fait appel à la démo de DiRT 2, qui comprend un mode « benchmark » intégré, contrairement au jeu final qui nécessite FRAPS et un vrai joueur.
Nous nous sommes très rapidement rendu compte que les cartes à base de GF100 obtenaient des scores vraiment très élevés par rapport aux Radeon HD 5xxx, ce qui était tout de même un peu bizarre compte tenu du fait que les deux architectures sont capables de faire tourner le jeu en mode DirectX 11. En grattant un peu, nous avons découvert que les GeForce GTX 480 et 470 ne sont pas détectées correctement par la démo, qui ne les considère pas comme des cartes DX11 (bien qu’elles fonctionnent comme prévu dans le jeu proprement dit). Plutôt que de laisser tomber DiRT 2, nous avons donc testé toutes les cartes en mode DX9 (dont le rendu visuel reste très proche, cf notre article) afin d’obtenir un point de comparaison.
Pour ce qui est des résultats, les cartes ATI bi-GPU occupent la première place en 1920 x 1200 et en 2560 x 1600. La GeForce GTX 480 se défend bien par rapport à la Radeon HD 5870, bien que son avance diminue au fur et à mesure que l’on monte en résolution. La GeForce GTX 470 commence devant la Radeon HD 5870 en 1600 x 1050, passe entre les deux ATI mono-GPU en 1920 x 1200 et termine derrière la Radeon HD 5850 en 2560 x 1600.
Crysis (DirectX 10)
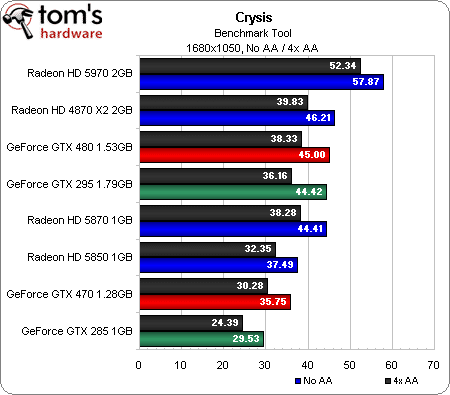
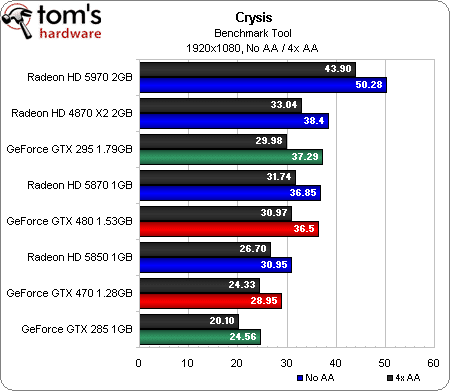
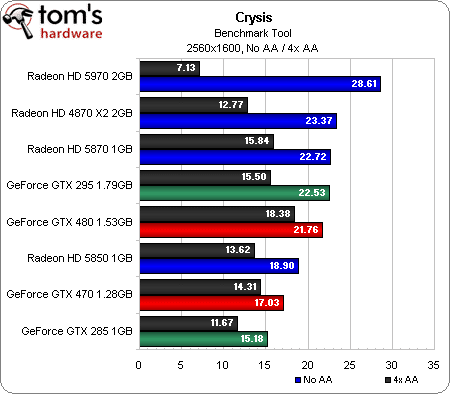
Vieux de deux ans et demi, Crysis est probablement ce qui se rapproche le plus d’un benchmark synthétique dans nos jeux. Il n’en reste pourtant pas moins, à ce jour, l’un des titres les plus exigeants et populaire du marché. Sachant qu’il est par ailleurs optimisé pour DirectX 10, il permet également de tester une série de cartes plus anciennes comme l’ATI Radeon HD 4870 X2, qui montre qu’elle en a encore dans le ventre.
Personne ne sera vraiment surpris de voir la Radeon HD 5970 ravir la première place dans toutes les résolutions. Les deux (plus) petites Radeon HD 5xxx testées aujourd’hui affichent une légère baisse de performances dans Crysis lorsque l’antialiasing est activé ; la 5970, par contre, voit son score chuter dans ce mode.
Côté Nvidia, la GeForce GTX 480 démarre correctement, à un niveau plus ou moins égal à celui de la GeFroce GTX 295, mais se fait progressivement dépasser par l’ancien fer de lance de la firme au caméléon. Cependant, elle se défend comparativement mieux lorsque l’antialiasing est activé. La GeForce GTX 470, quant à elle, se fait dans l’ensemble dépasser par l’ATI Radeon HD 5850, ne parvenant à la battre qu’en 2560 x 1600 avec l’antialiasing activé (mais bon, cela reste totalement injouable).
De manière générale, si vous jouez à Crysis, mieux vaut posséder une Radeon.
S.T.A.L.K.E.R.: Call Of Pripyat (DirectX 10)
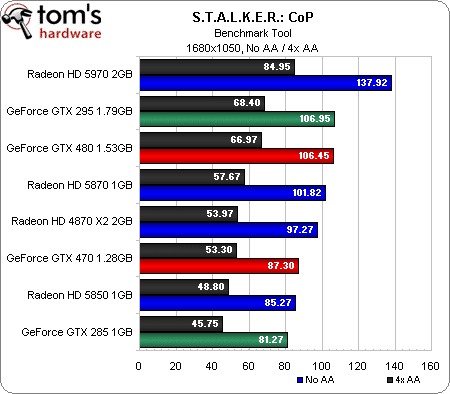
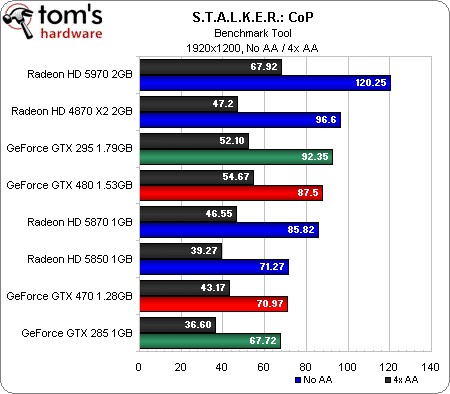
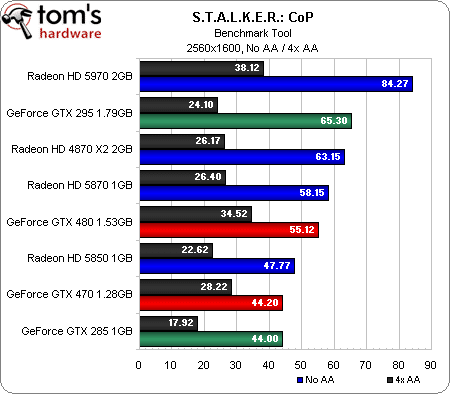
Lorsque nous avons révisé notre protocole de test pour cet article, nous y avons ajouté une série de titres DirectX 10 et 11. S’il peut paraître injuste de comparer des cartes de générations différentes dans des jeux DX11 ramenés en DX10, cela nous permet au moins de voir comment les nouveaux modèles se défendent par rapport aux anciens.
Comme sous Call of Duty, la GeForce GTX 480 commence par briguer la troisième place derrière la Radeon HD 5970 et la GeForce GTX 295 et devant les Radeon HD 5870 et 4870 X2. En 1920 x 1200, elle se place derrière les trois cartes bi-GPU et en 2560 x 1600, elle se fait également dépasser par la Radeon HD 5870.
Ce n’est toutefois pas le fin mot de l’histoire : si l’on ne note pas grand-chose d’intéressant en 1680 x 1050, il apparaît que les cartes bi-GPU voient leurs performances chuter plus rapidement que les autres lorsque l’antialiasing est activé à plus haute résolution. La nouvelle carte haut de gamme de Nvidia se hisse ainsi à la seconde place en 1920 x 1200 AA (avec un framerate jouable, qui plus est) et en 2560 x 1600 AA.
Même constat pour la GeForce GTX 470, dont les performances sont moins impactées par l’antialiasing en 1920 x 1200 et en 2560 x 1600 que celles des Radeon HD 5870 et 5850.
Metro 2033 (DirectX 10/11)
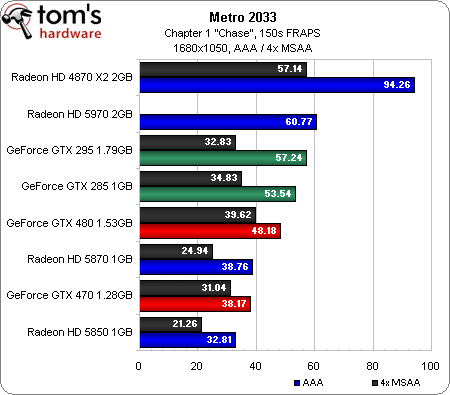
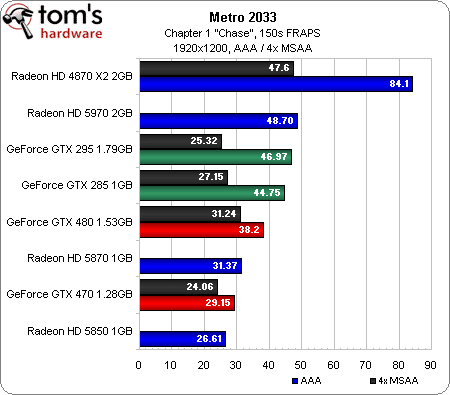
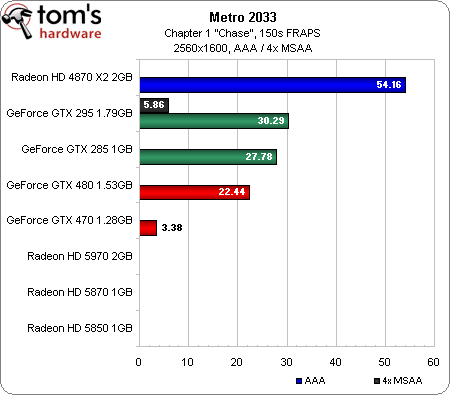
Les graphiques ci-dessus comptent parmi les plus laids que nous ayons jamais publiés ; il faut dire que Metro 2033 est un titre des plus exigeants…
L’interface permet de passer du mode DirectX 10 à DirectX 11 sans quitter le jeu, ce qui est appréciable. Le gros problème est que les cartes DirectX 10 bénéficient d’un énorme bonus de performances par rapport aux modèles capables de fonctionner en mode DirectX 11, ce qui a un effet évident sur la position de la Radeon HD 4870 X2 et des GeForce GTX 285/295.
Si l’on ne tient compte que des cartes de dernière génération, la Radeon HD 5970 arrive en première place en 1680 x 1050 et 1920 x 1200, suivie de la GeForce GTX 480, de la Radeon HD 5870, de la GeForce GTX 4870 et de la Radeon HD 5850. En 2560 x 1600, il ne reste plus qu’une seule carte ATI fonctionnelle et la GeForce GTX 480 est la seule carte DirectX 11 disposant de suffisamment de mémoire pour permettre l’activation de l’antialiasing. Que signifient tous les scores manquants ? Il s’agit des cas où le test démarre, mais donne des résultats oscillant entre zéro et une image par seconde. À l’évidence, ATI a encore du pain sur la planche en ce qui concerne la prise en charge de DirectX 11 en mode 4xMSAA.
GeForce GTX 480 : comparaison DirectX 10 / DirectX 11
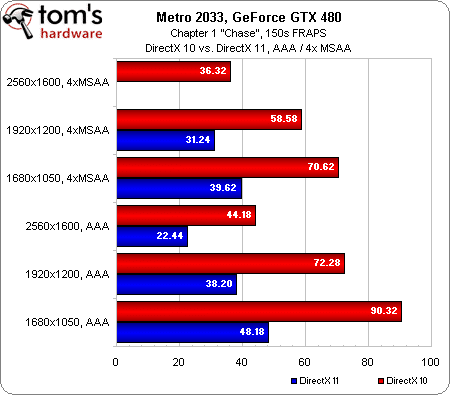
Quelle est l’impact du passage de DirectX 10 à DirectX 11 sur les performances ? Sur la GeForce GTX 480, on a droit à un rapport de 1 pour 2, quel que soit le mode d’antialiasing utilisé. Pourquoi une différence si énorme ? En mode DirectX 11, la profondeur de champ (un filtre DirectCompute) est activée ; c’est joli, mais cela réduit considérablement les performances. Il est clair que pour profiter des graphismes de Metro 2033 tels que ses développeurs l’ont prévu, il faut une carte graphique très haut de gamme.
Notons également que le titre prend en charge le moteur PhysX. Nous ne l’avons pas testé, mais le jeu comporte un grand nombre d’effets qui sont affectés par cette option.
Battlefield: Bad Company 2 (DirectX 10/11)
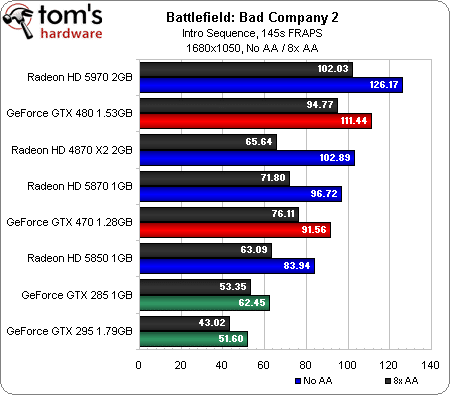
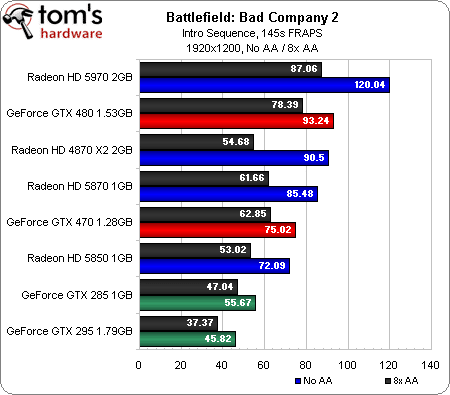
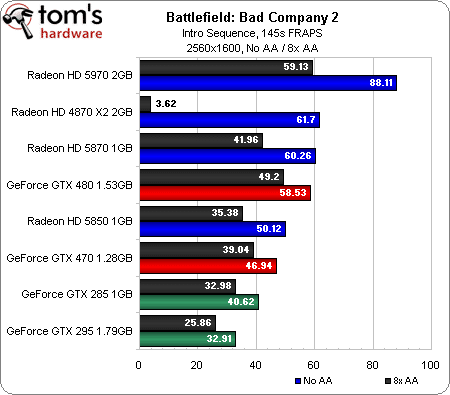
B:BC 2 est lui aussi un titre capable de prendre en charge DirectX 11 ; a priori, les cartes DirectX 10 devraient donc bénéficier d’un avantage en termes de performances. Curieusement, ce n’est pas le cas. Les GeForce GTX 285 et 295 terminent en effet en queue de peloton, la seule carte de génération précédente à pouvoir se mesurer aux modèles actuels étant la Radeon HD 4870 X2 (et pour info, on rapporte assez fréquemment sur les forums que la GeForce GTX 295 pose des problèmes sous Bad Company 2).
Toutes les concurrentes de ce test offrent des performances jouables en 1680 x 1050. On note avec plaisir que les GeForce GTX 480 et 470 ne voient pas trop leurs performances chuter entre l’antialiasing 1x et 8x, ce qui permet à la GTX 470 de dépasser la Radeon HD 5870 en mode 8xAA alors que cette dernière est plus rapide avec l’AA désactivé.
En 2560 x 1600, l’ATI Radeon HD 5970 creuse l’écart avec ses poursuivantes. La GeForce GTX 480, de son côté, tombe à la quatrième place (derrière la Radeon HD 5870) sans AA, mais remontre à la deuxième en 8xAA.
Les GeForce GTX 480 en SLI
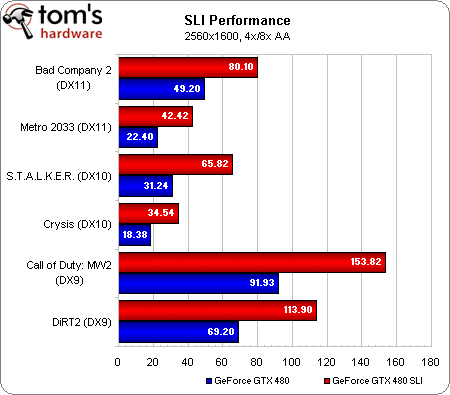
En dernière minute, nous sommes parvenus à mettre la main sur une deuxième GeForce GTX 480 afin de tester les performances en SLI. Nous n’avons certes pas eu l’occasion de soumettre cette configuration à l’ensemble de notre protocole de test, mais nous l’avons tout de même faite passer par Metro 2033, S.T.A.L.K.E.R.: CoP, Crysis, Call of Duty: Modern Warfare 2 et DiRT 2 en 2560 x 1600 avec le MSAA en 4x, ainsi que par Battlefield: Bad Company 2 à la même résolution avec le MSAA en 8x.
Ce qui est finalement assez représentatif, étant donné que les personnes les plus susceptibles de se procurer deux cartes graphiques haut de gamme sont des joueurs. Dans l’ensemble (à l’exception potentielle de Crysis, où les résultats se discutent), il devient tout à fait envisageable de jouer en 2560 x 1600 avec l’antialiasing activé. Lorsque le 3D Vision Surround sera testable, vous aurez plus que probablement besoin d’une carte aussi rapide que possible pour obtenir un framerate potable en ce qui sera de facto du 5760 x 1200. Il est possible que la technologie soit rendue disponible sur les cartes plus anciennes, mais nous sommes pratiquement certains qu’elles seront trop lentes pour permettre de jouer dans les conditions auxquelles les vrais amateurs se sont habitués.
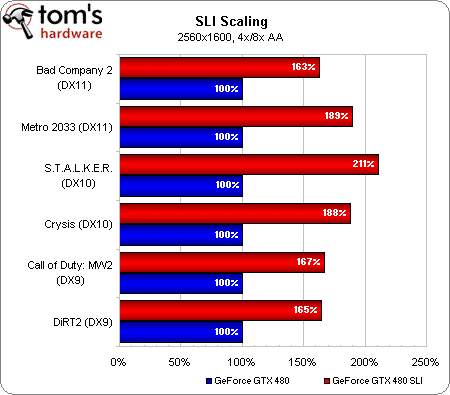
Le deuxième graphique compare les performances avec une et deux cartes. Dans le pire des cas, sous Bad Company 2, le SLI entraîne une hausse de performances de 63 %, ce qui n’est franchement pas mal pour un jeu aussi récent. Sous S.T.A.L.K.E.R.: CoP, la vitesse est plus que doublée. Nous avons revérifié ces résultats : ils sont bien corrects et ils montrent que, même avec les cartes les plus puissantes, on tombe encore aisément sur des goulots d’étranglement. Le SLI de GeForce GTX 480 démontre qu’à très haute résolution, l’ajout d’une deuxième carte peut pratiquement doubler les performances. Il s’agit là très probablement des framerates les plus élevés que vous soyez susceptibles de voir avant un moment, car il y a peu de chances que Nvidia sorte une carte bi-GPU dans l’immédiat : les problèmes d’alimentation et de dissipation thermique seraient bien trop importants.
Si vous comptez vous lancer dans l’aventure des GTX 480 en SLI, n’oubliez pas de tenir compte d’une série de paramètres pratiques. Premièrement, la chaleur : sur notre carte mère Gigabyte X58A-UD5, nous avons laissé deux emplacements vides entre les cartes. Sur les cartes mères à trois emplacements, Nvdia recommande d’employer le premier et le troisième afin de laisser les cartes graphiques respirer. À raison : placer deux GTX 480 dos à dos est une mauvaise idée. Deuxièmement et dernièrement : l’alimentation. Un modèle puissant est bien entendu de rigueur, bien que Nvidia n’ait encore fait aucune recommandation officielle à ce niveau.
Consommation et température
Consommation en veille et au repos
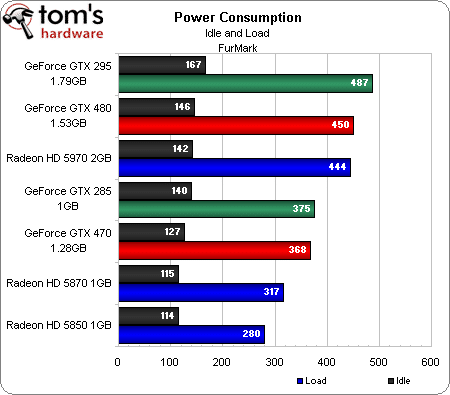
C’est ici que les choses deviennent réellement intéressantes. Nous savions avant de commencer que les GeForce GTX 480 et 470 seraient des cartes gourmandes et qu’elles chaufferaient beaucoup : NVIDIA nous l’avait confié dès janvier. Cependant, quand il s’agit de mesurer les valeurs de température et de dissipation thermique, il devient difficile de trouver une procédure sur laquelle tout le monde s’accorde.
On considère généralement FurMark comme peu réaliste quand il s’agit d’obtenir la consommation de pointe ; Dave Baumann, de chez AMD, a même été jusqu’à qualifier ce logiciel de « power virus ». Nous considérons toutefois qu’il peut servir à déterminer le « pire des cas » (une mesure certes très théorique, mais qui a le mérite d’être cohérente) et, à ce titre, peut donc s’avérer intéressant. Il nous montre ainsi que, si la GeForce GTX 480 ne consomme pas autant que la GeForce GTX 295 (un modèle bi-GPU), elle reste plus gourmande que la Radeon HD 5970 (dont les deux GPU nécessitent déjà 450 watts !). La GeForce GTX 470, quant à elle, consomme nettement plus que la Radeon HD 5870.
Vous noterez dans le graphique ci-dessus l’absence de l’ATI Radeon HD 4870 X2. Nos tests précédents ont montré qu’elle consommait à peu de choses près autant que la GeForce GTX 295 de Nvidia, mais aucune des cartes « X2 » dont nous disposions au labo n’a prétendu fonctionner correctement sous FurMark : elles sont toutes restées coincées à 13 images/seconde, avec une consommation à peine supérieure à celle enregistrée au repos. Peut-être qu’ATI a décidé de régler à sa manière le problème du « virus » précité, mais cela n’empêche pas les Radeon X2 de consommer dans les 400 watts dans les jeux.
Température
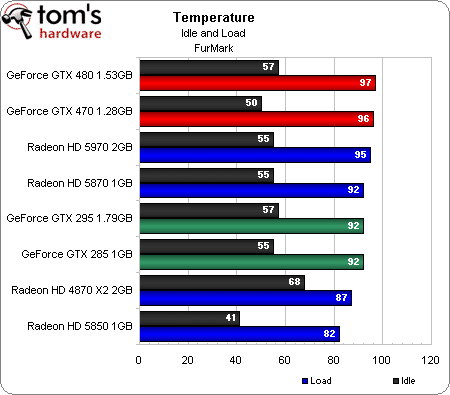
FurMark a également l’intérêt de faire monter la température, bien qu’il faille signaler qu’aucune des concurrentes examinées aujourd’hui n’ait rencontré de problème de stabilité lié à la dissipation thermique. La GeForce GTX 480, par contre, doit faire tourner son ventilateur très rapidement, ce qui génère forcément pas mal de bruit. Le problème semble toutefois limité à FurMark : nous ne sommes pas parvenus à le répliquer dans les jeux.
Et en situation un peu plus réelle, comment se défendent les GeForce GTX 480 et 470 ? Très bonne question.
Efficacité énergétique sous Unigine Heaven 2.0
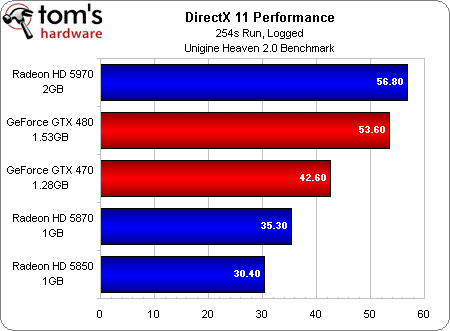
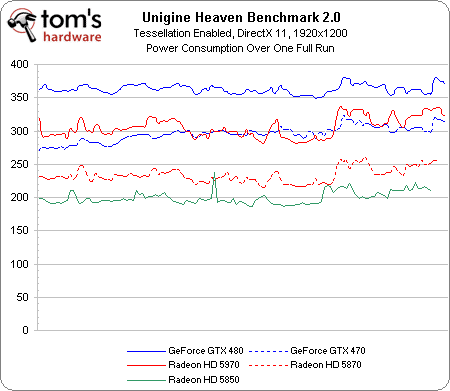
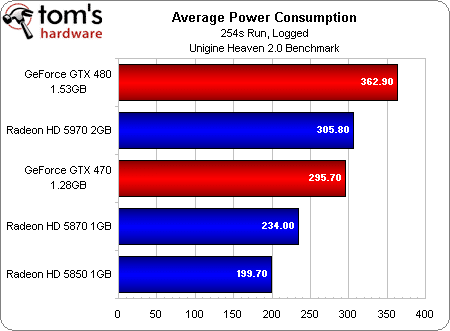
Nous avons fait passer toutes les cartes DirectX 11 de cet article par le benchmark Unigine 2.0, qui mesure les performances moyennes en images par seconde (framerate). Lors de ce benchmark, nous avons branché chaque configuration sur un wattmètre USB enregistrant la consommation toutes les deux secondes, ce qui nous a ensuite de permis de calculer une moyenne. En divisant par celle-ci la moyenne des performances, nous avons obtenu un indice d’efficacité qui nécessite d’être analysé.
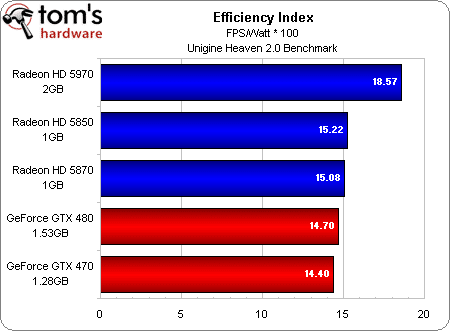
On voit clairement que, malgré sa consommation élevée, la Radeon HD 5970 est la carte la plus efficace de ce test (ce qui en dit long sur ses performances), suivie des Radeon HD 5850 et 5870. Les cartes Nvidia GeForce GTX 480 puis 470 ferment la marche. Une question se pose donc : si NVIDIA présente sa GTX 480 comme une carte consommant au maximum 250 watts alors que selon ATI, la HD 5970 peut monter jusqu’à 294 watts, pourquoi la nouvelle GeForce consomme-t-elle autant ?
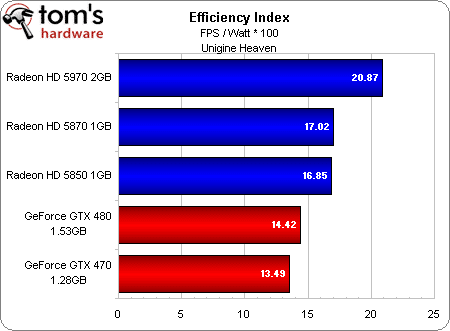
Bien évidemment, il serait simple d’obtenir des résultats différents en jouant sur les points faibles et forts de chaque architecture. Désactiver la tesselation, par exemple, donnerait un avantage important aux Radeon dans la mesure où celles-ci voient leurs performances baisser assez nettement quand cette fonction est active. Sachant qu’il y a quelques jours, Unigine a lancé la version 2.0 de son logiciel de test et que celle-ci accorde encore plus d’importance à la tesselation que la première version (qui nous avait servi à obtenir un premier lot de résultats, non publiés), les chiffres que vous voyez dans ces colonnes représentent donc un scénario extrêmement favorable à NVIDIA. Si nous réduisons la tesselation (et de façon générale, dans l’ensemble des jeux), les Radeon HD 58xx se montrent bien plus efficaces !
[MAJ 27/03] Voici d’ailleurs à titre indicatif le rapport performances/consommation obtenu en revenant cette fois à la première version du benchmark Unigine :
Conclusion
 Au final, notre avis sur les GeForce GTX 480 et 470 est clairement mitigé.
Au final, notre avis sur les GeForce GTX 480 et 470 est clairement mitigé.
Du côté des bonnes nouvelles : les performances (malgré tout). Oui, la GeForce GTX 480 est bien la carte single-GPU la plus rapide du moment (plus rapide que la Radeon HD 5870 donc), et cela malgré le fait que NVIDIA ait du désactiver 32 cores sur son GPU et adopter des fréquences probablement plus conservatrices que prévu vu les difficultés de production rencontrées. C’est également le cas pour la GeForce GTX 470 face à la Radeon HD 5850, et il est à noter que ces avances sont d’autant plus flagrantes que l’antialiasing est activé, d’une part grâce à une plus grande quantité de mémoire (1,5 Go et 1,25 Go), d’autre part grâce à une puissance de calcul indéniablement plus élevée et aux améliorations apportées aux ROP. Il est en revanche à noter que du côté de la carte graphique la plus rapide, la Radeon HD 5970 n’est même pas menacée.
La liste des griefs sera en revanche plus longue. Le plus évident concerne les prix : à près de 500 €, la GeForce GTX 480 s’avère 150 € plus chère que la Radeon HD 5870, et seulement 100 € moins chère que la Radeon HD 5970. Et pour 350 €, vous aurez donc le choix entre la Radeon HD 5870 et la GeForce GTX 470 qui lui est nettement inférieure dans les jeux actuels. Le surcoût réclamé par NVIDIA est donc trop important par rapport aux performances obtenues. Bien sûr, il reste à ce dernier les avantages procurés par PhysX, CUDA et 3D Vision. Plus inhabituel, on trouvera du côté d’AMD la consommation.
Celle-ci s’est en effet avérée catastrophique sur les nouvelle GeForce GTX ! La GTX 480 consomme à elle seule plus que la Radeon HD 5970 (une carte bi-GPU donc, et qui reste comme nous l’avons vu plus performante), et s’avère en moyenne 50 % plus gourmande en charge que la Radeon HD 5870, contre encore 27 % au repos ! En résulte une température de fonctionnement également très élevée et une accélération conséquente du ventilateur lorsque la charge devient réellement importante (ce qui n’est toutefois pas toujours le cas dans les jeux actuels).
Autre point gênant : la disponibilité. Si les GTX 480 et 470 ne seront pas disponibles avant mi-avril, les déclinaisons abordables (moins de 350 €) de cette nouvelle architecture n’ont pu être lancées simultanément et n’arriveront pas avant des mois, laissant AMD entièrement seul sur le créneau des cartes graphiques DirectX 11 (désormais inévitable même selon NVIDIA) de 100 à 300 € !
Certes, nous l’avons vu, le potentiel de l’architecture NVIDIA reste supérieur en termes de performances sur de nombreux tests synthétiques à celui des Radeon HD 5×00. Lorsque les jeux feront un usage massif de DirectX 11 et de la tesselation (ce qui n’est pas encore le cas), elle se montrera sous un jour bien meilleur, et l’on peut faire confiance aux ingénieurs logiciels de la firme pour tout mettre en œuvre (depuis ceux travaillant sur les compilateurs à ceux dépêchés chez les développeurs en passant par les SDK – il suffit de regarder le travail réalisé sur Metro 2033). Reste que le manque de flexibilité et le retard pris au niveau du rapport performances/consommation plaide en ce jour en faveur du chemin adopté par AMD depuis ses Radeon HD 3800.










