Seulement l’A100 est commercialisé depuis 2020.
Lors de la Hot Chips 34, Intel a publié quelques résultats de benchmarks obtenus par le GPU Ponte Vecchio. Selon l’entreprise, il s’avère jusqu’à 2,5 fois plus performant qu’une solution NVIDIA A100.
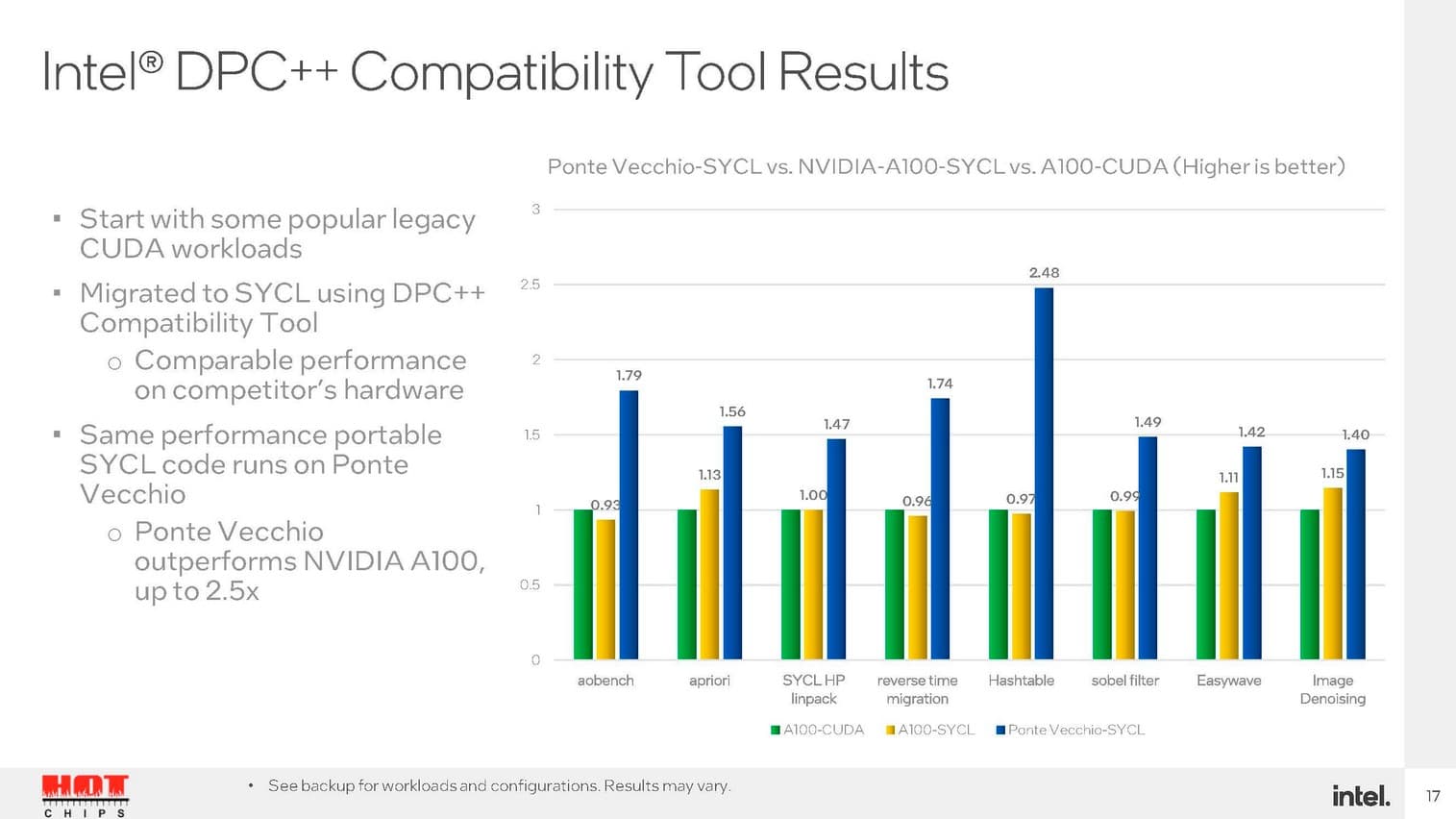
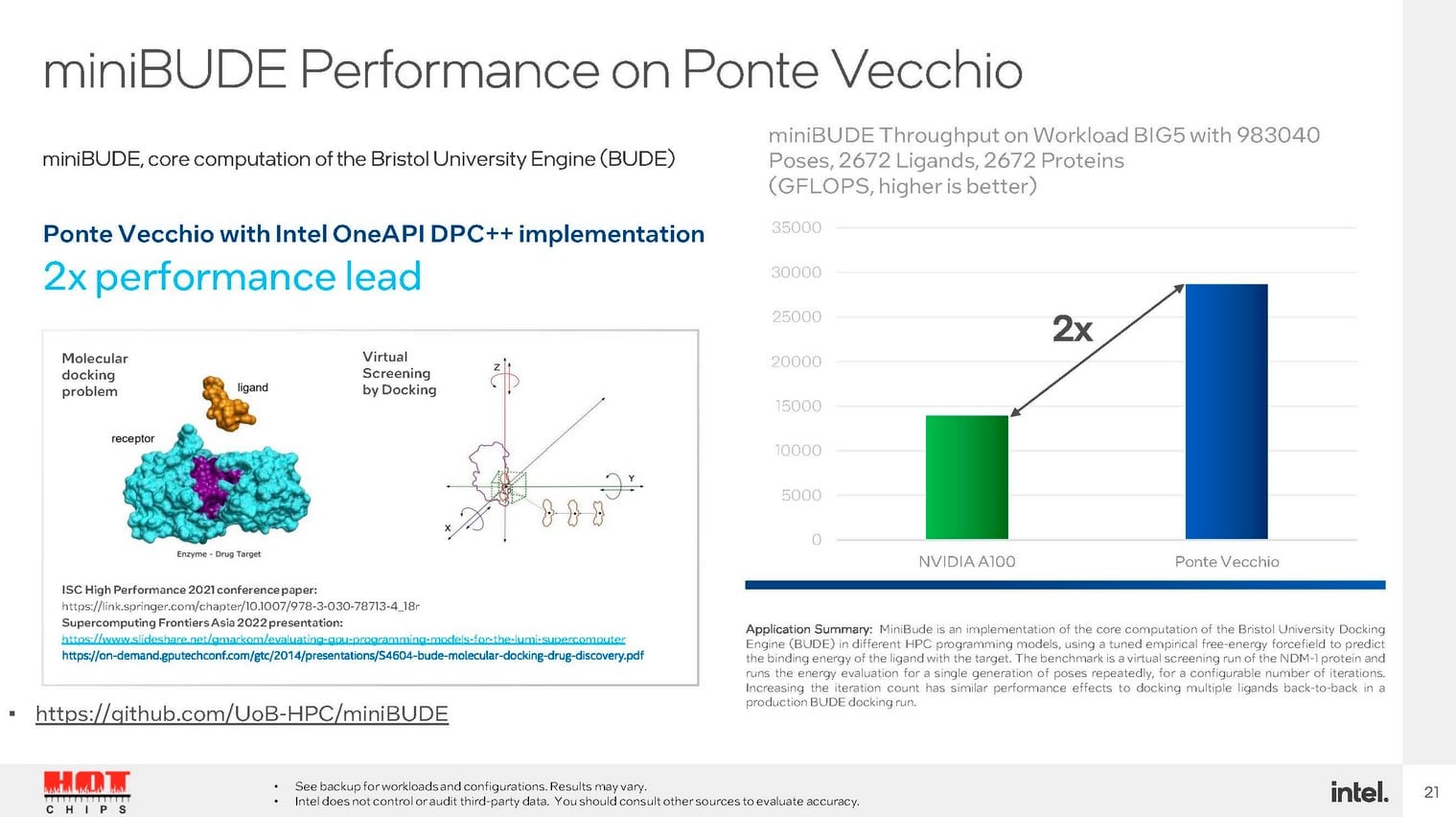
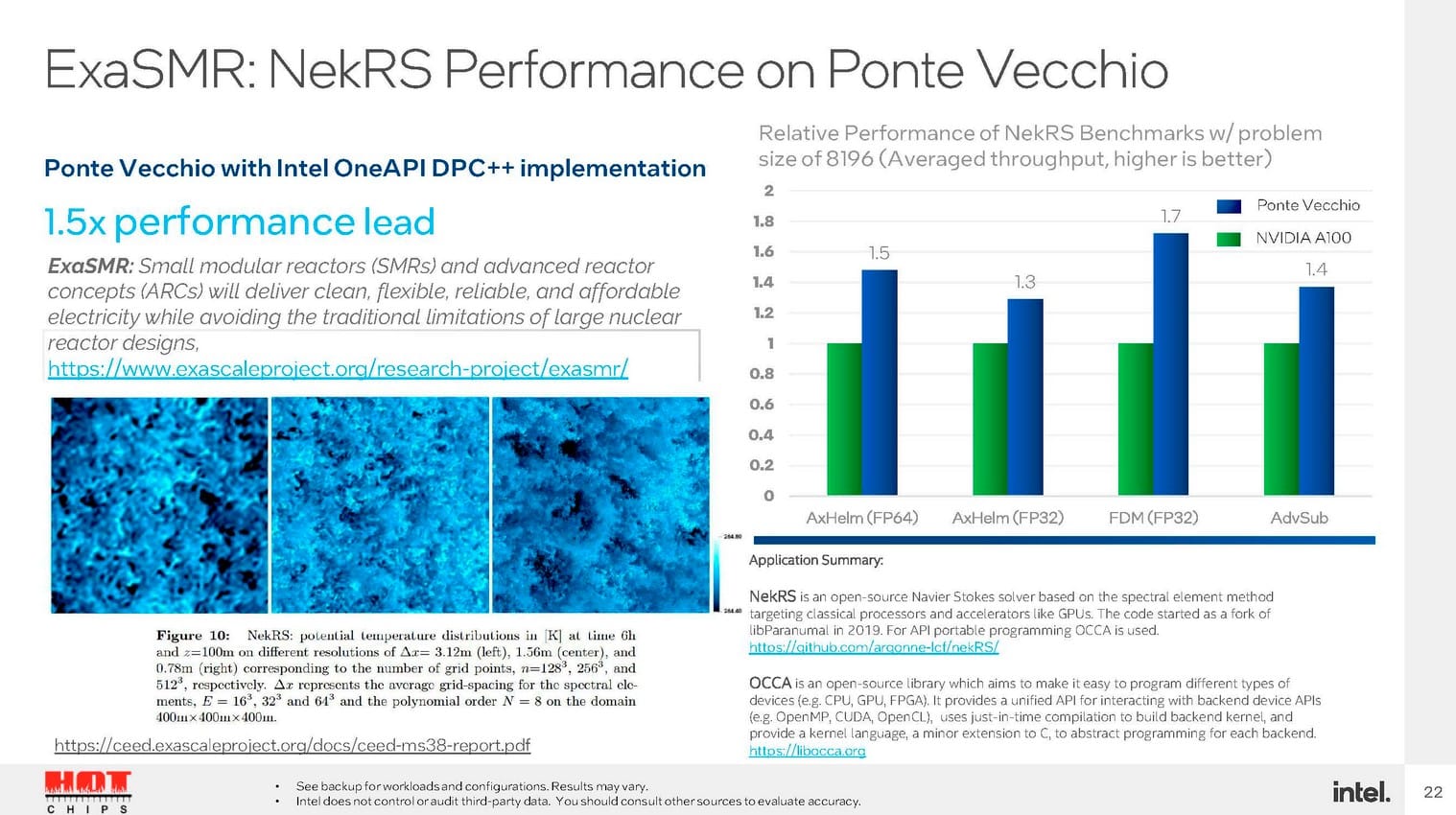
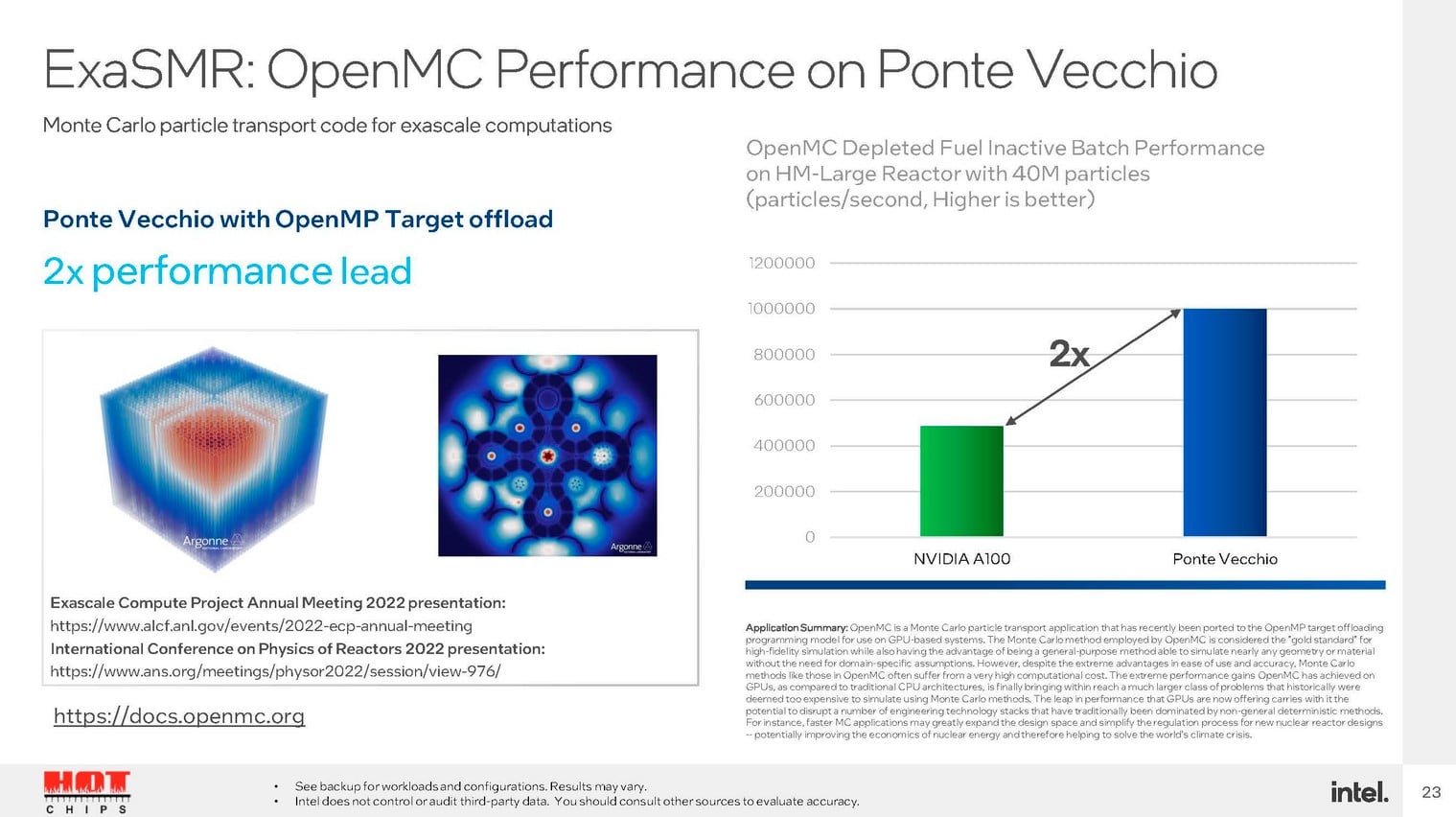
Intel revendique une avance x2 dans miniBUDE et de 1,5x dans ExaSMR par exemple. Seulement gardons à l’esprit que l’A100 est commercialisé depuis 2020.

Biren BR100 : un « GPGPU » chinois plus performant que l’A100 Ampere de NVIDIA
Au niveau de la concurrence ?
Lorsqu’il sortira, Ponte Vecchio devra plutôt rivaliser avec les solutions NVIDIA basées sur le GPU H100 (Hooper). Il n’y a pas beaucoup de données de performance pour ce GPU, mais NVIDIA annonçait des gains compris entre 50 % et 500 % en fonction des charges de travail par rapport à l’A100 au moment de sa présentation en mars dernier.
Du côté d’AMD, les accélérateurs AMD Instinct MI200 seraient déjà des concurrents sérieux aux GPU Ponte Vecchio. Or, la société prépare des APU Instinct MI300 Zen 4 / CDNA 3 ; elle évoque des performances jusqu’à 8 fois supérieures.

Bref, vous l’aurez compris, sur la base des données communiquées ici, ce GPU Ponte Vecchio semble mal parti pour rivaliser avec les nouvelles générations de produits NVIDIA et AMD.
Enfin, Intel déclinera Ponte Vecchio sous trois formats : OAM, sous-système x4 avec liens Xe, et sous-système x4 avec liens Xe sur une plateforme Sapphire Rapids à deux sockets. Ces processeurs ont pris pas mal de retard : aux dernières nouvelles, leur lancement est prévu en février ou mars prochain.
Accélérateurs GPU
| Nom GPU | AMD Instinct MI250X | NVIDIA Hopper GH100 | Intel Ponte Vecchio | Intel Rialto Bridge |
| Conception | MCM (Infinity Fabric) | Monolithic | MCM (EMIB + Foveros) | MCM (EMIB + Foveros) |
| Architecture GPU | Aldebaran (CDNA 2) | Hopper GH100 | Xe-HPC | Xe-HPC |
| Nœud de gravure | 6nm | 4N | 7nm (Intel 4) | 5nm (Intel 3)? |
| Cœurs GPU | 14 080 | 16 896 | 16 384 ALUs (128 cœurs Xe) | 20 480 ALUs (160 cœurs Xe) |
| Fréquence GPU | 1700 MHz | ~1780 MHz | À déterminer | À déterminer |
| Cache L2/L3 | 2 x 8 Mo | 50 Mo | 2 x 204 Mo | À déterminer |
| FP16 Compute | 383 TOPs | 2000 TFLOPs | À déterminer | À déterminer |
| FP32 Compute | 95,7 TFLOPs | 1000 TFLOPs | ~45 TFLOPs (A0 Silicon) | À déterminer |
| FP64 Compute | 47,9 TFLOPs | 60 TFLOPs | À déterminer | À déterminer |
| Mémoire | 128 Go HBM2E | 80 Go HBM3 | 128 Go HBM2e | 128 Go HBM3? |
| Vitesse mémoire | 3.2 Gbps | 3.2 Gbps | À déterminer | À déterminer |
| Bus mémoire | 8192-bit | 5120-bit | 8192-bit | 8192-bit |
| Bande passante mémoire | 3,2 To/s | 3,0 To/s | ~3 To/s | ~3 To/s |
| Facteur de forme | OAM | OAM | OAM | OAM v2 |
| TDP | 560W | 700W | 600W | 800W |
| Lancement | T4 2021 | 2S 2022 | 2022 ? | 2024 ? |

Sources : WCCFTech, Tom’s Hardware US











Intel devrait déjà être capable de sortir quelques choses de potable et concurrentiel sur ses gpu grand public avec ses arc XE DG2, avec des pilotes valable qui ont l’air catastrophique, ce qui n’est toujours pas bon actuellement.Donc si Intel veut qu’on le prenne au serieux, qui commence par la et les sortent partout dans le commerce, pour ses gpu pro de l’article, on voit bien que c’est la même galère, des annonces sans rien derrière depuis longtemps, il faudrait vraiment recruter une autre équipe que les raja koduri et compagnie pour faire enfin à la tâche, on a vu ce qu’ils ont fait avec AMD et là on le voit aussi chez Intel avec plus de moyen, donc le fruit est pourri, il faut le changer une bonne fois pour toute, la vision de Raja et compagnie pour les gpu, etc, n’est pas bonne peut importe la marque et budget.On espère qu’intel en prendra vite conscience si il veut faire quelques choses dans les gpu ou arrêter les frais, on est très nombreux à le penser.Dommage.