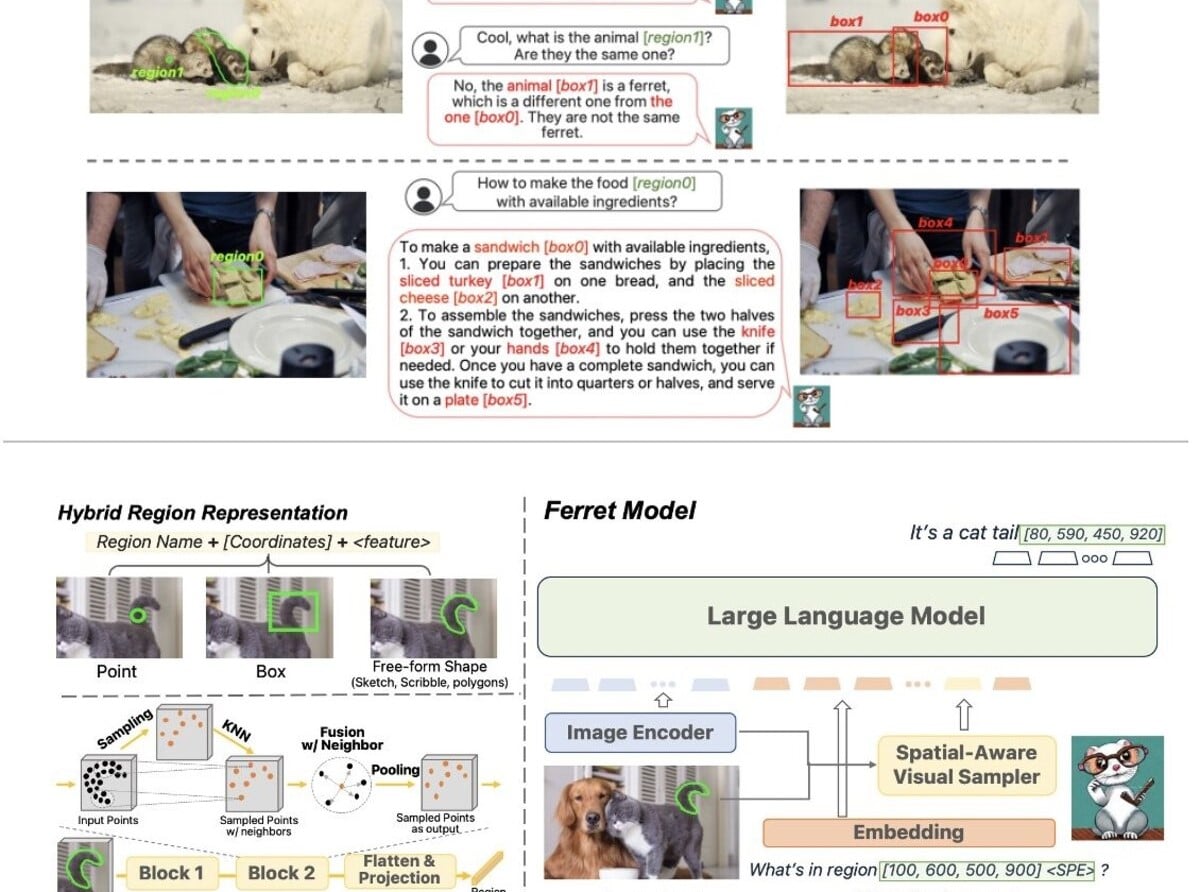
Apple argue qu’en matière d’analyse de petites zones d’image, son modèle Ferret est plus performant que GPT-4 d’OpenAI. En outre, l’entreprise le développerait spécifiquement pour les smartphones.
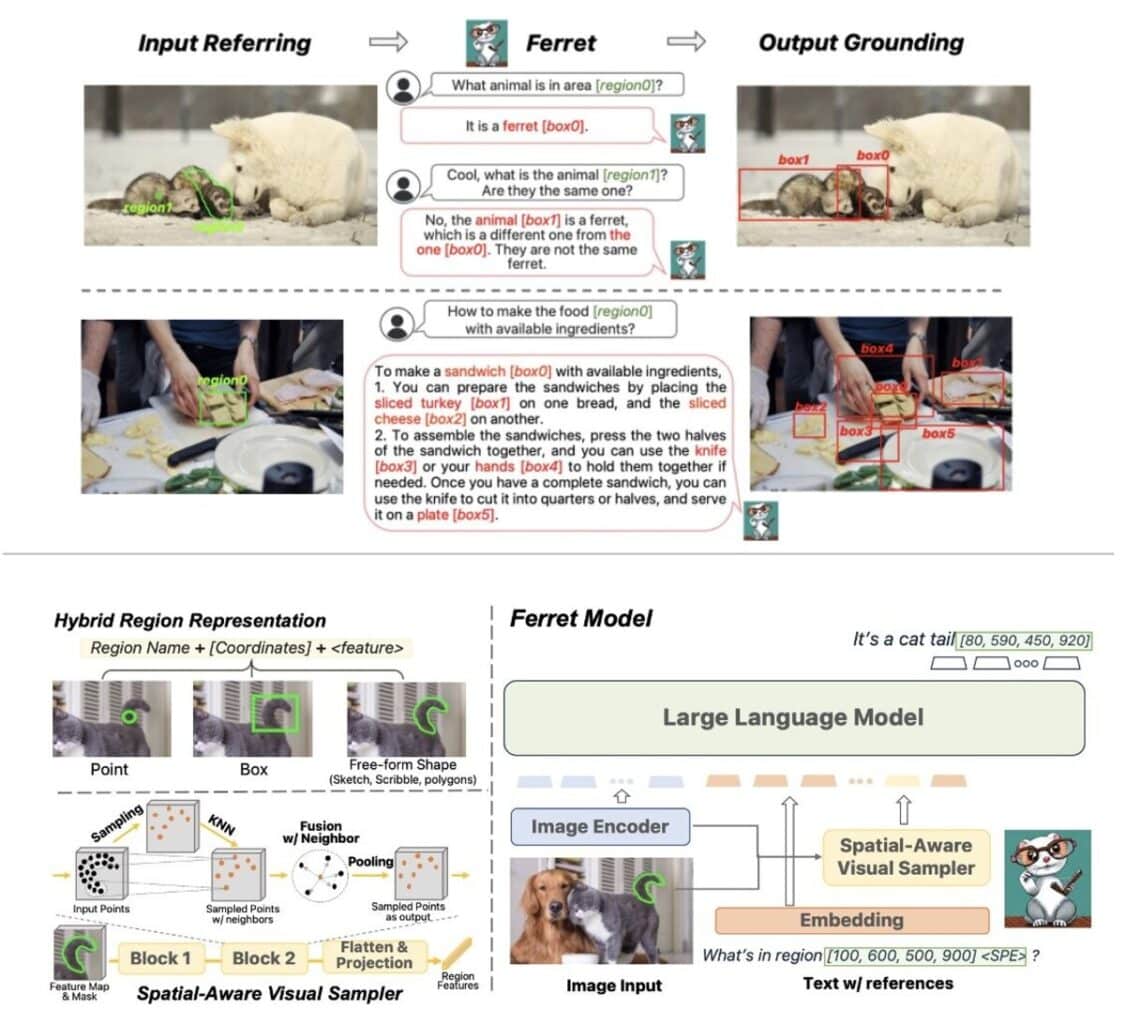
Dans la course à l’intelligence intelligence que se livrent les GAFAM (Google, Apple, Facebook, Amazon et Microsoft), la marque à la pomme se montre étonnement discrète face à ses concurrents. Pas d’inquiétude, elle prépare bien un MLLM (Multimodal Large Language Models), nom de code Ferret.
Tandis que Microsoft ne cesse d’introduire de l’intelligence artificielle partout notamment grâce à Copilot, et que Google présente en grande pompe – mais avec trucage – son IA Gemini, Apple se la joue bien plus discrète.
Ainsi, c’est sans clairon, via un simple message posté sur le réseau social X, que Zhe Gan, chercheur chez Apple AI/ML, avait officialisé Ferret, le MLLM de la firme de Cupertino, en octobre dernier. L’annonce avait donc confirmé qu’Apple développe sa propre intelligence artificielle mais était passée relativement inaperçue jusqu’à présent.
Ferret est entraîné sur 8 GPU NVIDIA A100
Ferret est développé conjointement par Apple et des chercheurs de l’université de Columbia. À en croire le message de Zhe Gan, Ferret est plus précis dans la compréhension et la description de petites zones d’images que GPT-4 d’OpenAI, tout en produisant moins d’hallucinations.
À ce stade, Ferret est un projet open source circonscrit à un usage de recherche. La page GitHub indique :
« Les données et le code sont destinés à un usage de recherche uniquement et font l’objet d’une licence. Ils sont également limités à des utilisations conformes à l’accord de licence de LLaMA, Vicuna et GPT-4. Le jeu de données est CC BY NC 4.0 (autorisant uniquement une utilisation non commerciale) et les modèles formés à l’aide du jeu de données ne doivent pas être utilisés en dehors du cadre de la recherche. »
La page nous apprend également le modèle IA est entraîné à l’aide de 8 GPU NVIDIA A100 avec 80 Go de mémoire HBM2e, soit des accélérateurs fournissant jusqu’à 2 To/s de bande passante. Pour être précis, deux modèles sont entraînés : l’un à 7 milliards d’hyper-paramètres, l’autre à 13.
Optimiser les LLM pour les smartphones
Sur la base d’un document de recherche publié le 12 décembre dernier et titré Efficient Large Language Model Inference with Limited Memory, les équipes d’Apple s’évertuent à faire fonctionner de grands modèles de langage sur des dispositifs ayant une capacité DRAM limitée, au premier rang desquels les smartphones. L’approche consisterait à optimiser les modèles et à compléter la mémoire vive avec un stockage flash consacré aux tâches IA.
Les auteurs rapportent que l’approche standard consiste à charger l’ensemble du modèle dans la DRAM pour l’inférence, mais que cette méthode limite considérablement la taille maximale du modèle qui peut être exécuté.
Ils donnent l’exemple d’un modèle à 7 milliards de paramètres, lequel nécessite plus de 14 Go de mémoire rien que pour charger les paramètres en format de virgule flottante en demi-précision. Or, ils soulignent qu’une capacité de 14 Go dépasse celle de la plupart des appareils actuels.
Les auteurs estiment que leurs méthodes permet « d’exécuter des modèles dont la taille est jusqu’à deux fois supérieure à celle de la mémoire vive disponible, avec une augmentation de la vitesse d’inférence de 4 à 5 fois et de 20 à 25 fois par rapport aux approches de chargement naïf dans le processeur et le processeur graphique, respectivement. »
De fait, la version complète de ChatGPT 4 d’Open AI utilise plus de 1 billion de paramètres et nécessite donc de puissants serveurs. L’IA Gemini de Google (susceptible de surpasser GPT-4 dans certaines tâches, à en croire l’entreprise) se décline sous une forme « Nano » pour les smartphones réduisant les modèles à 1,8 milliard (Nano-1) ou 3,6 milliards (Nano-2) de paramètres.
Côté SoC, pour le plus puissant du moment, à savoir le Snapdragon 8 Gen 3, Qualcomm promet une prise charge de 10 milliards de paramètres par l’appareil pour les modèles d’IA générative.











