Le premier accélérateur GPU à bénéficier de l’architecture CDNA de l’entreprise.
Vous en souvenez certainement, en mars dernier, AMD promouvait son architecture GPU CDNA, remplaçante de l’architecture Vega, destinée au secteur de calcul haute performance (HPC) pour l’IA. Quelques semaines plus tard, apparaissait l’accélérateur Radeon Instinct MI100. Le voici désormais officialisé par AMD. Il s’arme de 32 Go de mémoire HBM2 cadencée à 1,2 GHz pour une bande passante mémoire de 1,23 To/s.
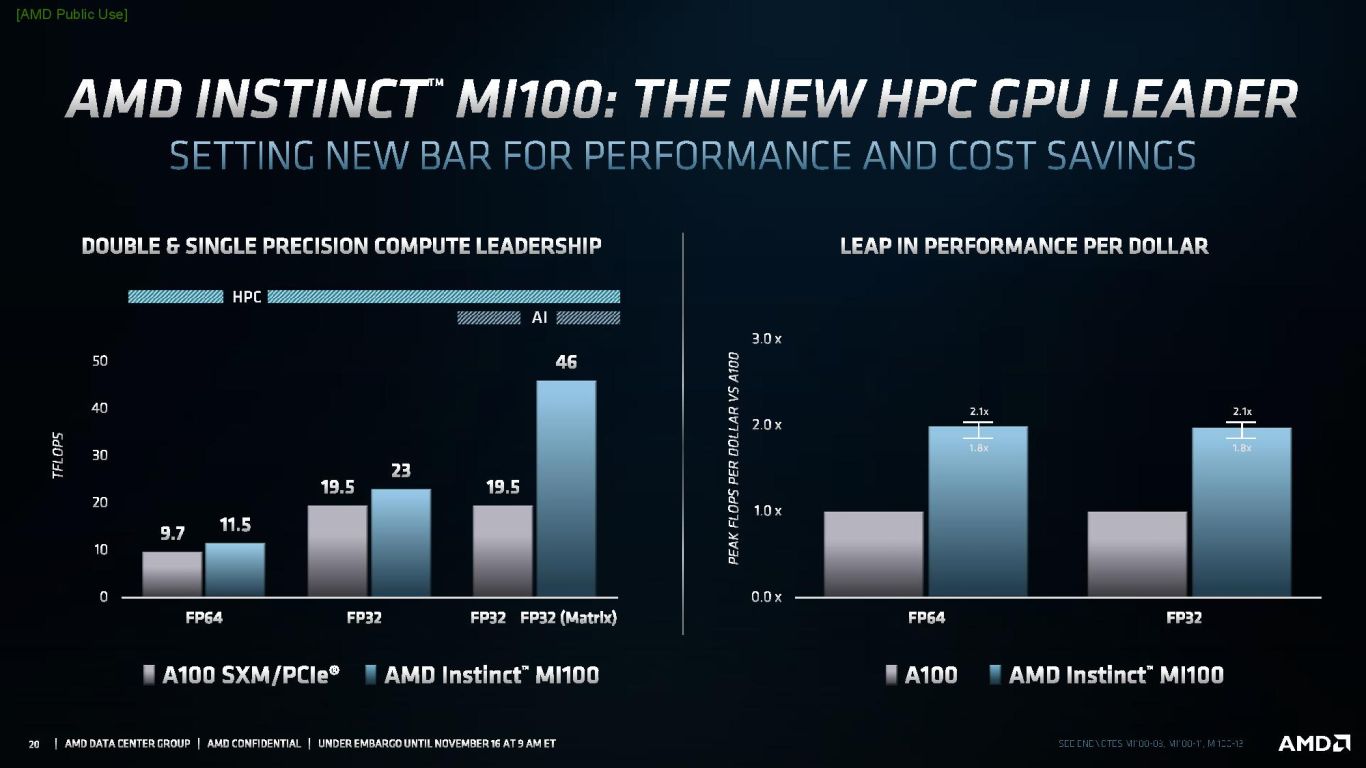
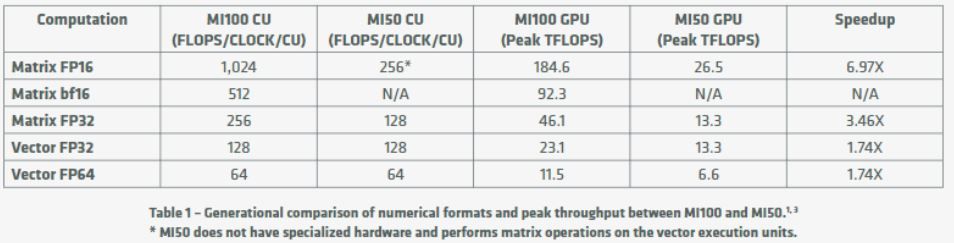
Selon AMD, ce Radeon Instinct MI100 est le “GPU HPC le plus rapide au monde mais aussi du premier GPU serveur x86 à dépasser la barrière des 10 TFLOPS de performance (FP64) […]. L’accélérateur MI100 offre jusqu’à 11,5 TFLOPS de performance FP64 en pointe et jusqu’à 46,1 TFLOPS de performance en pointe FP32 Matrix pour les scénarii d’IA et d’apprentissage machine. Avec la nouvelle technologie AMD Matrix Core, le MI100 offre également, face à la précédente génération d’accélérateurs AMD3, un boost de 7x les performances de pointe en virgule flottante FP16 pour les tâches d’entrainement de l’IA”.
ROCm 4.0 et Infinity Fabric de seconde génération
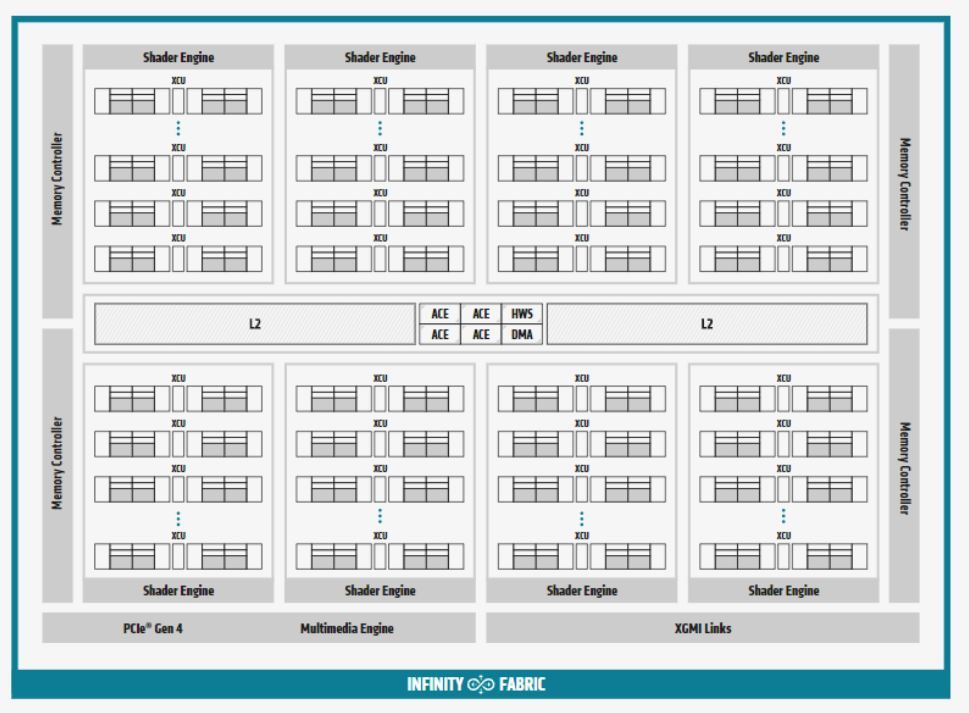
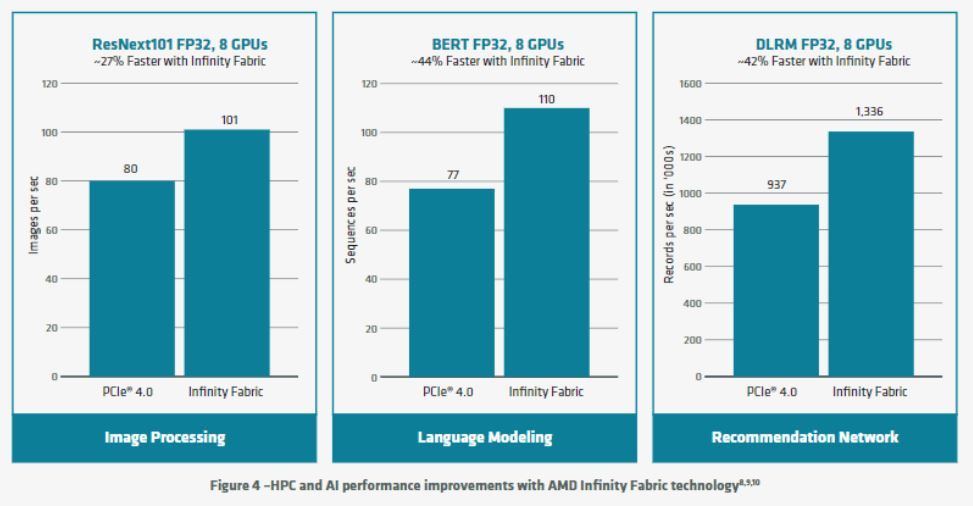
Outre leur architecture AMD CDNA, le MI100 profite d’une prise en charge du PCIe Gen 4.0 et de la technologie AMD Infinity Fabric de deuxième génération. Il permet ainsi “jusqu’à 340 Go/s de bande passante agrégée par carte avec trois liens AMD Infinity Fabric. Dans un serveur, les GPUs MI100 peuvent être configurés avec jusqu’à deux ruches complètement connectées de quatre GPU, chacune proposant jusqu’à 552 Go/s de bande passante”.


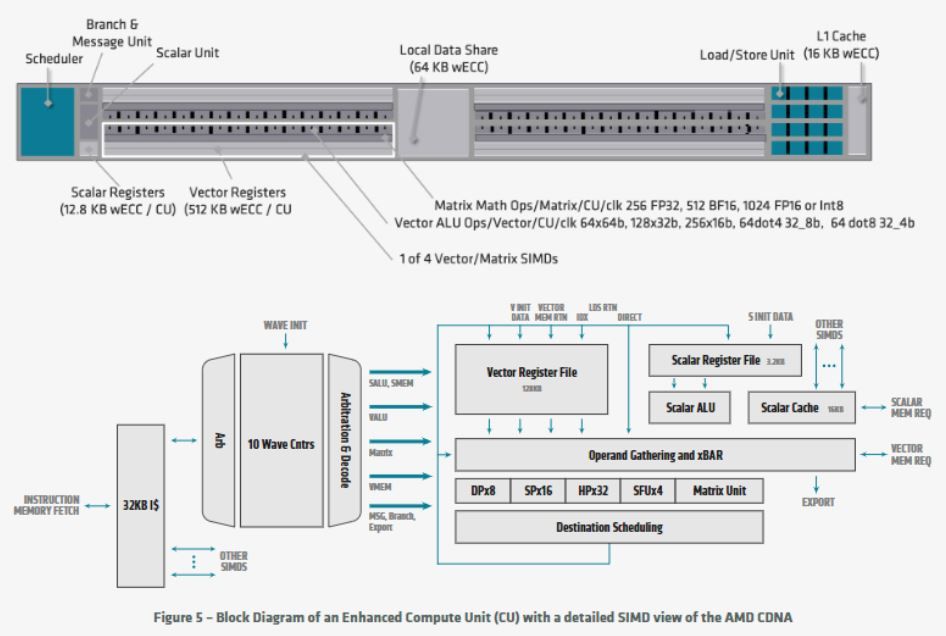
AMD met aussi en avant sa plateforme de développement AMD ROCm 4.0, un ensemble d’outils ouverts composé de compilateurs, d’API de programmation et de bibliothèques. Toujours selon AMD, “ROCm 4.0 profite d’un compilateur mis à jour pour être open source et unifié avec une prise en charge simultanée de OpenMP 5.0 et HIP”.
Tableaux comparatifs
Afin de faciliter la comparaison avec l’ancienne Instinct MI50 et les solutions concurrentes NVIDIA A100 (récemment enrichies d’une variante avec 80 Go de mémoire HMB2), nos confrères de Tom’s Hardware US proposent les tableaux suivants :
| GPU | Fréquence de pointe | Processeurs de flux | TDP | Mémoire (HBM2) | Bande passante mémoire | Interface PCIe |
| 7nm Instinct MI100 | 1502 MHz | 7680 (120 CU) | 300W | 32 Go | 1,23 To/s | 4.0 |
| 7nm Instinct MI50 | 1725 MHz | 3840 (60 CU) | 300W | 32 Go | 1,024 To/s | 4.0 |
| 7nm Nvidia A100 (PCIe) | 1410 MHz | 6912 | 250W | 40 Go | 1,555 To/s | 4.0 |
| 7nm Nvidia A1000 (HGX) | 1410 MHz | 6912 | 400W | 40 Go | 1,555 To/s | 4.0 |
| GPU | FP64 | FP32 | Matrix FP32 | Matrix FP16 | INT4/INT8 | bFloat16 |
| 7nm Instinct MI100 | 11,5 TFLOPs | 23,1 TFLOPS | 46,1 TFLOPS | 184,6 TFLOPS | 184,6 | 92,3 |
| 7nm Instinct MI50 | 6,6 TFLOPS | 13,3 TFLOPS | 13,3 TFLOPS | 26,5 TFLOPS | – | – |
| 7nm Nvidia A100 (PCIe) | 9,7 TFLOPS | 19,5 TFLOPS | 156 TFLOPS (Tensor) | 312 TFLOPS | 624 / 1 248 (Cœurs Tensor) | 624 / 1 248 (Cœurs Tensor) |
| 7nm Nvidia A1000 (HGX) | 9,7 TFLOPS | 19,5 TFLOPS | 156 TFLOPS (Tensor) | 312 TFLOPS | 1 248 (Cœurs Tensor) | 1 248 (Cœurs Tensor) |
Enfin, AMD précise que ses accélérateurs AMD Instinct MI100 débarqueront d’ici la fin d’année dans des systèmes proposés par les partenaires OEM et ODM ; cela comprend Dell, Gigabyte, Hewlett Packard Enterprise et SuperMicro.