Introduction
Une des traditions du petit monde de la 3D est l’arrivée simultanée d’une révision majeure de l’API DirectX et d’un GPU NVIDIA intégrant ses dernières fonctionnalités. C’était le cas avec DirectX 7 et la GeForce, avec DirectX 8 et la Geforce 3 puis plus proche de nous avec DirectX 10 et la GeForce 8800. En fait il faut remonter très précisément 7 ans en arrière pour que cette habitude soit brisée, ATI ayant coupé l’herbe sous le pied de son rival en sortant la fameuse Radeon 9700 Pro avant même l’arrivée de DirectX 9. Les générations suivantes ont été moins heureuses pour ATI avec notamment des R520 et R600 connaissant de gros retards conduisant le Canadien à changer de stratégie. Ainsi avec le RV770 AMD a choisi d’abandonner le traditionnel GPU monolithique pour s’orienter vers une architecture privilégiant la performance par watt et la performance par mm² de die.
La solution mise en place a connu un indéniable succès et un an plus tard AMD revient sur le devant de la scène avec un successeur qui arrive juste à temps pour l’arrivée de Windows 7 et surtout de DirectX 11. Doit-on voir dans ce timing parfait un heureux présage, le nouveau né marchant dans les pas du R300 ?

Les Radeon HD 5800
Avec le RV870 AMD a procédé à une mise à jour massive de son précédent GPU en termes de performance brute. C’est bien simple quasiment toutes les unités ont été doublées par rapport au RV770. Là où ce dernier proposait 800 unités de calculs à 750MHz, le nouveau venu en offre 1600 à la fréquence de 850 MHz affichant ainsi fièrement une puissance de calcul théorique de 2,72 TFlops pour la HD5870, le nouveau haut de gamme de la marque. Comparativement à la Radeon HD 4870 et ses 1,2 TFlops, cela correspond donc à une multiplication par 2,26. Un gain que nous avons pu vérifier au centième près sous Fillrate Tester.
Nous avions souvent reproché à AMD dans ses architectures précédentes de trop placer l’accent sur les performances des unités de calcul au détriment des ROP et des unités de texture. Avec le RV770 un premier pas en la matière avait été effectué en proposant 40 unités de textures au lieu des habituelles 16 des GPU haut de gamme de la marque mais le nombre de ROP était pour sa part resté figé à 16. Avec le RV870 AMD répond à nos attentes en doublant le nombre d’unités de texture qui passe donc à 80 mais en doublant également le nombre de ROP qui passe donc (enfin !) à 32 (c’est d’ailleurs ce qui nous permet d’obtenir le grahe précédent). Avec ces deux ajustements la nouvelle architecture d’AMD se place au même niveau que le haut de gamme actuel de NVIDIA en attendant de voir ce que la prochaine génération de GPU de la firme au caméléon nous réserve.
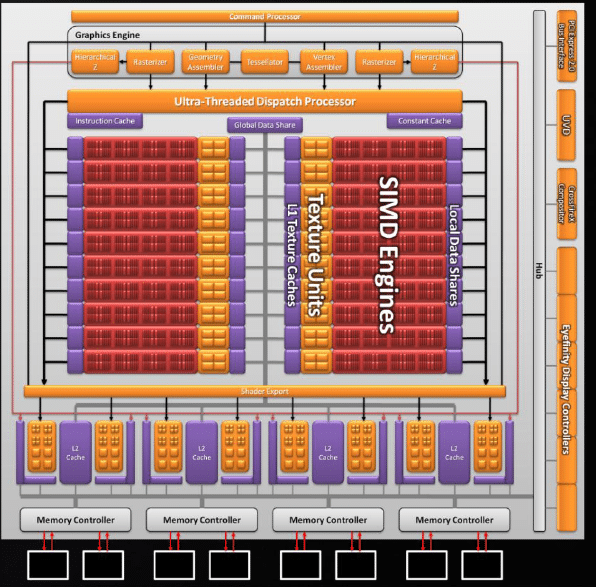
Avec cette augmentation substantielle de puissance brute à tous les niveaux de son GPU, il n’est pas étonnant de voir le nombre de transistors exploser vers de nouveaux records, en l’occurrence 2,15 milliards de transistors pour ce nouveau RV870 ! Les 1.4 milliards du GT200 sont oubliés et même le futur Tukwila, la prochaine génération de processeurs Itanium d’Intel, avec ses 2 milliards de transistors est battu. Pourtant une telle débauche de transistors n’a pas fait oublier à AMD les principes introduits par le RV770 : conserver une surface de die réaliste afin de se positionner de façon pertinente sur le marché en termes de rapport qualité/prix. Grâce à l’utilisation d’un procédé de gravure 40 nm la surface de die n’augmente ainsi dans le même temps que de 27 % par rapport au RV770, passant de 263mm² sur ce dernier à 334mm² pour le RV870.
Si la performance par mm² de die était un des deux axes introduits par AMD avec le RV770 qui a été reconduit avec le RV870, le second était la performance par watt et à ce niveau encore AMD reste fidèle à son architecture précédente. La consommation totale de la carte connaît une augmentation modérée selon les tests menés par les ingénieurs de la marque, passant de 160W sur les 4870 à 188W pour la 5870. Mais c’est surtout au repos que les améliorations d’AMD ont porté leurs fruits : la carte ne consomme ainsi plus que 27W soit moins du tiers de la génération précédente. Evidemment il ne faut pas prendre ces chiffres pour argent comptant et vous verrez les résultats que nous avons obtenus dans la suite de ce test.
L’architecture en détail : unités de calcul
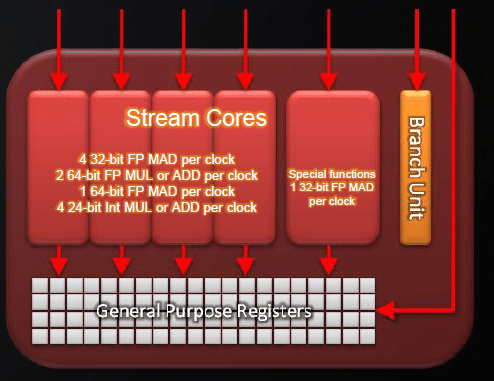
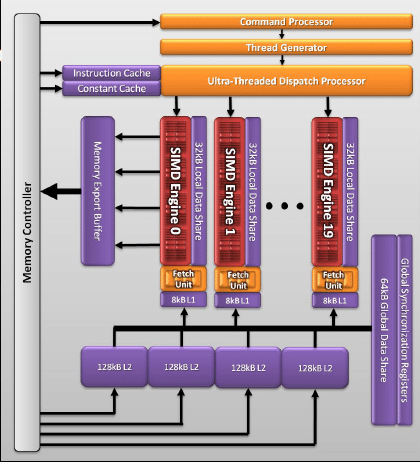
Tout comme le RV770 reprenait largement l’architecture du RV670, une fois encore il ne faut pas s’attendre à un énorme bouleversement en termes d’organisation des différentes unités de calcul. On retrouve donc à la base les SIMD arrays introduits avec le R600 (même si une forme préliminaire était déjà apparue avec le Xenos, le GPU de la Xbox 360) dont le nombre passe désormais à 20. Mais les ingénieurs ne se sont pas contentés d’augmenter le nombre d’unités, ils les ont également peaufinés pour optimiser leurs performances.
Comme nous l’avions vu dans notre test du RV770 les unités de calcul des puces ATI sont de type VLIW (Very Long Instruction Word). Ce type d’architecture repose sur le compilateur pour gérer les dépendances entre les instructions, simplifiant ainsi les unités d’exécution. Cette simplification a un coût puisque dans certains cas des unités d’exécution restent inutilisées. Avec le RV870 les ingénieurs d’AMD ont tenté de limiter ce type de situations où l’utilisation des unités n’est pas optimale : la puce est désormais capable d’exécuter une multiplication et une addition dépendante du résultat de l’opération précédente dans le même cycle. Par exemple les deux instructions suivantes :
a=b*c;
d=a+x;
N’auraient pas pu partager le même bundle d’instructions sur le RV770, alors que c’est désormais le cas sur le RV870 qui transforme ces deux opérations en un MAD tout en conservant le résultat de la multiplication intermédiaire. De la même façon le RV770 ne disposait que d’une instruction DP4 (produit scalaire à 4 composantes) les instructions DP2 et DP3 étant implémentés en utilisant cette instruction. Le résultat de ce design était donc un gâchis de certains slots du bundle avec des opérations inutiles. AMD indique que désormais la gestion des produits scalaires est plus flexible, sans plus de détails. On peut supposer que les ingénieurs aient implémentés nativement des instructions DP2 et DP3 afin de permettre d’effectuer d’autres calculs en parallèle.
La gestion des opérations sur les entiers a également été modifiée : auparavant chacune des 4 unités de calcul pouvait effectuer une addition ou un décalage de bits sur un entier 32 bits par cycle, et l’unité spéciale pouvait effectuer une multiplication ou un décalage de bits également sur un entier 32 bit. Désormais les 4 unités de base sont capables d’effectuer une multiplication ou une addition entière par cycle mais uniquement sur des entiers 24 bits. Ce choix résulte d’un compromis entre la volonté d’augmenter les performances dans le cas général tout en ne sacrifiant pas trop de ressources comme l’aurait demandé la présence d’un multiplicateur entier 32 bits complet dans chacune des 4 unités. En effet, en se limitant à des opérations 24 bits les ingénieurs peuvent réutiliser les ressources utilisées pour la gestion des nombres flottants simple précision tout en couvrant une majorité de cas d’utilisation des entiers dans un shader.
Outre ces optimisations les ingénieurs ont introduits deux nouvelles instructions, une instruction de multiplication-addition fusionnée (FMAD) qui maintient la précision du calcul tout du long et n’effectue qu’un seul arrondi final contrairement à une multiplication-addition (MAD) classique qui effectue deux arrondis. La seconde instruction est une somme de différences absolues (SAD) qui est une opération très fréquente dans le domaine de la vidéo notamment pour effectuer des comparaisons entre des blocs de pixels. Vérifions maintenant l’augmentation de cette puissance de calculs via différents shaders.
Si nous avons conservé le gain de 2,26 fois entre la 4870 et la 5870 sur la plupart des shaders simples et DirectX 9 que nous avons lancés, celui-ci est réduit à 1,68 lors de l’ajout d’un éclairage par pixel.
Passons maintenant à des shaders plus complexes et actuels, sous DirectX 10.0 :
Avec des textures procédurales, le gain en puissance brute est quasiment entièrement retrouvé en pratique puisque la 5870 s’avère 2,24 fois plus rapide que la 4870. Pas de doute, les 1600 stream processors sont donc bien là et disponibles !
Rasterizers, unités de texture, ROP
Deux rasterizers ? Pas vraiment
Dans sa description d’architecture AMD laisse une ligne ambigüe indiquant simplement « dual rasterizers ». Comme vous le savez certainement les GPU actuels ne sont capables de rastériser qu’un seul triangle par cycle, cette limite intrinsèque est d’ailleurs désormais devenue la principale cause de bridage des performances lors des tests synthétiques de géométrie sur les architectures à shaders unifiés.
En découvrant cette nouvelle architecture nous avions donc initialement cru qu’AMD avait trouvé un moyen de paralléliser le setup ce qui aurait été particulièrement adapté à un GPU qui mise beaucoup sur la tesselation, technique générant un nombre important de triangles. Les options pour rastériser plusieurs triangles en parallèle ne manquent pas mais sont assurément complexes sur un GPU de type Sort-Last Fragment : les problèmes de synchronisation sont nombreux et ont des implications à plusieurs niveaux, nous étions donc curieux de savoir comment AMD avait résolu ce casse tête. Malheureusement la réponse fut une déception : il y avait eu un petit abus de langage, en pratique il n’y a toujours qu’un seul rasterizer, acceptant un unique triangle par cycle. En revanche il y a désormais deux fois plus d’unités de scan conversion, les unités générant les pixels à un rythme de 32 pixels par cycle afin d’égaler l’augmentation du nombre de ROP. Plutôt que deux rasterizers il faut donc plutôt voir ça comme un rasterizer plus puissant.
Tant que l’on parle du setup et de la rastérisation il convient de souligner une nouveauté : les unités fixes qui se chargeaient des calculs d’interpolation ont disparu, ce rôle incombe désormais aux unités de calcul des shaders. AMD assure que l’impact sur les performances est négligeable et cela s’inscrit dans la tendance actuelle visant à se débarrasser au maximum des unités fixes et à tirer profit des énormes capacités de calcul des GPU modernes.
Unités de textures
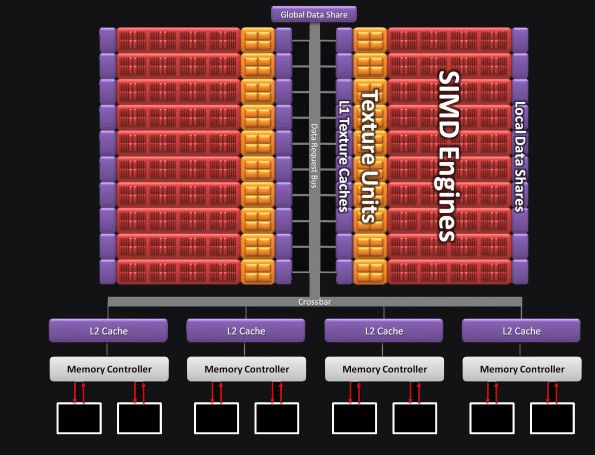
Si les unités de calcul n’ont pas été fondamentalement bouleversées, c’est encore pire du côté des unités de texture qui n’ont pratiquement pas bougé par rapport au RV770. En pratique à part le support des textures 16kx16k et de deux nouveaux formats de compression de texture, tous deux nécessaires pour être compatibles DirectX 11, il n’y a rien de nouveau. L’utilisation du Steep Parallax Mapping est d’ailleurs assez claire à ce sujet :
Les drivers semblent en outre amener une très légère optimisation puisque le gain que nous avons mesuré ici (mais également sur d’autres shaders comme Fur) monte à 2,35 entre les deux Radeon.
En revanche, les performances sur les Geometry Shaders (puissance géométrique) ne sont améliorées que de 42 % ici.
Ce dernier test mesure enfin les performances d’accès aux textures (utile pour le displacement mapping notamment). Celles-ci sont également en amélioration modeste, de 34 %.
Or il faut savoir que si le cache L1 voit sa bande passante totale augmenter, celle-ci ne progresse que d’un facteur deux exprimant en fait de façon différente l’augmentation du nombre d’unités de texture. De la même façon le cache L2 a vu sa taille doublée mais là aussi cela ne traduit qu’une adaptation au nombre d’unités plus élevé. Pire encore la bande passante L2/L1 n’augmente pour sa part que proportionnellement à la fréquence alors qu’il y a désormais deux fois plus d’unités à alimenter ! Il est donc probable que nous venions de mettre le doigt sur une des causes empêchant le RV870 d’offrir des performances doublées par rapport à son prédécesseur dans les deux tests intensifs de texture précédents.
ROP
Encore une fois peu de nouveautés du côté des ROP, AMD a tout simplement optimisé le lien entre les ROP et les unités de texture, permettant à ces dernières de lire directement le format compressé utilisé lors de l’activation de l’antialiasing. Cette fonctionnalité déjà présente dans les GPU NVIDIA devrait permettre d’obtenir de meilleures performances lors des opérations de post traitement sur le framebuffer.
En dehors de cela on retrouve exactement les mêmes caractéristiques que sur le RV770 à savoir un rendement maximal lors de l’utilisation d’antialiasing 2X ou 4X (32 pixels/cycle) qui est réduit de moitié lors de l’utilisation d’antialiasing 8X (16 pixels /cycle). Il n’y a pas eu d’optimisation non plus du côté des passes de rendu Z uniquement qui sont toujours effectuée 4 fois plus rapidement (128 pixels/cycle).
Direct3D 11
Comme nous venons de le voir si la puissance brute de ce nouveau GPU a connu une sérieuse remise à niveau, les bases de l’architecture n’ont pas vraiment évoluées depuis le RV770. Cependant il ne faut pas négliger le fait que ce nouveau GPU est le premier à supporter la toute dernière API graphique de Microsoft : Direct3D 11 il est donc temps de nous attarder sur les nouveautés de cette API.
Avec Direct 3D 10 Microsoft promettait une petite révolution et le moins qu’on puisse dire est que la transition s’est faite dans la douleur. Les raisons de ces difficultés sont multiples : tout d’abord Direct3D 10 imposait des changements radicaux par rapport à son prédécesseur ce qui imposait aux programmeurs, bien rodés à DirectX 9 après des années de pratique, de réapprendre les nouvelles bonnes façons de procéder pour obtenir le meilleur de l’API.
Un autre problème de Direct3D 10 venait de son lien exclusif à Windows Vista. Sans entrer dans un débat sur la qualité de cet OS il faut objectivement reconnaître que son succès n’a pas vraiment été à la hauteur des attentes, particulièrement chez les joueurs. En conséquence la base installée de plateformes supportant la dernière API de Microsoft est restée relativement limitée. Du côté des développeurs les choses n’étaient pas vraiment roses non plus, Drect3D 10 n’était compatible qu’avec les GPU Direct3D 10, comme une grosse majorité de joueurs utilisaient encore des cartes DirectX 9 les développeurs devaient donc écrire deux versions différentes de leurs moteurs : une pour chaque API et comme le fonctionnement des deux API était largement différent il ne s’agissait pas vraiment d’une tâche triviale pouvant se réduire à quelques directives au processeur pour interchanger les appels d’API.
Avec Direct3D 11 Microsoft a reconnu les erreurs commises avec sa précédente API et tenté d’y remédier. Pour résoudre le problème que nous évoquions, la firme de Redmond a introduit un système de feature levels, permettant d’utiliser un GPU DirectX 9, Direct3D 10 ou Direct3D 10.1 par l’intermédiaire de l’API de Direct3D 11. Evidemment ce n’est pas magique : l’utilisation de Direct 3D 11 sur un GPU DirectX 9 ne lui permettra pas de supporter les dernières fonctionnalités introduites par l’API, il faudra se limiter au sous ensemble supporté par le hardware. Ceci simplifiera tout de même grandement la tâche des programmeurs souhaitant supporter un large parc de hardware. Pas de miracle en revanche : Direct3D 11 reste lié à Windows Vista et à Windows 7, mais l’arrivée de ce dernier, dont les premières évaluations sont particulièrement enthousiastes devraient finir de convaincre les derniers amoureux de Windows XP d’abandonner enfin leur OS fétiche.
Nous avons déjà consacré un dossier à Direct3D 11 il y a environ un an, vous pouvez le consulter pour avoir une idée des nouveautés introduites par l’API mais depuis cette introduction basée sur les présentations de Microsoft à la GameFest le SDK a été rendu disponible et de plus amples détails sont accessibles nous allons donc compléter les informations de notre précédent dossier.
Shader Model 5 : de nouvelles instructions
Comme à chaque nouvelle version Microsoft introduit à son langage de shaders de nouvelles instructions le rendant plus flexible. Parmi celles-ci on trouve ainsi une nouvelle valeur disponible en entrée d’un Pixel Shader : SV_Coverage, qui permet de connaître quels échantillons d’un pixel sont couverts par une primitive. Cela ouvre des possibilités intéressantes comme notamment une façon rapide de déterminer si on se situe sur les bords d’une primitive (si tous les échantillons n’ont pas la même valeur).
L’instruction Gather4 qui permet de récupérer 4 valeurs d’une texture à un composant avec un seul adressage de texture a vu ses fonctionnalités étendues : il est désormais possible de l’utiliser dans les textures à plusieurs composants en spécifiant le canal (rouge, vers, bleu, alpha) que l’on souhaite récupérer.
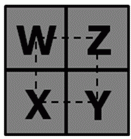
Les fonctions de dérivée partielles qui sont utiles pour implémenter des filtrages de texture particuliers sont complétées par de nouvelles instructions permettant d’obtenir une approximation plus rapide.
Microsoft a également ajouté un tas d’instructions de manipulation de bit qui si elles n’étaient pas forcément utiles dans le domaine graphique feront le bonheur des adeptes du GPGPU en permettant d’accélérer tout un tas de technique de compression/décompression des données par exemple. Un support optionnel des nombres flottant double précision a également été mis en place et enfin on trouve des instructions de conversion des nombres flottants 32 bit (single précision) en flottants 16 bit (half precision).
DirectCompute, buffers
La grosse nouveauté de Direct3D 11 sur laquelle nous étions rapidement passés lors de notre précédent dossier est donc l’arrivée des fameux Compute Shaders. Contrairement aux autres shaders ces derniers sont indépendants du pipeline 3D, à l’image de CUDA ou d’OpenCL le but est de permettre d’utiliser la puissance de calculs des GPU pour effectuer des calculs génériques, on parle de GPGPU. L’interface proposée est d’ailleurs proche de celle offerte par les deux autres API mais le gros avantage de l’API DirectCompute par rapport à ses rivales, est son intégration dans Direct3D ce qui devrait en faire l’API de choix pour le GPGPU dans le cas des jeux qui reposent déjà sur cette API pour la partie 3D.
Par rapport aux autres shaders, les Compute Shaders offrent plusieurs avantages : comme ils ne sont pas intégrés au pipeline 3D ils n’ont pas d’entrée/sortie fixe, dicté par l’interface avec le reste du pipeline. Un Compute Shader a également un accès totalement libre en lecture/écriture à une zone mémoire de 32 Ko (la TGSM : Thread Group Shared Memory) permettant d’échanger des données entre les threads. La bonne utilisation de cette zone mémoire est primordiale dans le cadre des Compute Shaders car ses performances sont largement supérieures à celles de la mémoire vidéo et surtout elle permet de réaliser des économies substantielles de bande passante par rapport à une implémentation utilisant les Pixel Shaders par exemple.
Enfin les deux dernières fonctionnalités des Compute Shaders, qui sont également disponibles dans les Pixel Shaders contrairement aux précédentes, concernent les accès aléatoires en écriture à la mémoire vidéo (scatter writes) et le support des opérations atomiques qui permettent de garantir que l’exécution des instructions sera effectuée dans l’ordre souhaité.
Si les 3 principales API de GPGPU ont leurs petites particularités de syntaxe, on retrouve dans chacune d’elle les mêmes concepts principaux : ainsi on parle à chaque fois de threads, de bloc de threads et de grilles de threads, les programmeurs ayant déjà pu expérimenter la programmation GPGPU avec CUDA ne devraient donc pas être dépaysés. Enfin une bonne nouvelle, l’API DirectCompute n’est pas réservée aux GPU DirectX 11, Microsoft a en effet défini plusieurs sous ensembles de fonctionnalités permettant d’utiliser l’API sur les GPU DirectX 10 ou DirectX 10.1.
Des buffers plus flexibles
Jusqu’ici les buffers de DirectX contenaient des types de données bien précis : des sommets dans le cas des Vertex ou des Geometry Shaders, des couleurs dans le cas des Pixel Shaders mais un Compute Shader n’a pas vraiment de type de données associés. Il peut travailler sur tout et n’importe quoi. Pour répondre aux besoins de ce type de shaders Microsoft a donc introduit avec Direct3D 11 plusieurs nouveaux types de données.
La première modification concerne les ressources (buffers ou textures). Alors qu’elles n’étaient accessibles qu’en lecture avec Direct3D 10 elles sont désormais accessibles en lecture/écriture. Autre nouveauté, l’introduction d’un nouveau type de buffers appelés Structured Buffer. Comme son nom l’indique ce buffer peut contenir des types de données définis par l’utilisateur : plus besoin donc de se limiter aux vecteurs de flottant ou d’entier, il est désormais possible pour le programmeur de créer une structure plus complexe contenant plusieurs types de données et ensuite d’y accéder dans un shader. On retrouve également un autre type de buffers : le Raw Buffer qui pour sa part contient des données 32 bit brutes, sans type.
Pour permettre des accès totalement aléatoires à la mémoire en lecture/écriture, Microsoft a introduit un nouveau type de vues appelé Unordered Access View qui peut être soit un buffer soit une texture, et qui n’est accessible que dans les Pixel Shaders et les Compute Shaders. Ces ressources peuvent être accédées simultanément en lecture/écriture par plusieurs threads sans générer de conflit mémoire grâce à l’utilisation des instructions atomiques qui garantissent que l’opération sur les données sera terminée avant qu’un autre thread puisse les modifier.
Dernière nouveauté, l’apparition des Append/Consume Buffer qui fonctionnent exactement comme une pile : on ajoute des éléments à la fin du buffer et on les retire également à la fin, c’est une structure de type LIFO (Last In First Out ou Dernier Entré Premier Sorti) qui est particulièrement utile dans le monde de l’informatique classique. La voir arriver dans les Shaders devrait donc simplifier la tâche des programmeurs pour adapter ce type d’algorithmes.
Exploitation et bilan
Exploitation : transparence indépendante de l’ordre
Toutes ces considérations techniques sont bien jolies mais en pratique à quoi ça sert ? Les possibilités sont vastes mais dans le domaine du jeu on peut envisager plusieurs scénarios : la gestion de la physique sur le GPU évidemment, le traitement d’image avec des performances supérieures à celles obtenues dans un pixel shader ou encore des algorithmes de rendu entièrement nouveaux comme le Raytracing, le Raycasting de voxels ou un rendu à base de micropolygones de type REYES.
Toutefois il ne faut pas s’attendre à voir ce genre de bouleversements se produire de sitôt. Plus proche de nous, AMD a présenté une démo particulièrement intéressante de rendu de transparence indépendante de l’ordre.


C’est un problème majeur dans le cadre de la 3D temps réel auquel aucune solution vraiment satisfaisante n’a été proposée. Essayons de comprendre un peu mieux ce qui se passe. Comme vous le savez le GPU prend en entrée une « soupe » totalement désordonnée de triangles et en effectue le rendu un triangle après l’autre. Pour être sûr que le rendu soit correct, le GPU se base sur l’algorithme du ZBuffer qui stocke une valeur de profondeur par pixel, le GPU ne dessine donc un triangle que s’il est plus proche de la caméra. Dans le cas d’un rendu totalement opaque cette solution fonctionne parfaitement mais dés lors qu’il y a des transparences l’algorithme du ZBuffer montre ses limites.
En effet lorsqu’un triangle transparent est rendu, s’il inscrit sa valeur de profondeur dans le ZBuffer tous les triangles qui sont derrière lui et devraient être visibles seront masqués, le rendu sera donc incorrect. Pour limiter ce problème une façon simple de précéder consister à effectuer le rendu de tous les triangles opaques dans un premier temps, puis de désactiver les écritures dans le ZBuffer et d’effectuer ensuite le rendu des triangles transparents. Le résultat n’est toujours pas correct car les triangles transparents ne sont toujours pas correctement ordonnés entre eux, le blending n’étant pas une opération commutative, mais au moins l’interaction avec les triangles opaques est exacte.
Pour obtenir un rendu parfait des surfaces transparentes il n’existe pas beaucoup de solution : l’une d’entre elle consiste à trier les triangles transparents sur le processeur et effectuer le rendu des plus éloignés vers les plus proches. Mais c’est extrêmement couteux car il faut le faire à chaque frame et de plus dans le cas d’interpénétrations de triangles le tri n’est pas correct. Des algorithmes ont donc été mis en place pour résoudre ce problème. L’un d’entre eux particulièrement original s’appelle le Depth Peeling. Il consiste à « éplucher » les surfaces transparentes les unes après les autres, et à les stocker dans des tampons intermédiaires avant de tout recombiner dans le bon ordre dans une dernière passe. Si obtenir la couleur du pixel le plus proche de la caméra est simple avec un ZBuffer, obtenir la valeur du second pixel le plus proche de la caméra est plus compliqué. L’algorithme repose donc sur l’emploi de deux tests Z par pixel : l’un traditionnel et le second afin d’éliminer les pixels déjà rendus jusqu’à présent. En d’autres termes on demande le pixel le plus proche de la caméra mais qui soit aussi plus éloigné de la caméra que celui que j’ai rendu lors de la passe précédente.
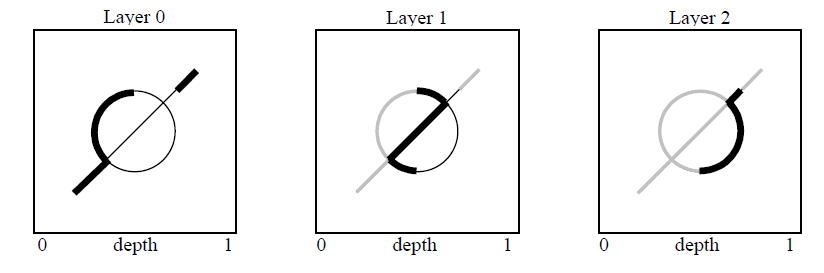
Comme il n’y a qu’un seul ZBuffer, l’algorithme détourne les depth map qui sont traditionnellement utilisées pour le rendu des ombres, afin de simuler un second test Z par pixel. Cette technique offre de bons résultats visuellement parlant mais comme tout algorithme multi-passes il s’avère relativement coûteux. De plus il impose d’utiliser plusieurs buffers pour stocker les résultats intermédiaires ce qui représente une place considérable en mémoire (dont une grande partie est gâchée) si beaucoup de surfaces transparentes se recouvrent. Cette solution ne s’est donc pas vraiment imposée.
Une autre approche, cette fois compatible avec les GPU DirectX 10 seulement, consiste à détourner le rôle des samples d’antialiasing pour stocker les couleurs des différentes surfaces transparentes recouvrant ce pixel avant d’effectuer ensuite une passe pour les trier dans le bon ordre. Cette technique appelée stencil routed A Buffer offre là encore des résultats visuellement satisfaisants mais présente plusieurs limites. En particulier le nombre de surfaces transparentes se recouvrant est limitée par le nombre de samples disponibles par pixel, c’est-à-dire généralement 8, pour obtenir plus de niveaux de transparences il faut donc effectuer plusieurs passes de géométrie. De plus en réutilisant les samples d’antialiasing cette technique est incompatible avec ce filtre.

Avec Direct3D 11 AMD a présenté une nouvelle technique de rendu de la transparence indépendante de l’ordre. Elle repose sur l’utilisation des Append Buffers et des instructions atomiques des Compute Shaders pour stocker, puis trier l’ensemble des surfaces transparentes par pixel. Les résultats obtenus sont intéressants : malgré la superposition de jusqu’à 64 niveaux de transparence par pixel, et plus de 600 000 polygones en tout, le framerate reste interactif.

Bilan
Avec le RV870 AMD a procédé à une mise à niveau importante de son GPU haut de gamme en doublant la plupart des unités : unités de calcul, unités de texture et ROP, ce qui devrait lui permettre de ravir à nouveau la couronne des performances (ce qui ne lui était pas arrivé depuis un moment avec une carte mono GPU). Mais les ingénieurs ne se sont pas arrêtés là et en ont profité pour apporter le support de la dernière API de Microsoft : Direct3D 11.
Le résultat de toutes ces améliorations est un GPU offrant des performances solides, le tout avec une consommation maîtrisée et le support des derniers raffinements 3D ce qui devrait lui assurer une certaine pérennité. Difficile de critiquer le travail des ingénieurs d’AMD donc même si au fond de nous nous sommes un peu déçus de voir au final si peu de modifications apportées à l’architecture générale. C’est compréhensible car celle-ci a déjà fait ses preuves avec le RV770 mais depuis plusieurs années on ne peut s’empêcher de se dire que le petit monde de la 3D ronronne : le GT200 n’était qu’une évolution du G80 mettant l’accent sur les performances brutes, et le RV870 se place un peu dans la même optique même s’il a pour lui le support de Direct3D 11. Espérons que l’arrivée de Larrabee relance la concurrence dans le domaine et incite NVIDIA et AMD à nous proposer des architectures un peu plus exotiques, il reste encore tellement à explorer dans le domaine de la 3D temps réel !
Mais pour un joueur ce type de considérations ne doit pas entrer en ligne de compte, tout ce qu’il faut retenir de cette nouvelle puce est qu’elle est armée pour les jeux de demain : que demander de plus ?
Eyefinity
Lorsque l’on jette un œil à la liste des caractéristiques d’une nouvelle carte graphique, la présence des deux traditionnels sorties DVI n’est plus exactement le facteur déclenchant la mise sur le tapis de 300 € ou plus. A fortiori si vous n’utilisez qu’un seul moniteur. En revanche certains d’entre nous ont pendant plusieurs années utilisé 4 moniteurs pour travailler, avec toujours au moins une fenêtre ouverte dans chacun d’eux. Nous nous sommes depuis limités à 3 écrans, mais à l’instant même où nous écrivons ces lignes, nous avons 10 fenêtres Firefox, cet article sous Word, Outlook, deux emails, Excel, Adobe Acrobat, Irfanview et Trillian d’ouverts (et qui ne tiennent pas tous sur ces 3 écrans). Pour ce faire nous disposons d’une configuration assez bâtarde intégrant une Radeon HD 4850 et une X1650 (ayant besoin des autres cartes pour les tests).

 Représentant le premier niveau d’implémentation de l’Eyefinity (déjà dévoilé dans cette actualité sur laquelle nous ne reviendrons pas), la Radeon HD 5870 gère 3 sorties indépendantes réparties via 4 connecteurs : deux DVI dual-link, un HDMI et un Displayport. C’est l’existence de ce dernier qui rend possible Eyefinity. Contrairement au DVI et au HDMI, le DisplayPort ne dispose pas de circuit LVDS (Low Voltage Differential Signaling), requis par les moniteurs non DisplayPort pour interpréter et utiliser correctement le signal de la carte vidéo. En outre le DisplayPort envoie les données sous forme de paquets et peut donc transférer d’autres types de données (comme celles d’un hub USB par exemple). Toutes les cartes tirées du RV870 disposent donc de la gestion des 6 pipelines d’affichage (+2 DAC pour les écrans analogiques), mais seule la Radeon HD 5870 Eyefinity⁶ en tirera pleinement partie.
Représentant le premier niveau d’implémentation de l’Eyefinity (déjà dévoilé dans cette actualité sur laquelle nous ne reviendrons pas), la Radeon HD 5870 gère 3 sorties indépendantes réparties via 4 connecteurs : deux DVI dual-link, un HDMI et un Displayport. C’est l’existence de ce dernier qui rend possible Eyefinity. Contrairement au DVI et au HDMI, le DisplayPort ne dispose pas de circuit LVDS (Low Voltage Differential Signaling), requis par les moniteurs non DisplayPort pour interpréter et utiliser correctement le signal de la carte vidéo. En outre le DisplayPort envoie les données sous forme de paquets et peut donc transférer d’autres types de données (comme celles d’un hub USB par exemple). Toutes les cartes tirées du RV870 disposent donc de la gestion des 6 pipelines d’affichage (+2 DAC pour les écrans analogiques), mais seule la Radeon HD 5870 Eyefinity⁶ en tirera pleinement partie.
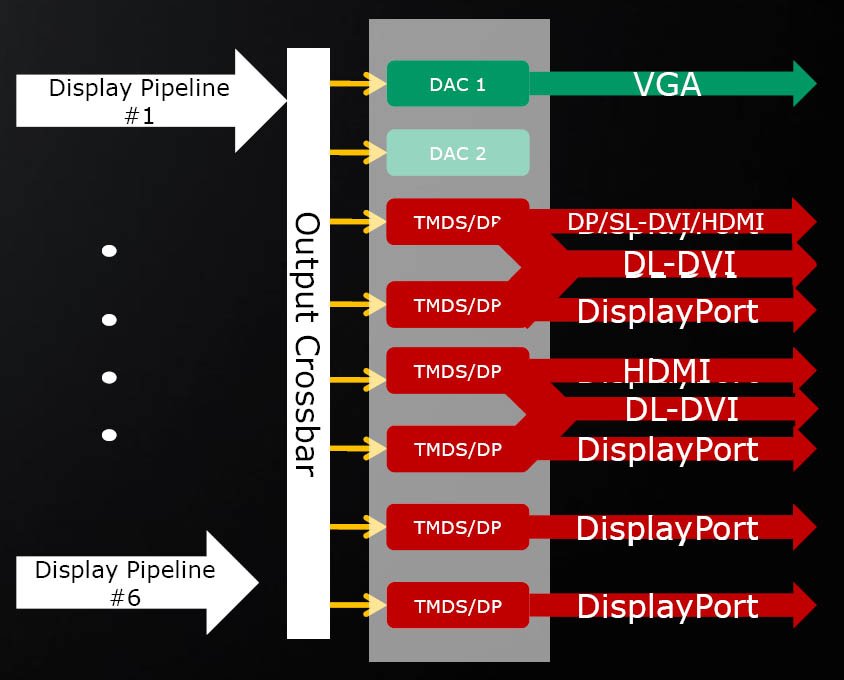
Notez qu’en théorie, cette carte ne se limite d’ailleurs pas au 7680*3200 que l’on peut obtenir avec 6 écrans 30″, mais peut aller jusqu’au 8192*8192 ! Cette carte sera disponible avant la fin de l’année en même temps que le système Samsung proposant 6 écrans 23″ (1920*1200) DisplayPort et doté de bords ultrafins, ainsi que d’autres signés Ergotron.
A l’usage
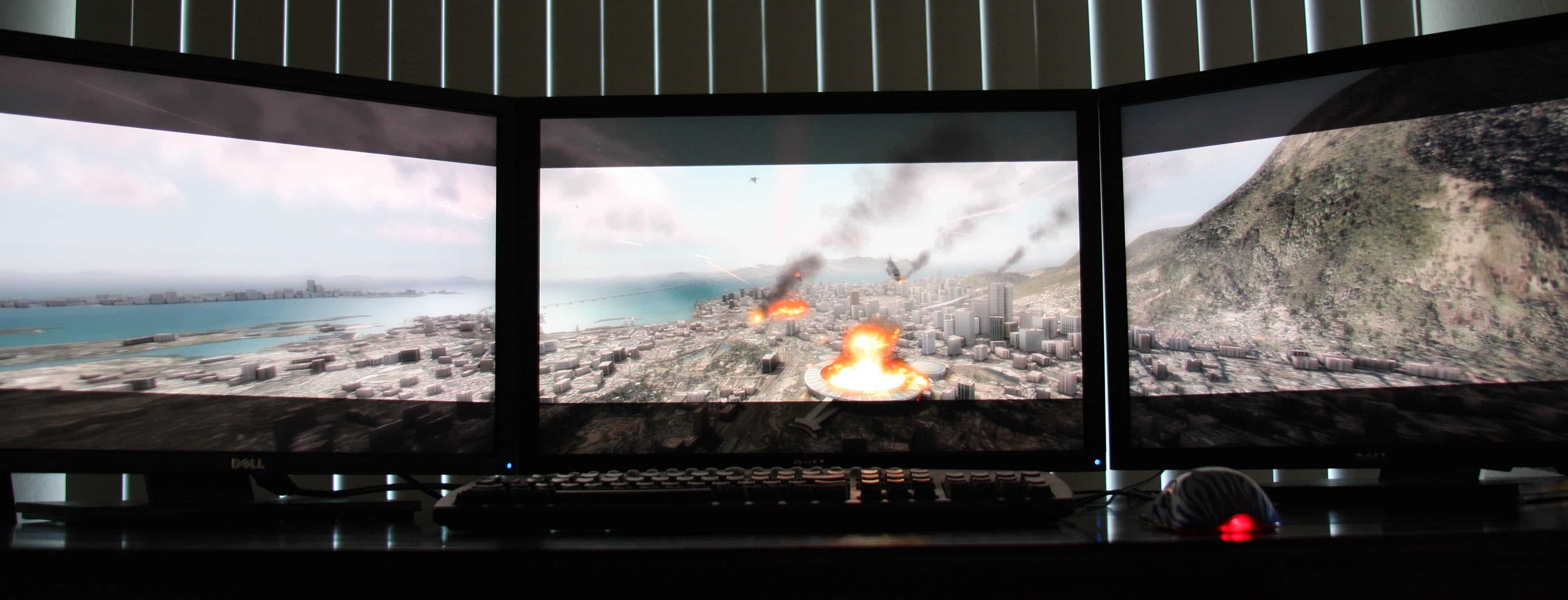
Nous avons utilisé pour cet article un trio de Dell U2410 (24″ en 1920*1200). Voir 3 écrans en démonstration lors d’une conférence de presse est une chose, mais en disposer ensuite pour réellement pouvoir les tester dans les jeux en est une toute autre !
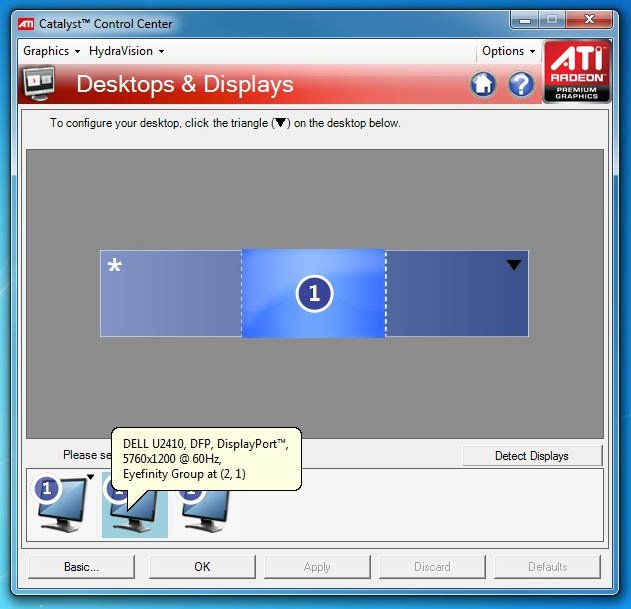
Configurer les trois écrans pour qu’ils soient considérés comme un seul par le système d’exploitation se fait de façon intuitive sous Windows 7 (et cela fonctionne aussi sous Vista et Linux). Nous avons configuré notre bureau en 5760*1200. L’ensemble fonctionne comme si nous ne disposions que d’un seul écran (le passage en plein écran des applications provoque donc un étalement de celles-ci sur l’ensemble des 3 écrans), ce qui ne correspond pas à la façon dont nous souhaitons utiliser 3 écrans pour travailler : ils doivent alors être gérés indépendamment, ce qui est bien sûr possible, mais au prix d’un retour dans les drivers. ATI affirme qu’il existe des raccourcis clavier pour basculer d’un mode vers l’autre (c’est-à-dire du mode « travail » avec 3 écrans indépendants au mode « jeu » avec un seul écran extra-large) mais nous ne les avons pas trouvés. Or cette transition doit pouvoir se faire de façon plus simple.
Conscience professionnelle oblige, notre première priorité après avoir configuré les écrans fut de lancer HAWX.
Malgré la résolution de 5760*1200 et les détails élevé, sans antialiasing nous obtenons 44 images/secondes en moyenne. Voici les scores obtenus avec d’autres jeux :
| Performances avec une seule Radeon HD 5870 @ 5760×1200 (sans filtres), en images/seconde | |
|---|---|
| H.A.W.X. | 44 |
| Far Cry 2 | 54.12 |
| Left 4 Dead | 81.04 |
| S.T.A.L.K.E.R.: Clear Sky | 28.8 |
| World in Conflict | Crash |
| Resident Evil 5 | Non compatible |
| Grand Theft Auto IV | 29.61 |
Bonne surprise, trois jeux restent parfaitement fluides (HAWX, Far Cry 2 et Left 4 Dead) avec une seule 5870. Un résultat plus convaincant que la Parhelia en son temps donc (qui offrait elle aussi pour rappel la possibilité de jouer sur 3 écrans… mais sans la puissance graphique nécessaire). Ce n’est pas le cas de STALKER et de GTA IV. Evidemment, à ce stade nous nous sommes dis que nous venions enfin de trouver une situation où le Crossfire de HD 5870 pourrait avoir une utilité dès aujourd’hui. Malheureusement, les pilotes actuels ne permettent pas d’activer le Crossfire dans ce mode. ATI nous le promet pour bientôt, mais sans annoncer de date malgré notre insistance.
A noter enfin que si les 2,5 cm constituant la bordure de l’écran ne sont pas gênants en 2D, ils le sont plus en 3D. D’où l’intérêt de l’ensemble Samsung composé d’écrans avec un encadrement de moins d’un centimètre.
Spécifications complètes, la carte
| GPU | HD 5870 | HD 4870 | HD 4870 X2 | GTX 280 |
|---|---|---|---|---|
| Fréquence GPU | 850 MHz | 750 MHz | 750 MHz | 602 MHz |
| Fréquence ALU | 850 MHz | 750 MHz | 750 MHz | 1296 MHz |
| Fréquence mémoire | 1200 MHz | 900 MHz | 900 MHz | 1107 MHz |
| Largeur du bus mémoire | 256 bits | 256 bits | 2 x 256 bits | 512 bits |
| Type de mémoire | GDDR5 | GDDR5 | GDDR5 | GDDR3 |
| Quantité de mémoire | 1024 Mo | 512 Mo | 2 x 1024 Mo | 1024 Mo |
| Nombre d’ALU | 1600 | 800 | 1600 | 240 |
| Nombre d’unités de texturing | 80 | 40 | 80 | 80 |
| Nombre de ROP | 32 | 16 | 32 | 32 |
| Puissance shading | 2,72 TFlops | 1,2 TFlops | 2,4 TFlops | 933 GFlops |
| Bande passante mémoire | 153,6 Go/s | 115,2 Go/s | 230,4 Go/s | 141,7 Go/s |
| Nombre de transistors | 2150 millions | 956 millions | 2 x 956 millions | 1400 millions |
| Process | 0.040µ | 0.055µ | 0.055µ | 0.065µ |
| Surface du die | 334 mm² | 260 mm² | 2 x 260 mm² | 576 mm² |
| Génération | 2009 | 2008 | 2008 | 2008 |
| DirectX supporté | 11.0 | 10.1 | 10.1 | 10.0 |
Les spécifications globales sont assez claires quand au doublement de toutes les unités. Hormis l’élévation de la fréquence (+13 %), la grande similitude de la Radeon HD 5870 avec la 4870 X2 apparaît clairement. Notons toutefois que la fréquence des puces mémoires GDDR5 augmente de 33 %, tout comme la bande passante mémoire car, surprise, la largeur du bus reste à seulement 256 bits ! De quoi tout juste obtenir une valeur équivalente à celle de la GTX 280, mais pas vraiment plus. Officiellement, AMD nous a affirmé s’être rendu compte que la Radeon HD 4870 disposait de trop de bande passante et qu’il suffisait donc de l’augmenter de 33 %. Pourtant, l’augmentation de la puissance est de calcul est de 126 % ! En pratique le constructeur devait sans doute voir d’un mauvais œil le doublement de la largeur du bus et la complexité supplémentaire du GPU et du PCB qui s’en serait suivi. Un choix découlant directement de l’état d’esprit introduit par AMD avec le RV770, et qui s’oppose frontalement à celui de NVIDIA. Reste à voir s’il ne sera pas pénalisant.
La carte


Esthétiquement parlant, la Radeon HD 5870 adopte le design des GeForce GTX 200, avec l’enfermement complet de la carte dans un boîtier qui va jusqu’à recouvrir toutes ses faces, laissant seulement place à la plaque de fixation située à l’arrière du GPU (en soutien au radiateur). Seuls dépassent le connecteur PCI Express et les connecteurs Crossfire. Bien que cela protège mieux les composants et améliore leur refroidissement ainsi que la canalisation du flux d’air sur toute la carte, la disparition du PCB (noir par ailleurs) a tendance à rendre ces cartes assez uniformes et sombres, seules quelques tâches rouges ici et là et l’autocollant du ventilateur permettant de deviner que nous ne sommes pas en présence d’une GeForce…


Un autre facteur de différenciation réside toutefois dans la longueur de la carte, avec un nouveau record. Si elle partage bien le PCB de 26,7 cm (10,5″) commun aux cartes très haut de gamme (mais dont ne disposait habilement pas la Radeon HD 4870), son châssis dessine deux arrivées d’air à l’arrière qui rajoute encore 1,27 cm. Bien que les connecteurs d’alimentation supplémentaires (limités à 6 broches mais présents en double) soient placés sur le dessus de façon à ne pas rajouter encore à la longueur, cette carte ne rentrera pas dans tous les boîtiers et gênera en tout cas l’installation des disques durs dans la plupart des modèles classiques.

La bonne nouvelle reste que comme avec la Radeon HD 4870 et les GeForce GTX (mais contrairement à la 4850), l’air chaud est expulsé à l’extérieur du boîtier et la carte fait donc office de ventilateur de boîtier supplémentaire. En revanche, présence de 4 connecteurs vidéo oblige, la surface de cette grille est réduite de plus de la moitié, augmentant donc les pertes de charge et laissant craindre pour les nuisances sonores. Le ventilateur reste pour sa part entièrement similaire à celui des 4870/4890.
Le test

Pour ce lancement, nous avons tenu à vous proposer nos tests traditionnels, basés exclusivement sur des scènes de gameplay au cours desquelles le nombre d’images par seconde est enregistré via FRAPS. Ceci afin de relever les vrais gains ainsi que les vraies valeurs d’images par seconde que vous obtiendrez en branchant cette carte dans une configuration similaire à la notre. Vous le constaterez, quelques jeux sont ainsi limités par la performance des processeurs actuels, et d’autres sont très largement moins fluide en pratique que ce que les sempiternels modes Timedemo majoritairement utilisés d’habitude laissent penser. Par comparaison et pour augmenter le nombre d’avis à votre disposition, nous publierons cependant dans les prochains jours un second comparatif de cette carte via les modes benchmarks/timedemos des jeux qui intègrera notamment ses performances en SLI/Crossfire et avec les GeForce GTX 285/285 SLI/295 (le tout sur Core i7 975 overclocké), que nous n’avons pas pu nous procurer pour ce test.
Configuration de test
- AMD Phenom II X4 965 BE (overclocké @ 3.8 GHz) / Zalman CNPS 9500
- Gigabyte MA790FXT-UD5P
- 2 x 2 Go DDR3 1333 9-9-9 Crucial
- Western Digital Velociraptor
- Graveur DVD Samsung SH-S202
- Coolermaster RealPower 850 W
- Windows 7 Professional 32 bits (RTM)
- Catalyst 9.10 beta (2ème generation DX11)
- ForceWare 191.00
Faute de processeur Intel Core i5/i7 à notre disposition nous avons donc eut recours au Phenom II X4 965 BE, que nous avons toutefois overclocké à 3.8 GHz pour ce test (soit l’équivalent d’un improbable Phenom II X4 985…). Cela nous permettra par ailleurs de vérifier si l’association plateforme AMD + GPU AMD apporte bien un avantage ou non.
Tom Clancy’s H.A.W.X.
Bien qu’assez peu gourmand en mode DirectX 9, HAWX l’est nettement plus lorsqu’il utilise DirectX 10. Dans ces conditions, la Radeon HD 5870 ne peut luter face à la Radeon HD 4870 X2 en 1920*1200, probablement grâce à sa bande passante mémoire bien supérieure (elle double sur la 4870 X2 par rapport à la 4870, alors que la Radeon HD 5870 ne représente qu’un gain de 33 % pour rappel). En revanche, plus la charge augmente et plus la 5870 revient à sa hauteur, jusqu’à l’égaler en 2560*1600 + antialiasing 4X. L’avance de la 5870 sur la GTX 280 varie entre 12 % et 51 % suivant les réglages, alors qu’elle atteint 66 % à 82 % par rapport à la 4870 512 Mo (et même 237 % en 2560*1600 + filtres).
GearGrinder

Course de camions sympathique et visuellement réussie, le tout juste disponible GearGrinder ne modifie pas la hiérarchie établie sous HAWX, mais permet de constater l’écroulement de la Radeon HD 4870 X2 consécutif à l’activation de l’antialiasing d’une part, et de nouveaux écarts d’autre part : la Radeon HD 5870 s’avère ici en moyenne 63 % plus rapide que la Radeon HD 4870 (ce jeu ne faisant pas s’écrouler cette dernière en 2560*1600).
Arma 2

Le toujours bugé mais néanmoins très bon Arma 2 change quand à lui significativement la donne. Bien que nous ayons utilisé les derniers ForceWare 191.00 optimisés pour Arma 2, les GeForce GTX sont en retraits et battus par une simple Radeon HD 4890. La Radeon HD 4870 X2 n’est elle non plus pas à la fête. En revanche la Radeon HD 5870 s’envole en 2560*1600 et s’avère 75 % plus rapide que la Radeon HD 4870, 44 % par rapport à la 4890.
Order of War
Lui aussi sorti cette semaine, ce jeu de stratégie temps réel se déroulant lors de la seconde guerre mondiale est prometteur. Il s’avère malheureusement fortement limité par le processeur dans la plupart des situations de jeu, ce qui signifie qu’il est inutile d’investir dans une carte graphique onéreuse pour en profiter. Surtout au vu du résultat de la Radeon HD 4870 X2 qui a tout simplement refusé de lancer le jeu quelque soit les conditions (c’est aussi ça les joies des cartes graphique bi-GPU, qui a par ailleurs occasionnée la mise en sécurité de notre alimentation FSP 1200 W au cours des tests et donc nécessité son remplacement).
STALKER : Clear Sky

Toujours aussi beau et impressionnant techniquement, Clear Sky reste un incontournable et le jeu qui s’est avéré le plus gourmand de cet article. Il faut dire qu’une fois toutes les options activées, certains passages en extérieurs mettent réellement les cartes à genoux, et nous les avons donc retenus pour établir notre test.
Le résultat est sans appel : seules deux cartes parviennent à tirer leur épingle du jeu et à soutenir ces réglages : la Radeon HD 4870 X2 et la Radeon HD 5870. Cette dernier parvient d’ailleurs à reprendre l’avantage en 2560*1600. En revanche les GeForce GTX sont loin derrière. Et même si nous excluons la 4870 du fait de sa quantité de mémoire trop faible pour ce jeu dans ces résolutions, la 5870 s’avère en moyenne 65 % plus rapide que la 4890 (l’écart restant régulier indépendamment des résolutions) !
Flight Simulator X

Flight Simulator X reste extrêmement limité par le processeur, ce qui est finalement une aubaine pour le multi-écran permis par les Radeon HD 5800. Mais ce n’est pas de puissance GPU dont vous aurez besoin si vous affectionnez tout particulièrement cette simulation : investissez plutôt dans un gros processeur…
Anno 1404

Pas seulement superbe, Anno 1404 est également le plus aboutit de la fameuse série de jeux de gestion. Assez gourmand (une 4870 reste limite pour un écran 24-26″ suivant les scènes), il affiche surtout une performance surprenante de la 4870 X2 qui s’avère plus de 2 fois plus rapide que la 4870 dans toutes les situations, phénomène possible du fait du doublement de la quantité de mémoire réellement exploitée. En revanche la Radeon HD 5870 affiche pour une fois un niveau de performances un peu décevant, ne s’avérant que 5 % plus rapide en moyenne que la 4890. Elle partage pourtant le même driver que toutes les autres Radeon testées.
Crysis

Malgré ses 2 ans d’existence désormais, Crysis reste sans aucun soucis l’un des jeux les plus gourmands actuellement disponible. Et reste toujours injouable avec la Radeon HD 5870 en 2560*1600 ! Les choses progressent tout de même et l’on retrouve notre duo de tête composé de celle-ci et de la Radeon HD 4870 X2, qui parvient cette fois-ci à rester intouchable. On note tout de même un gain moyen de 54 % par rapport à la Radeon HD 4890.
Consommation
Voici les niveaux de consommation obtenus au niveau de l’alimentation (retirer environ 20 % pour obtenir les valeurs de consommation de la configuration complète) :
Surprise ! A elle seule, la Radeon HD 5870 parvient à abaisser le niveau de consommation de 26 % au repos par rapport à la même configuration mais accompagnée par la Radeon HD 4870 ! Très impressionnant. Même la GTX 280, pourtant une référence en la matière, est battue à plate couture (et les GTX 285/275/260+ le seraient également sans l’ombre d’un doute). Du coup la valeur annoncée par AMD (27 W pour la carte seule, contre 90 W pour la 4870) nous paraît crédible, le constructeur désactivant tout ce qui peut l’être en 2D et les fréquences étant abaissées à seulement 157 MHz pour le GPU (au lieu de 850 MHz en charge) et 300 MHz pour la mémoire (au lieu de 1200 MHz). Enfin !
En charge (sous Fillrate Tester et sans CPU burner), le choc est moins grand mais on note un très bon résultat malgré tout puisque la Radeon HD 5870 parvient à monter à 10 W de moins que la 4870 et 55 W en dessous de la GTX 280. A noter toutefois que les valeurs officielles contredisent en partie ce constat, puisque la consommation maximale de la 5870 est annoncée par AMD à 188 W contre 170 W pour la 4870. C’est également cette hiérarchie que nous avons constaté le plus souvent en pratique dans les jeux.
Température, bruit
Température
Si la consommation de la carte est en baisse, la température l’est également ! Toujours au niveau des pics supérieurs et inférieurs enregistrés pendant l’exécution 3 fois de suite de Fillrate Tester, on note 10°C de moins que la 4870 en charge et pas moins de 21°C gagnés au repos par rapport à la Radeon HD 4870 (qui contrairement à la Radeon HD 4850 dispose d’un ventirad double slot et ne chauffe pas excessivement). Le niveau atteint redevient similaire à celui des GeForce GTX 280. A noter que la température de l’étage d’alimentation de la carte (VRM) est désormais analysée par la carte pour éviter les surchauffes, un détail qui fait clin d’œil à l’épisode récent des Radeon 4890 sous OCCT.
Bruit
Malheureusement, AMD ne profite pas de sa faible consommation pour couper le ventilateur en 2D ou réduire le niveau de bruit en 3D. Il faut dire que la finesse de gravure étant plus fine, la densité de transistors est plus importante ce qui oblige à améliorer la qualité du refroidissement pour conserver des températures similaires (or celles-ci sont même en baisse comme nous venons de le voir). Sans parler de la toute petite grille de sortie dans laquelle l’air doit se faufiler. Bien que les ventilateurs restent tous les trois de type et taille identiques et à des valeurs proches en charge (2460 rpm pour la GTX 280, 2112 rpm pour la 5870 et 2053 rpm pour la 4870), la Radeon HD 5870 est la carte qui s’avère la plus audible si l’on en croit le sonomètre. A l’oreille, nous la qualifierons alors d’assez bruyante, bien qu’on ait connu pire. Elle s’avère en revanche très discrète au repos, mais comme la plupart des cartes haut de gamme désormais.
Conclusion
Au final, la Radeon HD 5870 ne déçoit pas et représente ce que l’on espérait le plus du point de vue joueur/utilisateur, à savoir l’évolution logique de la Radeon HD 4870. 2,26 fois plus puissante en théorie et sur les tests synthétiques, elle ne bénéficie toutefois que d’une bande passante 33 % supérieure, le bus mémoire restant à 256 bits. Elle s’avère du coup dans les jeux 1,5 à 2 fois plus rapide que la Radeon HD 4870 512 Mo, dans les situations où la quantité de mémoire de cette dernière ne constitue pas un facteur limitant.
Un gain intéressant donc, d’autant qu’il s’accompagne d’une architecture légèrement améliorée pour supporter DirectX 11 et Windows 7 (les drivers étant déjà très convaincants), avec l’arrivée prochaine de Battleforge, Colin MacRae Dirt 2 ou encore STALKER : Call of Pripyat (bien que repoussé à 2010). Bien sûr, comme avec DirectX 10 il est probable que ces jeux n’intègreront qu’une implémentation peu efficace de la nouvelle API (et ce aussi bien en terme de rendu visuel que de coût en performances). Mais leur proximité incite tout de même à l’optimisme.
Par ailleurs, AMD a conservé sa philosophie du minimalisme, du meilleur rapport performances/taille du die et donc du rapport performances/prix. Grâce au recyclage de l’architecture des Radeon HD 4800 et au recours au 40 nm, la Radeon HD 5870 (et très probablement la 5850) atteint un nouveau record en termes de consommation au repos (27 W annoncés et crédibles d’après nos résultats). Elle augmente un peu en charge comparativement à une 4870 mais reste à un niveau raisonnable, en dessous d’une GTX 285 par exemple, et à des années lumières de la 4870 X2 avec laquelle elle se bat pourtant côté performances.
Nous n’oublierons pas non plus la possibilité, certes réservé à une élite, mais qui n’en offre pas moins de nouvelles perspectives, de jouer sur 3 à 6 écrans avec ces nouvelles cartes, ainsi qu’un nouvel algorithme de filtrage anisotropique qui ne dégrade plus la qualité du filtrage réellement appliquée suivant l’angle. Quand au prix, il est de 350 €. C’est certes plus élevé que celui de deux Radeon HD 4870 1 Go (environ 260 €), mais les avantages en termes de bruit, consommation, support de DirectX 11 et stabilité des performances sont si importants qu’ils ne modifient pas notre avis, et ce sans même considérer le fait qu’il s’agisse d’une solution haut de gamme inégalée en matière de carte single-GPU.
Bref, à l’heure où la prochaine génération de GeForce pourrait ne pas être disponible en masse avant 2010 et en attendant de voir si la Radeon HD 5850 parvient à être encore plus intéressante (sa puissance brute baisse de 23 % pour un prix 31 % plus bas : 240 €), force est de constater qu’AMD fait tout pour faciliter le parallèle avec une certaine Radeon 9700 Pro. Si la disponibilité suit, ce qui ne semble pas très bien parti.
- Les plus
- Les moins
- Performances 1,5 à 2 fois supérieures à celles d’une Radeon HD 4870
- Consommation record au repos
- Architecture DirectX 11
- Eyefinity : de 3 à 6 écrans
- Nouvel algorithme de filtrage anisotropique
- Carte extrêmement longue
- Prix supérieur à 2 Radeon HD 4870 1 Go