L’une des raisons du rachat de Xilinx ?
Après l’abandon d’une architecture monolithique au profit d’une conception à base chiplets dans ses processeurs depuis l’architecture Zen 2, AMD pourrait apporter une nouvelle évolution avec l’intégration de FPGA (Field Programmable Gate Arrays) dans ses CPU ; un autre moyen d’augmenter les performances de ses puces.

La société a déposé un brevet intitulé “METHOD AND APPARATUS FOR EFFICIENT PROGRAMMABLE INSTRUCTIONS IN COMPUTER SYSTEMS”. Si beaucoup de brevets ne trouvent jamais d’applications concrètes, celui-ci est quand même soutenu par le rachat de Xilinx, à l’origine du FPGA, par AMD en octobre dernier. On suppose que la société dirigée par Lisa Su n’a pas déboursé 35 milliards de dollars sans avoir quelques projets…
AMD planche sur des GPU à base de chiplets
Un moyen d’augmenter les performances
L’intégration de FPGA au sein de CPU pourraient se traduire par une hausse des performances non négligeable. Un processeur x86 classique est conçu pour exécuter un large panel d’instructions, avec plus ou moins d’habilité ; tout le contraire d’un FPGA, très spécialisé, capable d’exécuter rapidement des jeux d’instructions spécifiques. En outre, comme leur nom l’indique, ils ont l’avantage d’être reprogrammables facilement, autrement dit de s’adapter à d’autres tâches au besoin. Schématiquement, l’idée derrière ce brevet consisterait à confier certains calculs spécifiques au module FPGA afin qu’il les traite plus rapidement que ne le feraient les cœurs CPU.
Comme le rapporte TechPowerUp, une telle association existe déjà chez Intel, avec le Xeon 6138P. Ce processeur associe CPU et FPGA Arria 10 GX 1150. Néanmoins, les deux éléments prennent place sur le même die, mais ne sont pas vraiment intégrés nativement ; le Xeon 6138P est “simplement” une puce 2-en-1 en quelque sorte.

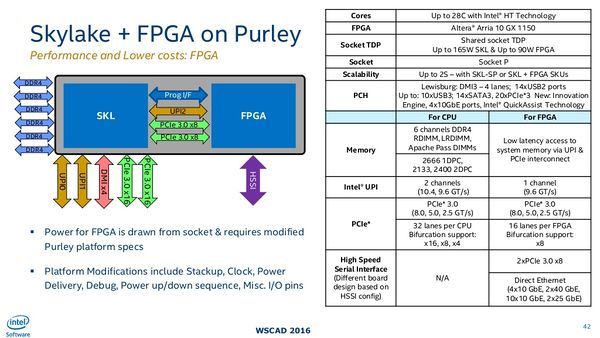
AMD pourrait pousser le concept à stade plus avancé, avec une intégration complète CPU / FPGA. Pour cela, la firme a deux options. Pour rester dans la philosophie des chiplets, le FPGA pourrait résider dans son propre chiplet, à l’écart. Dans ce cas, il serait interconnecté avec le CPU par l’Infinity Fabric. Cette méthode présente l’avantage de ne pas trop chambouler l’architecture des processeurs, mais peut induire de la latence. L’autre solution, plus radicale, consisterait à intégrer le FPGA directement au sein des chiplets contenant les cœurs CPU. Cette stratégie minimiserait la latence, mais impliquerait de réorganiser en profondeur les CCD (Core Complex Die).
Sources : Tom’s Hardware US, WikiChip











Intel a déjà un brevet de ce genre en poche depuis le rachat de la division CPU de Digital. L’Alpha utilisait déjà cette technique même si l’optique était différente. Il s’agissait d’adapter le CPU à différents OS comme VMS, UNIX et NT.
Étant moi même specialiste FPGA, l’inverse s’opère déjà avec des FPGAs qui comprennent de plus en plus des blocs non reprogrammables de plus en plus grands, comme des cores ARM notamment. Le fait de devoir reprogrammer la partie FPGA me fait dire que cette techno sera d’abord réservée au HPC, car le processus pourrait être un peu complexe a apprendre pour les fabricants de logiciels grand public.
Merci pour ces précisions !