Un moteur de rendu logiciel
Comme nous l’avons vu dans la première partie de notre dossier, Larrabee n’est pas vraiment un GPU. Par conséquent son mode de fonctionnement est assez particulier notamment au niveau de son driver. Le driver d’un GPU traditionnel est en général séparé en deux modules, un module de haut niveau qui communique avec l’API 3D (Direct3D ou OpenGL) et un module de bas niveau commun aux diverses API qui se charge de réaliser la programmation de la puce à proprement parler. En général on retrouve un mapping quasiment 1:1 entre les fonctions de l’API et les fonctions offertes par la puce, la programmation de cette dernière consiste donc à positionner les registres correspondants aux appels d’API aux bonnes valeurs. En soit ça n’est pas très compliqué mais toute la difficulté de faire un bon driver réside dans le fait d’optimiser au mieux le code pour éviter les changements redondants des valeurs de ces registres car cela reste une opération coûteuse, le tout bien sûr sans introduire de bugs ce qui n’est pas une mince affaire quand on voit la tonne d’états différents qui contrôlent le rendu. L’introduction des shaders a également compliqué la donne puisque désormais les drivers doivent contenir de véritables compilateurs pour transformer le code générique en code spécifique à la puce.
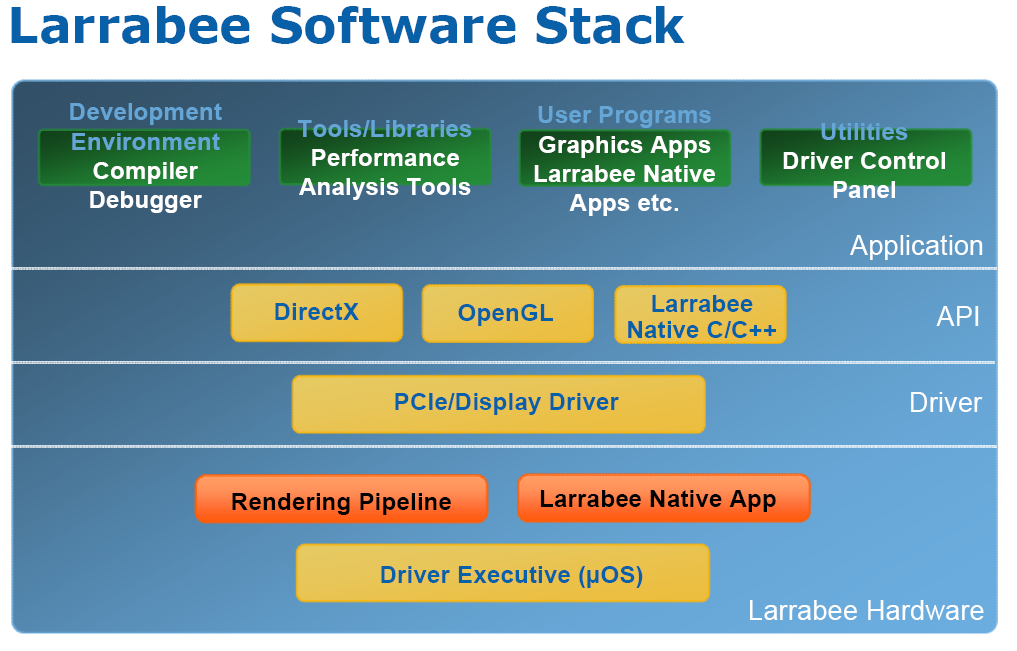
Comme nous l’avons vu Larrabee ne comporte que très peu d’unités fixes par conséquent on ne retrouve pas ce mapping 1:1 entre les appels d’API et des registres sur la puce contrôlant l’état du rendu. Le driver de Larrabee n’en est donc pas vraiment un à proprement parler : on retrouve la couche qui fait l’interface avec les API de haut niveau, et qui se charge de la communication CPU-Larrabee via l’interface PCI Express mais c’est ensuite que les choses divergent par rapport à un GPU classique. Au sein du driver on trouve en effet un moteur de rendu purement logiciel qui tourne sur les cœurs de Larrabee.
En d’autres termes le driver de Larrabee est plus proche des moteurs 3D d’il y a une dizaine d’années comme ceux de Quake ou Unreal : on ne trouve pas sur Larrabee de fonction câblée pour rastériser un triangle comme sur les GPU, c’est donc un bout de code extrêmement optimisé et tournant sur les cœurs de Larrabee qui s’en charge. Mais évidemment depuis l’époque de Quake qui était prévu pour tourner au mieux sur un simple Pentium à une centaine de MHz et les capacités de Larrabee, il y a un monde, aussi ce moteur 3D qui a été spécialement conçu pour exploiter les forces de Larrabee mérite qu’on s’y intéresse de plus près.
Architecture Sort-Last
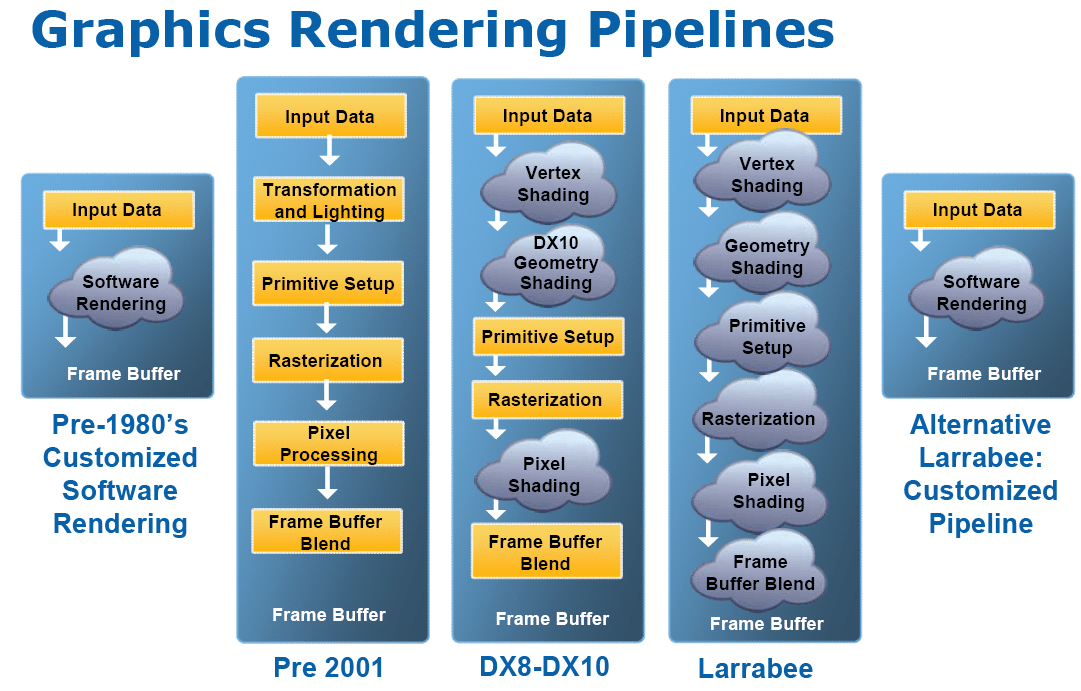
Les architectures des GPU modernes entrent dans la catégorie des Sort-Last Fragment (Tri en dernier du fragment). En d’autres termes le pipeline basique fonctionne de cette façon : à chaque cycle, plusieurs sommets sont transformés en parallèle par les unités de vertex shading. UN triangle est assemblé par l’unité d’assemblage de primitive. Il est ensuite rastérisé c’est-à-dire transformé en fragments. Les fragments générés sont assignés aux unités de fragment shading en fonction de leur position sur l’écran. Ils sont ensuite traités en parallèle par les unités de fragment shading, avant d’être écrits dans le frame buffer par les ROP (là encore plusieurs fragments sont traités simultanément). Comme on le voit, dans ce type d’architecture le tri et l’assignement aux différents tiles se fait après la rastérisation, juste avant le shading.
Cette technique permet donc de paralléliser plusieurs étapes du pipeline sur de multiples unités mais il reste encore malgré tout un point purement séquentiel : le setup du triangle.
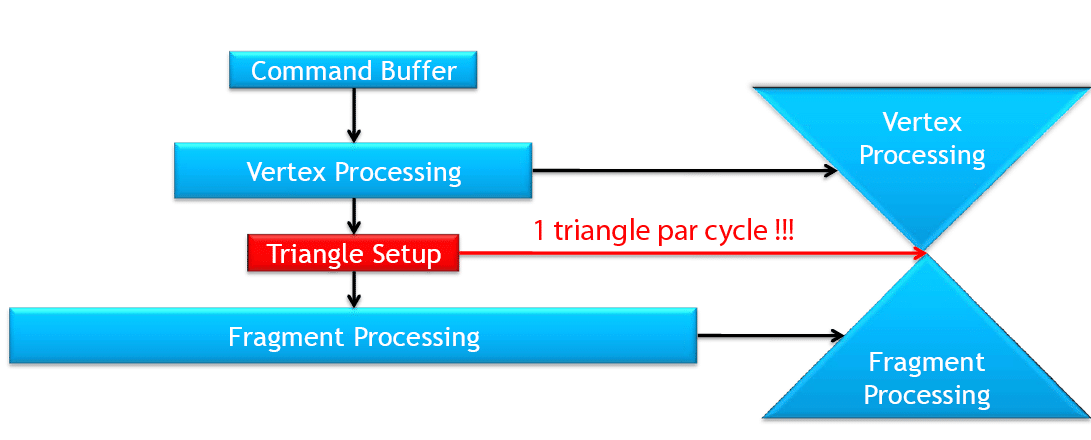
A ce niveau les primitives sont remises dans l’ordre dans lequel elles ont été soumises, et elles sont traitées une seule à la fois. Pendant longtemps ça ne posait aucun problème : les unités de vertex shading n’étaient de toute façon pas suffisamment nombreuses pour saturer le setup. Mais aujourd’hui avec les architectures unifiées on constate dans des benchs théoriques que la limitation n’est plus due à la puissance de calcul mais à la vitesse du setup. Augmenter le setup pour traiter plusieurs triangles en parallèle poserait de multiples problèmes : toute l’efficacité du GPU vient du fait que le traitement des sommets et des pixels peut être parallélisé sans synchronisation, augmenter la vitesse de setup casserait donc ce paradigme. En effet supposons que le setup génère deux triangles par cycle et que ceux-ci soient destinés à la même zone d’écran (le même tile), les fragments générés pour chacun d’eux seront donc assignés aux mêmes unités de shading. Celles-ci ne pourront pas les traiter simultanément, il faudra donc gérer le partage de cette ressource. On entre donc en plein dans les problèmes de synchronisation qui détruisent l’efficacité du traitement parallèle.
Architecture Sort-Middle
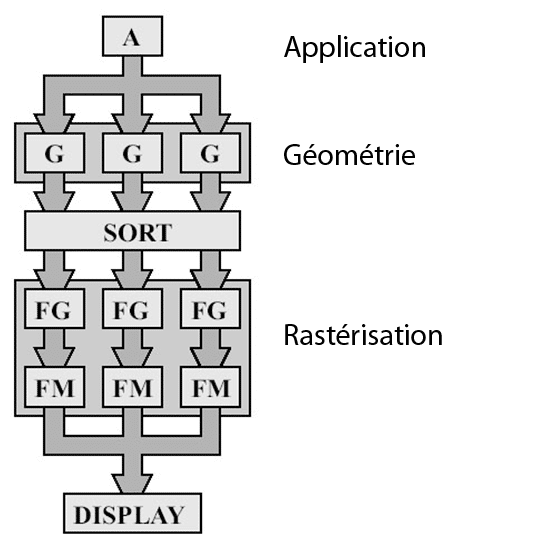
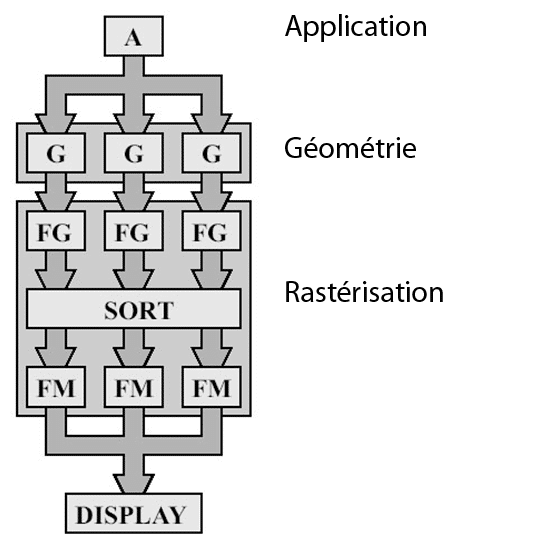
Une autre architecture appelée Sort-Middle (tri au milieu) permet de résoudre ce problème. Cette approche n’est pas nouvelle, elle a pendant longtemps été employée par SGI dans ses InfiniteReality et par Videologic avec ses PowerVR. Plutôt que de trier après le rasterizer les fragments générés, ce type d’architectures tri avant le rasterizer et opère donc directement sur les primitives. Comme dans l’architecture précédente l’écran est divisée en région appelées Tiles. Le pipeline est donc implémenté en deux étapes. Dans un premier temps tous les triangles sont transformés (ils sont ensuite stockés en mémoire), dans un deuxième temps ces triangles sont triés pour être assignés aux différents Tiles en fonction de leur position sur l’écran, et enfin ils sont rastérisés.
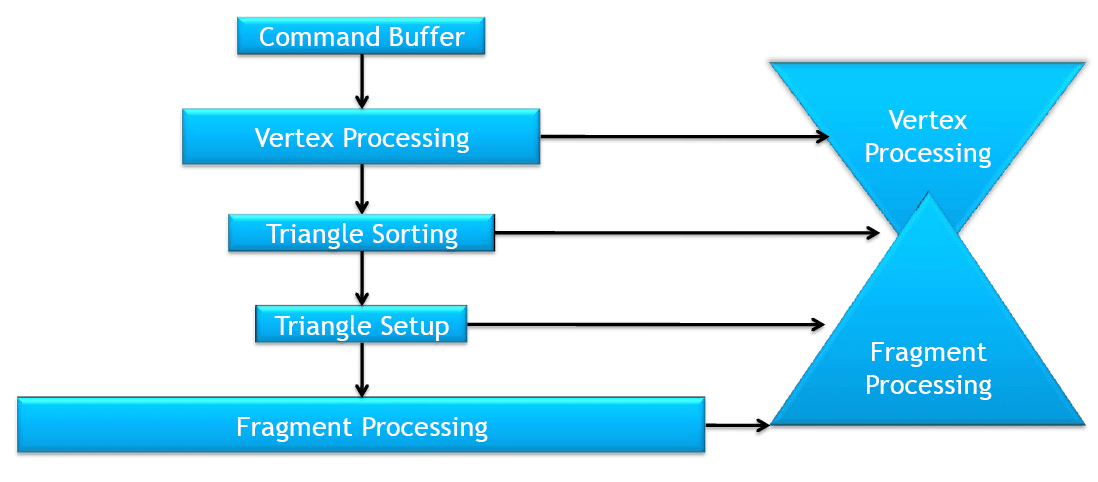
L’atout de cette technique est donc de permettre de paralléliser le setup des triangles, mais évidemment si elle ne s’est pas totalement démocratisée c’est qu’elle ne présente pas que des avantages. Tout d’abord elle est plus gourmande en espace mémoire vu qu’il faut stocker l’ensemble des triangles transformés en mémoire vidéo alors que ce n’est pas le cas des GPU « traditionnels ». Ensuite les triangles qui chevauchent les frontières des Tiles sont assignés à tous les Tiles qu’ils intersectent et devront donc être traités plusieurs fois (une fois pour chaque Tile dans lequel ils se trouvent).
Vous l’aurez compris suite à cette longue introduction, c’est cette approche qui a été choisie pour le moteur de rendu de Larrabee. Il y a plusieurs avantages à ce choix dans le cas de l’architecture d’Intel : tout d’abord comme nous l’avons vu, cela permet de paralléliser le setup sur les différents cœurs, ce qui est un pré requis pour bien utiliser les ressources de Larrabee. Un autre avantage que nous détaillerons plus loin est que cette approche permet de stocker les données du Tile directement dans la mémoire cache de chaque cœur.
Un renderer différé
Le fonctionnement des API 3D peut être schématisé de la sorte :
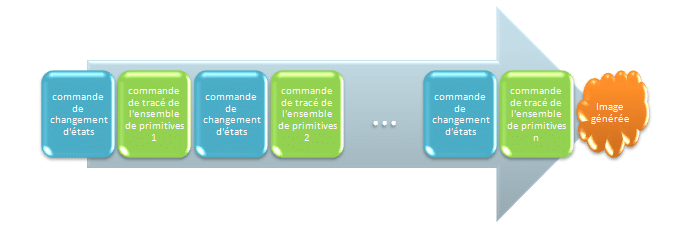
En d’autres termes l’API 3D est un calculateur d’états : le programmeur positionne certains états (activation/désactivation du ZBuffer, chargement d’un shader particulier, changement de Render Target…) et ensuite effectue le rendu d’un ensemble de primitives utilisant cet état. On réitère ensuite ce processus jusqu’à obtenir le rendu final de l’image. Les GPU traditionnels sont des renderers en mode immédiat, c’est-à-dire que chaque changement d’état est effectué dès que la commande est rencontrée dans le tampon de commandes, puis les primitives sont dessinées avec ce mode de rendu jusqu’au prochain changement d’état.
A l’inverse des architectures comme PowerVR ou comme le moteur de rendu de Larrabee sont des renderers différés. Ainsi ils ne disposent pas d’un ensemble d’états actifs à un moment donné : ils capturent l’intégralité de ces variables d’états à chaque changement, ils les sauvegardent dans des structures de données, puis regroupent tous les triangles et leur assignent un tag indiquant quel ensemble d’états ils utilisent pour leur rendu. L’ensemble de triangles et de leurs états associés forment un Primitive Set ou PrimSet dans la nomenclature Intel.
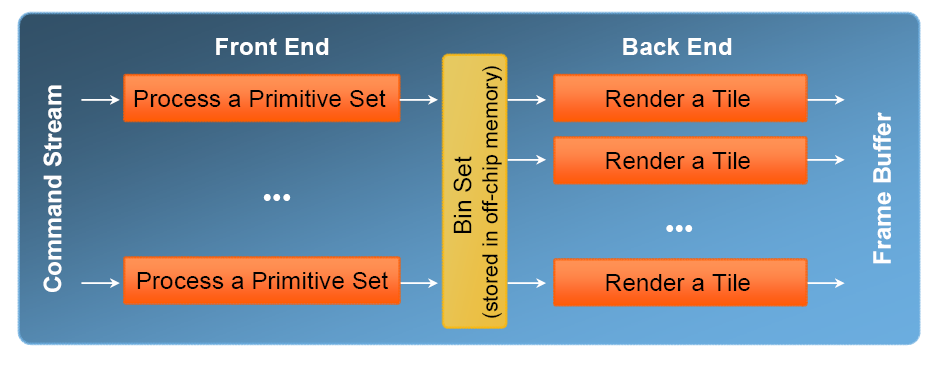
Une fois ces PrimSets assemblés, le rendu à proprement parler peut commencer. Il est effectué en deux phases, en premier lieu on trouve le front-end. Durant cette phase chaque PrimSet est assigné à un cœur de Larrabee. Celui-ci effectue toute la partie géométrique du pipeline 3D c’est-à-dire le vertex shading, le geometry shading, le culling et le clipping. Les triangles ainsi générés sont ensuite rastérisés, à partir de ce moment on dispose de l’ensemble de coordonnées 2D que couvre le triangle. On sait donc à quel Tile ils vont appartenir.
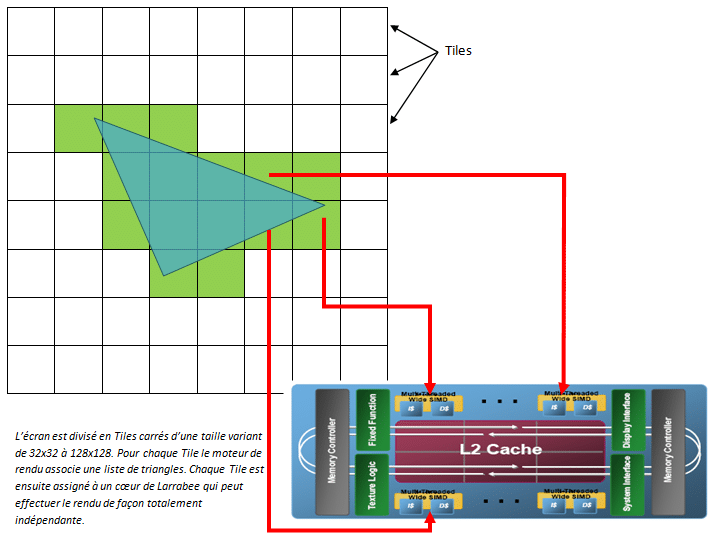
Pour chaque Tile du frameBuffer le front-end génère une liste de triangles qui sont partiellement ou totalement inclus dans cette région (un Bin dans la nomenclature Intel). Comme nous l’avons vu, un même triangle peut appartenir à plusieurs Tiles ce qui génèrera du travail redondant dans le back-end. Il faut aussi souligner que plus les Tiles sont petits, plus il est possible de paralléliser le setup sur un grand nombre de cœurs mais en contrepartie plus le nombre de triangles qui sera inclus dans plusieurs Tiles va augmenter. Tout est une question de compromis donc, et d’après les estimations d’Intel ce n’est pas vraiment un problème vu que ça ne suscite une augmentation du nombre de triangles traités que de moins de 5% seulement. La taille des Tiles dans le moteur de rendu de Larrabee est variable en fonction de la profondeur de couleur et du nombre de Render Targets utilisées, puisqu’ils doivent toujours être en mesure de tenir dans le cache de niveau 2 des coeurs. Ils peuvent ainsi varier de 32×32 à 128×128 pixels dans le cas le plus favorable (ZBuffer 32 bit et BackBuffer 32 bit).
Le back-end
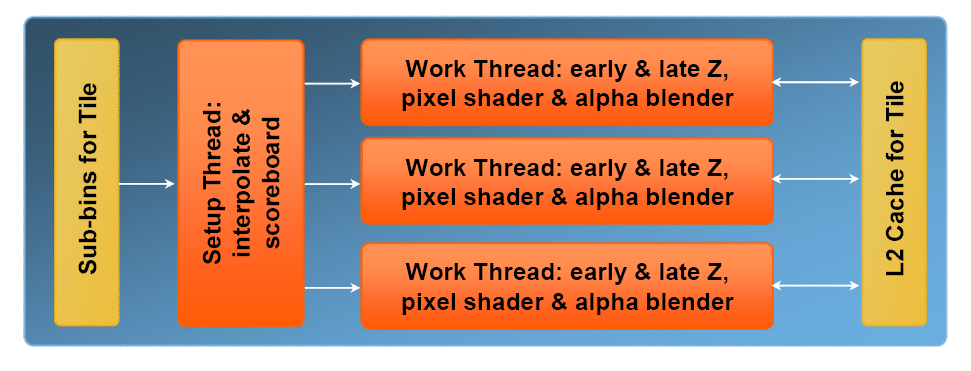
Une fois que le front-end a terminé de traiter l’ensemble des triangles, le back-end se met en route. La première phase consiste à récupérer l’ensemble des valeurs des pixels du Tile traité dans le cache de niveau 2. A partir de ce moment tout le rendu sera effectué dans le cache de niveau 2 et ne touchera plus à la mémoire principale jusqu’à l’écriture du résultat final. Cette technique offre plusieurs avantages en termes de bande passante : quel que soit le nombre de triangles qui intersectent ce Tile, il n’y aura au maximum qu’une seule lecture et une seule écriture en mémoire principale. De plus les opérations coûteuses en bande passante comme le blending ou l’antialiasing sont aussi effectuées directement sur la puce.
 Ainsi l’antialiasing peut être résolu (le mélange des samples effectués) avant de copier la valeur du pixel en mémoire : au lieu d’écrire 4 valeurs de couleurs et 4 de profondeurs, il suffit donc de n’en écrire qu’une. En pratique le gain est plus limité puisque les GPU modernes utilisent des techniques de compression de couleurs et du ZBuffer particulièrement efficaces lorsque l’antialiasing est activé. Cette technique, qui peut également être utilisée sur des renderer en mode immédiat embarquant de l’EDRAM (comme le Xenos de la Xbox 360 ou le Flipper de la GC) permet d’économiser de la bande passante, mais aussi de l’espace mémoire. En effet il n’est ainsi plus nécessaire de stocker un back buffer et un ZBuffer 4 fois plus grands en mémoire lors de l’utilisation de l’antialiasing 4X. La couleur finale du pixel est déterminée lors de la copie du Tile du cache L2 vers la mémoire centrale et non plus lors de l’échange du front et du back buffer.
Ainsi l’antialiasing peut être résolu (le mélange des samples effectués) avant de copier la valeur du pixel en mémoire : au lieu d’écrire 4 valeurs de couleurs et 4 de profondeurs, il suffit donc de n’en écrire qu’une. En pratique le gain est plus limité puisque les GPU modernes utilisent des techniques de compression de couleurs et du ZBuffer particulièrement efficaces lorsque l’antialiasing est activé. Cette technique, qui peut également être utilisée sur des renderer en mode immédiat embarquant de l’EDRAM (comme le Xenos de la Xbox 360 ou le Flipper de la GC) permet d’économiser de la bande passante, mais aussi de l’espace mémoire. En effet il n’est ainsi plus nécessaire de stocker un back buffer et un ZBuffer 4 fois plus grands en mémoire lors de l’utilisation de l’antialiasing 4X. La couleur finale du pixel est déterminée lors de la copie du Tile du cache L2 vers la mémoire centrale et non plus lors de l’échange du front et du back buffer.
Contrairement aux architectures PowerVR précédentes qui effectuaient en plus un tri des triangles pour n’effectuer le shading que sur un seul pixel, éliminant ainsi complètement l’overdraw des surfaces opaques, le moteur de rendu de Larrabee traite les primitives comme un renderer traditionnel, c’est-à-dire dans l’ordre dans lequel elles ont été soumises. De nos jours essayer de limiter d’effectuer le shading plusieurs fois pour un même pixel n’est plus vraiment nécessaire au niveau du hardware vu que la plupart des moteurs 3D effectuent déjà une première passe Z qui remplit le Z Buffer hiérarchique contenus dans les GPU et permet de limiter l’overdraw. En se passant de ce genre de techniques Intel évite ainsi de devoir traiter des cas où ce genre de réordonnancement des primitives pourrait s’avérer problématique et limite ainsi le risque de bugs visuels qui ont pendant un moment handicapés les puces PowerVR.
Comme nous l’avons vu le cache de niveau 2 contient les valeurs du Tile en cours de traitement par conséquent il est très simple de donner accès à la valeur du backbuffer directement dans le pixel shader. Cette fonctionnalité, longtemps réclamée par les programmeurs n’a jamais été disponible dans les GPU, si l’on excepte le Deltachrome de S3 qui en est, soi disant, capable mais ne peut l’exposer faute d’API l’autorisant, et offre un bel éventail de possibilités. On pourra ainsi obtenir du blending complètement programmable, plutôt que se reposer sur les quelques modes disponibles sur les GPU modernes. Toutefois le même problème que pour S3 va se poser : quid de l’API offrant l’accès à ce genre de possibilités ? Tant que les GPU NVIDIA et AMD n’offriront pas une fonctionnalité similaire, on ne la retrouvera pas dans les API 3D. Intel a un avantage puisqu’il affirme que son moteur de rendu sera entièrement customisable par les programmeurs. Il pourra être intégralement remplacé ou les programmeurs pourront juste modifier des briques spécifiques, mais soyons réalistes : quelle société a les moyens d’effectuer des modifications pour une architecture spécifique tout juste disponible ? Les fonctionnalités avancées du moteur de rendu de Larrabee devraient donc rester inexploitées pendant un moment.
Côté GPGPU
Evidemment un des marchés qui intéresse le plus Intel avec Larrabee est celui du GPGPU. Pour cela Intel a mis le paquet : Larrabee devrait supporter l’ensemble des API non propriétaires. OpenCL, Compute Shader et bien évidemment l’API maison Ct seront donc de la partie, pour les programmes offrant un parallélisme de données comme on le trouve sur les GPU. Mais Intel souhaite aussi offrir la possibilité de gérer le parallélisme de tâches comme on le trouve sur les processeurs modernes, pour cela Larrabee supportera des API de type pthreads, OpenMP ou encore Intel TBB.
Intéressons nous tout d’abord à ces deux modèles de programmation parallèle. Le parallélisme de données est celui qui est exploité par les GPU, il consiste comme nous l’avons vu à exécuter un même code (appelé kernel ou noyau en français) sur un ensemble suffisamment large de données différentes (appelé stream ou flux). Il n’a pas de dépendance entre les éléments d’un flux ce qui permet d’exploiter efficacement le parallélisme. Un autre avantage est que cela permet d’utiliser de façon implicite les unités SIMD, la largeur des vecteurs traités par le hardware est transparente pour le programmeur, c’est le compilateur qui se charge de réorganiser les données pour exploiter de façon automatique toutes les unités. Enfin le dernier atout est que si le nombre de données est suffisamment grand il est facile de masquer la latence des opérations mémoires. En contrepartie certains algorithmes se prêtent difficilement à ce modèle de programmation, il faut en effet plusieurs centaines voire même plusieurs milliers d’éléments de préférence, pour pouvoir exploiter correctement toutes les unités.
Le deuxième mode de programmation parallèle, le parallélisme de tâches est celui qu’on observe sur les CPU multi-cœurs comme le Cell ou le Xenon sur consoles et tous les processeurs récents sur PC. Plutôt que d’appliquer une même fonction sur un ensemble de données, il s’agit ici d’identifier quelques tâches indépendantes qui peuvent être exécutées en parallèle, de façon asynchrone. On retrouve cependant les problèmes classiques qui sont désormais familiers des programmeurs : pour utiliser les unités SIMD le programmeur doit le faire de façon explicite. De la même façon le parallélisme de tâches est moins évolutif que le parallélisme de données : une fois que le découpage a été fait pour bien utiliser les ressources d’une architecture donnée, une nouvelle architecture pourra en revanche être sous exploitée si le nombre de tâches n’est pas suffisant. Le programmeur a aussi la charge de gérer la synchronisation des tâches notamment dans le cas d’accès à des ressources partagées. En contrepartie certains algorithmes sont plus adaptés à un découpage de ce type vu qu’il nécessite une granularité moins fine que le parallélisme de données.
Nomenclature et manipulation
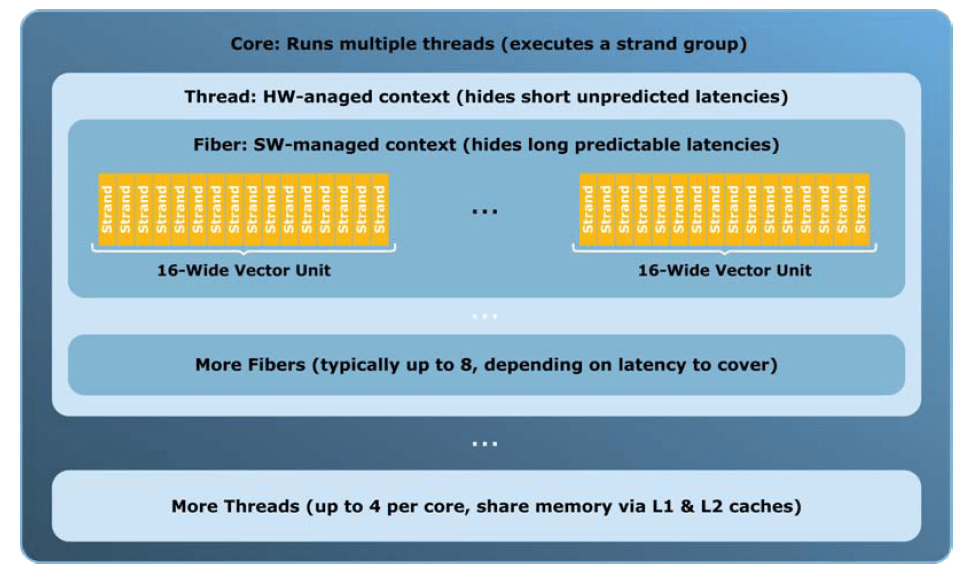
Dans le cas du parallélisme de données, Larrabee se comporte comme un GPU classique même si Intel arrive forcément avec sa propre nomenclature. Ainsi les threads de CUDA sont ici rebaptisés strands, les warps correspondent à ce qu’Intel appelledes fibers quicontiennent de 16 à 64 strands. Enfin les blocs sont ici des threads qui peuvent être composés de 2 à 10 fibers. Un cœur de Larrabee peut exécuter jusqu’à 4 threads. Perdus ? On le serait à moins entre toutes les définitions personnelles de « threads » qui ne désignent pas les mêmes choses ! Avouons tout de même que la définition d’Intel est plus proche de celle qui existe depuis des années alors qu’utiliser ce terme pour désigner un élément d’une unité SIMD, comme le fait NVIDIA, est un peu discutable à notre goût. Mais au fait pourquoi un tel découpage ? Simplement parce qu’alterner entre ces éléments n’a pas le même coût.
Jongler entre plusieurs fibers d’un même threads est un processus très peu coûteux et entièrement logiciel. L’ensemble des données des fibers restant en mémoire cache, l’exécution d’un fiber peut reprendre très rapidement. Ce mécanisme est donc utilisé pour masquer les longues latences comme lors de l’accès à la mémoire centrale. A l’inverse, alterner entre plusieurs threads est une opération matérielle plus coûteuse puisque comme sur un processeur cela demande de sauvegarder le contexte du thread qui va être mis en sommeil et de le restaurer une fois que son exécution sera reprise, il faut toutefois souligner que le SMT permet de limiter ce coût en offrant à chaque thread un ensemble dédié de registres. Les threads sont utilisés pour masquer les latences plus courtes et moins facilement prédictibles.
Le fonctionnement de Larrabee en parallélisme de tâches met en jeu nettement moins de jargon : une tâche est donc une fonction asynchrone, chaque thread est constitué de plusieurs tâches et chaque cœur alterne l’exécution de jusqu’à 4 threads en parallèle. Un des avantages de Larrabee est que comme tout bon CPU, il peut lancer l’exécution de nouvelles tâches à tout moment alors que sur un GPU c’est impossible ; c’est le CPU qui doit lancer l’invocation d’un nouveau programme. Sur Larrabee on peut donc tout à fait envisager voir une tâche lancer l’exécution d’une autre tâche qui exploitera le parallélisme de données. Il est en effet possible de mixer les deux types de programmation parallèle sur Larrabee, c’est d’ailleurs ce que fait Intel dans son moteur de rendu.
Notons enfin qu’il n’est pas nécessaire d’utiliser des runtimes spécifiques pour programmer Larrabee, Intel offre en effet la possibilité de développer des applications natives pour Larrabee qui s’exécuteront directement sur le hardware. Ces applications natives nécessiteront d’être compilées avec un compilateur C/C++ spécial fourni par Intel qui outre un exécutable Larrabee, génèrera aussi un binaire destiné au processeur central dont le rôle sera de charger le programme Larrabee et de lui passer les données nécessaires. Ces applications sont les plus proches du métal possibles, c’est à ce même niveau qu’est exécuté le moteur de rendu logiciel de Larrabee par exemple, qui n’est d’ailleurs rien d’autres qu’une application native Larrabee comme tout le monde pourra en écrire. Intel ne se réserve aucun accès privé au hardware, tout est exposé au programmeur. Evidemment programmer Larrabee de cette façon est plus contraignant qu’en utilisant les API existantes mais c’est de cette manière qu’il sera possible d’exploiter au mieux la nouvelle puce d’Intel.
Conclusion
 N’ayons pas peur des mots : Larrabee est, dans l’esprit, la plus grosse révolution qu’aient connue les cartes 3D depuis leur apparition il y a une douzaine d’années. Il est intéressant de voir la convergence entre deux approches : d’un côté les fabricants de GPU qui en partant d’une architecture extrêmement spécialisée, se sont rapprochés petit à petit de la généralité d’un CPU et de l’autre, Intel qui est parti d’une architecture qui reste fondamentalement celle d’un processeur mais en a augmenté le parallélisme de façon massive afin de tenter de concurrencer les GPU sur leur terrain.
N’ayons pas peur des mots : Larrabee est, dans l’esprit, la plus grosse révolution qu’aient connue les cartes 3D depuis leur apparition il y a une douzaine d’années. Il est intéressant de voir la convergence entre deux approches : d’un côté les fabricants de GPU qui en partant d’une architecture extrêmement spécialisée, se sont rapprochés petit à petit de la généralité d’un CPU et de l’autre, Intel qui est parti d’une architecture qui reste fondamentalement celle d’un processeur mais en a augmenté le parallélisme de façon massive afin de tenter de concurrencer les GPU sur leur terrain.
Quel sera le résultat d’un tel affrontement ? Bien malin celui qui pourra le prévoir, surtout que trop d’inconnues subsistent actuellement concernant les détails d’implémentation de Larrabee : quid de la fréquence et du nombre de cœurs par exemple ? Idem pour le nombre d’unités de textures. Toutes ces données sont encore absentes des publications d’Intel. Pourtant c’est ce genre d’informations qui permettraient déjà d’évaluer le potentiel de Larrabee face à ses concurrents.
Les GPU modernes dépassent déjà le Teraflop de puissance de calculs programmable, les cartes bi-GPU abordables ont même atteint les 2 Teraflops. Pour atteindre une telle puissance de calculs il faudrait au minimum 32 cœurs, cadencés à 2 GHz. Mais d’une part lors de la sortie de Larrabee ces cartes seront dépassées et d’autre part Larrabee avec son absence d’unités fixes, tel le rasterizer ou les ROP, doit effectuer plus de tâches que les GPU sur ses cœurs et devra donc prévoir une certaine marge pour lutter à armes égales avec ses concurrents d’alors. Intel bénéficie certes d’un avantage indéniable au niveau des procédés de gravure mais est ce que cela sera suffisant ?
Outre la puissance de la puce à proprement parler, une autre inconnue, qui aura un fort impact sur les performances de Larrabee, concerne l’efficacité du moteur de rendu logiciel. Même si avec Michael Abrash aux commandes, l’homme à qui l’on doit l’optimisation du moteur de Quake, on peut s’estimer confiant. D’autant que depuis cette époque lointaine, Abrash a continué à travailler sur des moteurs de rendu logiciels au sein de la société Rad Game Tools, avant que cette dernière ne soit rachetée par Intel. Cependant même si les hommes derrières ce moteur bénéficient d’une grande expérience, il est incontestable que, plus encore qu’avec les autres GPU, une grosse partie des performances de Larrabee dépendra de la qualité du logiciel. Les performances seront donc amenées à évoluer de façon sensible au fur et à mesure qu’Intel peaufinera son moteur de rendu en fonction des différents jeux.
Il est donc probable que dans un premier temps Intel n’ait pas l’avantage de la puissance, tout du moins pas de façon déterminante mais il lui reste celui de la flexibilité non ? Après tout Larrabee n’est pas un GPU et permet donc d’implémenter des pipelines de rendu moins traditionnels que la classique rastérisation, sans se casser la tête et sans laisser des unités fixes inoccupées. Là encore il ne faut pas s’attendre à des miracles : comme on le voit un simple changement d’API prends énormément de temps avant d’être vraiment effectif dans les jeux, alors il y a peu de chances que l’on voit fleurir de nouveaux moteurs de rendus totalement conçus pour Larrabee et utilisant des algorithmes exotiques : la tâche est énorme et peu de sociétés ont les moyens aussi bien techniques que financiers de se permettre un tel investissement.
Un espoir ?
Alors au final, pas forcément d’avantage de puissance et une flexibilité qui ne sert à rien : Larrabee ne serait qu’un coup d’épée dans l’eau ? Non, tout d’abord Larrabee a le mérite de mettre un bon coup de pieds dans la fourmilière en débarquant sur le marché avec une architecture radicalement différente. Seule une société avec les moyens d’Intel pouvait se le permettre et cela devrait redynamiser le secteur des GPU. De plus même si la flexibilité de Larrabee ne sera pas exploitée à court terme, cela préfigure sans aucun doute des fonctionnalités qui seront disponibles dans le futur et offre donc un outil idéal à des sociétés comme id Software, Epic ou Crytek pour travailler à leurs prochaines générations de moteurs 3D. Les habituels pensionnaires du Siggraph seront également ravis de disposer de Larrabee pour implémenter leurs toutes nouvelles idées d’algorithmes de rendu sur un hardware aussi flexible.
Finalement une solution idéale pour Intel serait de pouvoir inclure Larrabee à l’une des prochaines consoles qui devraient débarquer sur le marché dans quelques années (on parle de 2012). Sur un hardware fixe les possibilités offertes feraient sans aucun doute merveilles et permettraient aux programmeurs de se familiariser rapidement avec l’architecture Larrabee.
Plusieurs rumeurs ont circulé dernièrement sur une possible inclusion dans la PS4, rumeurs vite démenties par Sony. Il faut dire que voir le Cell et Larrabee se côtoyer dans une même machine ne semble pas vraiment l’idée du siècle : deux processeurs vectoriels très parallèles travaillant avec des jeux d’instructions différents et sur des formats de données propres, on a vu mieux comme synergie et c’est encore un coup à faire s’arracher les cheveux des pauvres développeurs chargés de programmer une telle bête. Le complément idéal de Larrabee serait finalement un simple processeur x86 de base, out-of-order pour se charger du game code qui n’est pas une partie qui se parallélise simplement. Mais Sony n’est sans doute pas prêt à abandonner le Cell après les investissements consentis. D’autant que ce ne serait pas une bonne idée après que les programmeurs aient investis tellement de temps à apprendre à bien l’exploiter, intégrer une évolution de cette architecture permettrait de gagner du temps au lancement de la prochaine génération.
Mais il est inutile de se projeter si loin dans le futur, contentons nous donc pour l’instant d’attendre la date de sortie, forcément trop lointaine, de ce nouveau jouet que nous ne manquerons pas de tester en profondeur le moment venu.