Introduction
 Depuis quelques années le raytracing temps réel semble être devenu le nouvel Eldorado dans le domaine de la 3D temps réel. Cette technique de rendu a connu un vif pic d’intérêt lorsqu’un jeune chercheur du nom de Daniel Pohl lui a consacré un de ses projets de recherche en 2004. L’intérêt du grand public pour ses travaux est surtout venu du fait que Pohl a choisi d’utiliser comme base de travail Quake III (puis Quake IV et enfin Quake Wars), le fameux FPS d’Id Software. Le chercheur a ainsi pu bénéficier d’une couverture médiatique importante et beaucoup de joueurs en voyant ça se sont mis à rêver à des lendemains dorés où les jeux seraient raytracés et où l’on pourrait enfin abandonner la rastérisation.
Depuis quelques années le raytracing temps réel semble être devenu le nouvel Eldorado dans le domaine de la 3D temps réel. Cette technique de rendu a connu un vif pic d’intérêt lorsqu’un jeune chercheur du nom de Daniel Pohl lui a consacré un de ses projets de recherche en 2004. L’intérêt du grand public pour ses travaux est surtout venu du fait que Pohl a choisi d’utiliser comme base de travail Quake III (puis Quake IV et enfin Quake Wars), le fameux FPS d’Id Software. Le chercheur a ainsi pu bénéficier d’une couverture médiatique importante et beaucoup de joueurs en voyant ça se sont mis à rêver à des lendemains dorés où les jeux seraient raytracés et où l’on pourrait enfin abandonner la rastérisation.
 Intel conscient du buzz engendré et voyant là une démonstration idéale justifiant l’augmentation du nombre de cœurs de ses processeurs, s’est empressé d’engager le chercheur et ne manque pas une occasion de nous rappeler que le raytracing est l’avenir de la 3D temps réel. Mais est ce vraiment le cas ? Derrière ces beaux discours quelle est la réalité technique ? Quels sont les véritables avantages du raytracing ? Peut on vraiment l’imaginer supplanter la rastérisation ? C’est à ces questions que nous allons essayer de répondre dans cet article.
Intel conscient du buzz engendré et voyant là une démonstration idéale justifiant l’augmentation du nombre de cœurs de ses processeurs, s’est empressé d’engager le chercheur et ne manque pas une occasion de nous rappeler que le raytracing est l’avenir de la 3D temps réel. Mais est ce vraiment le cas ? Derrière ces beaux discours quelle est la réalité technique ? Quels sont les véritables avantages du raytracing ? Peut on vraiment l’imaginer supplanter la rastérisation ? C’est à ces questions que nous allons essayer de répondre dans cet article.
Les concepts de base
L’idée de base du raytracing est extrêmement simple, elle peut se résumer en quelques mots : pour chaque pixel de l’écran le moteur de rendu lance un rayon qui se propage en ligne droite jusqu’à l’intersection avec un élément de la scène à rendre. Cette première intersection permet de déterminer la couleur du pixel en fonction du matériau de l’élément intersecté mais ce n’est pas suffisant pour obtenir un rendu réaliste. Pour cela il faut aussi déterminer l’éclairage de ce pixel, là encore cela se fait en lançant des rayons, appelés rayons secondaires par opposition aux rayons primaires qui permettent de déterminer la visibilité des différents objets de la scène.
Pour calculer l’éclairage de la scène des rayons secondaires sont lancées vers les différentes sources lumineuses. Si ces rayons sont bloquées par un objet alors l’élément est dans l’ombre pour la source de lumière considérée, sinon celle-ci a une influence sur l’éclairage de l’élément. La somme de tous les rayons secondaires ayant atteints une source lumineuse permet de déterminer la quantité de lumière éclairant notre élément.
Mais là encore ce n’est pas tout, pour obtenir un rendu encore plus réaliste il faut aussi considérer les indices de réflexion et de réfraction du matériau, ou dans d’autres termes quelle quantité de lumière est réfléchie au point d’impact avec le rayon primaire et quelle quantité de lumière passe au travers. Là encore des rayons sont lancés pour déterminer la couleur finale du pixel.
On distingue donc plusieurs types de rayons : les rayons primaires qui permettent de déterminer la visibilité, un peu à l’image du ZBuffer dans le cas de la rastérisation et les rayons secondaires qui sont de trois types différents :
- les rayons d’ombre
- les rayons de réflexion
- les rayons de réfraction
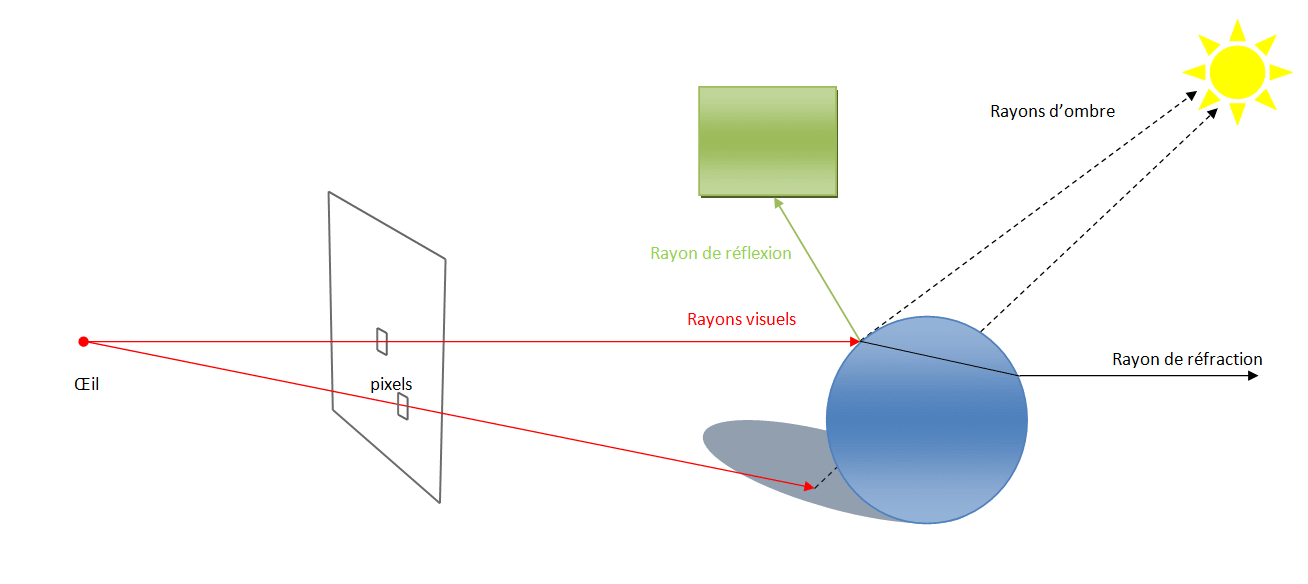
On doit cet algorithme a un chercheur du nom de Turner Whitted qui l’a inventé il y a maintenant 30 ans. Jusqu’alors les raytracers de l’époque se contentaient uniquement des rayons primaires, les améliorations apportées par Whitted ont donc permis de faire un grand pas vers le réalisme des scènes rendues.
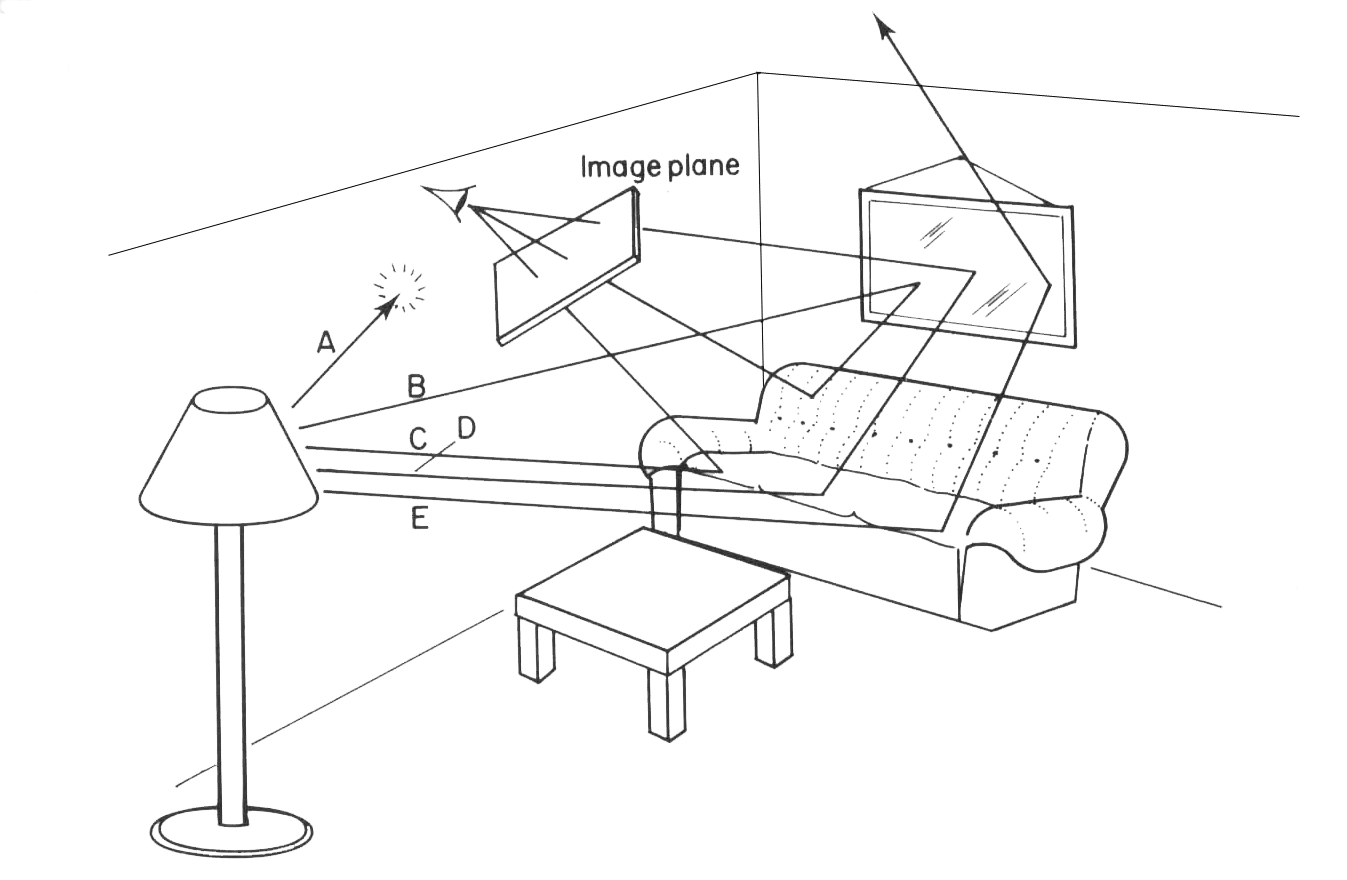
Si vous avez des notions de physique vous n’aurez pas manqué de remarquer que la façon dont le raytracing fonctionne est exactement l’inverse de la façon dont les choses se passent dans le monde réel. En effet, contrairement à une croyance largement répandue au Moyen-âge, nos yeux ne lancent pas de rayons, ils reçoivent les rayons lumineux des sources lumineuses qui ont été détournés par les divers éléments qui nous entourent. Le premier algorithme de raytracing fonctionnait ainsi, mais le principal inconvénient de cette technique est qu’elle était extrêmement coûteuse : pour chaque source lumineuse il fallait lancer des milliers de rayon dont beaucoup n’avaient aucune influence sur la scène générée (ils n’intersectaient pas le plan de l’image). Les algorithmes de raytracing actuels sont donc une optimisation de l’algorithme de base, on parle de Backward raytracing c’est à dire Lancer de Rayons à l’envers, vu que les rayons se propagent en sens inverse par rapport à la réalité.
Les avantages du raytracing
Comme nous venons de le voir un des principaux avantages du raytracing est son élégance. En effet l’algorithme n’utilise qu’une primitive de base pour reproduire des effets qui demandent souvent beaucoup d’astuce et de travail pour être simulés avec un algorithme de rastérisation standard.

Le raytracing excelle notamment au niveau des réflexions. Actuellement avec les moteurs 3D utilisés par les jeux modernes, les réflexions sont calculées à partir d’environment map. Cette technique donne une bonne approximation des réflexions situées « à l’infini » comme celles de l’environnement comme leur nom l’indique, mais dès qu’il s’agit de réflexions d’objets proches cette approche montre ses limites. Les développeurs notamment ceux de jeux de course de voiture, ont réussi à trouver des astuces pour simuler des réflexions proches en utilisant par exemple des cube maps dynamiques : la caméra est placé au niveau de la voiture du joueur et un rendu est effectué dans les directions principales. Celui-ci est stocké dans une cube map qui est ensuite utilisée pour les réflexions.

Mais cette technique a là encore des limites : effectuer plusieurs rendus est coûteux, aussi pour atténuer l’impact sur les performances, le cube map n’est pas recalculé aussi souvent que le rendu principal, il peut donc y avoir une petite latence au niveau des réflexions. Pour limiter l’impact sur le fillrate le rendu est aussi effectué à une résolution plus basse ce qui peut donner un aspect pixélisé aux réflexions. Enfin cette technique se limite bien souvent à la voiture du joueur, les autres devant se contenter d’une simple environment map.
Le raytracing permet de gérer ces réflexions de façon parfaite et sans algorithme compliqué, tout ceci est géré directement par l’algorithme de rendu. Autre avantage extrêmement difficile à rendre avec la rastérisation : les inter-réflexions comme par exemple celle d’un rétroviseur sur la carrosserie. Pour le raytracing cet effet est géré exactement de la même façon que toutes les autres réflexions, à l’inverse c’est un effet extrêmement difficile à reproduire avec la rastérisation.

Les autres avantage
Un autre avantage indéniable du raytracing concerne les effets de transparence. Gérer correctement les transparences est un casse tête avec un algorithme de rastérisation car un calcul exact de transparence dépend de l’ordre du rendu. Pour obtenir un bon résultat il faudrait donc trier les polygones transparents du plus éloigné au plus proche de la caméra avant d’en effectuer le rendu mais en pratique c’est beaucoup trop coûteux, et même ainsi il est possible d’obtenir des erreurs de transparence vu que le tri est effectué par polygone et non pas par pixel. Diverses techniques sont proposées pour éviter de devoir trier la scène (Depth Peeling, A-Buffer) mais aucune ne s’est vraiment imposée pour le moment. Là encore le raytracing permet de gérer les effets de transparence de façon élégante.

Autre avantage et non des moindres : le calcul des ombres. La technique qui a fini par devenir le standard dans le monde de la rastérisation est celle des Shadow Map mais elle souffre de plusieurs problèmes : l’aliasing notamment ou tout simplement l’espace mémoire occupé. Le raytracing permet de résoudre le problème des ombres de façon élégante, là encore sans introduire d’algorithme compliqué, toujours en utilisant la même primitive de base et sans utiliser d’espace mémoire supplémentaire.
Enfin un dernier point fort du raytracing est sa faculté à gérer nativement des surfaces courbes. Les GPU modernes ont depuis quelques années apporté un support intermittent (apparaissant et disparaissant au gré des révisions des drivers et des nouvelles architectures) de ce type de surfaces, mais là où les rasterizers doivent faire une première passe de tesselation afin de générer des triangles qui est l’unique primitive qu’ils sachent gérer en interne, un raytracer peut directement tester l’intersection des rayons avec la véritable définition mathématique de la surface.
Le raytracing : mythes…
Mais le raytracing n’est pas pour autant la solution ultime, il est donc temps de casser l’ensemble des mythes qui l’entourent. Tout d’abord pour beaucoup de joueurs le raytracing est intrinsèquement un meilleur algorithme que la rastérisation car c’est « ce qui est utilisé dans les films ». C’est faux. La majorité des films en image de synthèse (et notamment tous ceux de Pixar) utilisent un algorithme appelé REYES qui repose sur… la rastérisation ! Pixar n’a ajouté le raytracing à Renderman, son moteur de rendu, que tardivement, lors de la production de Cars et même pour ce dernier le raytracing n’a été utilisé qu’avec parcimonie afin d’éviter de voir les temps de calcul exploser. Jusqu’ici Pixar reposait sur un module externe pour les quelques usages qu’ils avaient du raytracing notamment l’occlusion ambiante.

Le deuxième mythe qui est largement entretenu par les défenseurs du raytracing concerne la complexité des scènes qu’il est possible de rendre avec le raytracing et la rastérisation. Pour mieux comprendre il faut se pencher de plus près sur chacun des algorithmes, la rastérisation fonctionne ainsi.
Pour chaque triangle de la scène :
- déterminer l’ensemble des pixels couverts par ce triangle
- pour chaque pixel couvert : comparer sa profondeur à celle du pixel le plus proche jusqu’ici
Comme on le voit la boucle principale de la rastérisation repose sur le nombre de triangles, on dit que l’algorithme a une complexité en O(n) avec n nombre de triangles c’est-à-dire que l’algorithme évolue linéairement en fonction du nombre de triangles car pour chaque image il faut parcourir la liste de triangles, l’un après l’autre.
A l’inverse le raytracing fonctionne ainsi.
Pour chaque pixel de l’image :
- lancer un rayon pour déterminer les triangles potentiellement les plus proches
- pour chaque triangle : calculer la distance du triangle au plan de l’image
Comme on le voit la boucle est en quelque sorte inversée : dans un cas on prend chaque polygone et on cherche quels pixels ils couvrent, dans l’autre on prend chaque pixel et ensuite on regarde à quel polygone il correspond. On peut donc penser que le raytracing est moins dépendant du nombre de triangles que la rastérisation vu que le nombre de triangles ne joue pas dans la boucle principale, mais en pratique ce n’est pas le cas : en effet pour déterminer le triangle qui va être intersecté par notre rayon il faut aussi parcourir l’ensemble des triangles de la scène. Là encore les partisans du raytracing mettent en avant le fait qu’en pratique il n’est pas nécessaire de parcourir TOUS les triangles de la scène à chaque rayon. Il est très facile en utilisant une structure de données adaptée d’organiser les triangles de telle façon que seule une petite partie d’entre eux ait besoin d’être testé pour chaque rayon, ils en déduisent donc que le raytracing a une complexité en O(log n) avec n nombre de polygones.
Et ce point de vue est tout à fait exact, seulement là où il est quelque peu malhonnête c’est qu’il est tout à fait applicable à la rastérisation : les moteurs de jeux ne se privent pas depuis des années pour utiliser des BSP-Tree et autres techniques pour limiter le nombre de polygones à traiter à chaque image calculée. Autre point discutable de ce raisonnement : cette structure de données est particulièrement efficace pour les données statiques. Dans ce cas il suffit de la calculer une fois et ensuite on se contente d’y accéder ce qui donne de très bons résultats, mais qu’en est-il des données dynamiques ? Pour celles-ci la structure de données doit être recalculée à chaque image, et pour la calculer il n’y a pas de miracle il faut examiner chaque polygone.
Un algorithme simple ?
Le dernier mythe concerne la simplicité et l’élégance naturelle de l’algorithme de raytracing. En effet s’il est facile d’écrire un raytracer en quelques lignes de code (certains raytracers fonctionnels ont pu être écrits au dos d’une carte de visite !) écrire un raytracer performant est une autre histoire. David Luebke, un ingénieur de NVIDIA a eu cette remarque totalement adaptée à la réalité : « La rastérisation est rapide mais nécessite de l’ingéniosité pour supporter des effets visuels complexes. Le raytracing supporte des effets visuels complexes mais nécessite de l’ingéniosité pour être rapide ».

Il suffit de lire quelques articles sur les optimisations apportées aux raytracers pour obtenir de meilleures performances afin d’être convaincu de l’exactitude de cette phrase. Par exemple les raytracers les plus performants ne traitent pas les rayons de façon indépendante, ils utilisent ce qu’on appelle des paquets de rayons, ce qui permet d’optimiser les performances lorsque les rayons ont la même origine et une direction proche. Cette optimisation qui s’adapte très bien aux unités SIMD que l’on trouve sur les CPU ou les GPU, s’avère donc efficace pour les rayons primaires qui bénéficient d’une certaine cohérence, ou pour les rayons d’ombre mais en revanche elle n’est pas adaptée du tout aux rayons de réfraction ou de réflexion.
De plus comme le remarque Daniel Pohl dans son article sur Quake Wars RT, utiliser des paquets de rayons peut s’avérer problématique dans le cas de textures transparentes (les fameuses textures alpha utilisées pour les arbres) vu que si tous les rayons d’un même paquet n’ont pas le même comportement (certains touchent la surface et d’autres passent au travers) cela engendre un surcout qui peut vite s’avérer supérieur au gain obtenu en utilisant les paquets de rayon.

Enfin comme nous l’avons noté le raytracing requiert une structure de données performante pour stocker les différents éléments de la scène, c’est elle qui aura un rôle primordial sur les performances obtenues. Mais choisir puis gérer cette structure de données n’est pas évident, certaines ont de meilleures caractéristiques pour les données statiques, d’autres sont au contraire plus rapides pour être mises à jour dans le cas de données dynamiques, d’autres ont un encombrement mémoire moins important. Comme toujours il s’agit de faire trouver un compromis acceptable, il n’y a pas de solution miracle.
Comme nous venons de le voir le raytracing est bien loin du modèle de simplicité et d’élégance que certains laissent supposer. Obtenir de bonnes performances avec un raytracer nécessite d’employer des astuces qui n’ont rien à en envier à celles utilisées par la rastérisation pour reproduire les effets les plus évolués.
Les limites
Maintenant que nous avons pris soin de remettre en place certains mythes associés au raytracing, intéressons nous aux problèmes de cette technique à proprement parler. Commençons par le problème principal de cet algorithme de rendu : il est lent. Alors bien sûr certains diront que ce n’est pas vraiment un problème, après tout le raytracing est largement parallélisable et avec le nombre de cœurs qui augmente chaque année, on devrait avoir une augmentation quasi-linéaire des performances du raytracing. De plus les recherches sur les optimisations à apporter au raytracing sont encore toutes jeunes, lorsqu’on regarde en arrière les premières cartes 3D et qu’on les compare à ce dont nous disposons aujourd’hui on peut donc être optimiste.
Pourtant cette vision des choses laisse de côté un point essentiel : tout l’intérêt du raytracing vient des rayons secondaires, le calcul de visibilité par l’intermédiaire des rayons primaires n’apporte en pratique aucun gain en termes de qualité d’image par rapport à un algorithme de type ZBuffer classique. Le problème est que ces rayons secondaires n’ont absolument aucune cohérence. D’un pixel à l’autre on peut accéder à des données complètement différentes, ce qui met à mal toutes les techniques de cache habituelles qui sont essentielles pour obtenir de bonnes performances. Le calcul des rayons secondaires devient donc extrêmement dépendant du sous-système mémoire et plus particulièrement de la latence, ce qui est la pire situation possible car de toutes les caractéristiques la latence est celle qui a le moins progressé ces dernières années et rien n’indique que les choses soient prêtes à changer. Il est en effet beaucoup plus facile d’augmenter la bande passante en mettant plusieurs puces en parallèle alors que la latence est inhérente à la façon dont fonctionnent les mémoires.
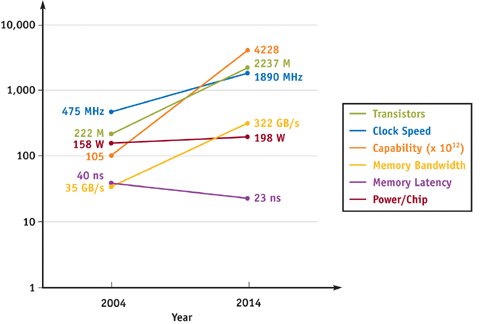
Si les GPU ont eu un tel succès c’est parce que construire un hardware dédié à la rastérisation offrait un résultat extrêmement efficace : la rastérisation a des accès mémoires cohérents qu’il s’agisse de l’accès aux pixels, aux texels ou aux sommets. Ainsi de petits caches couplés à une bande passante massive était la solution idéale pour offrir d’excellentes performances, la bande passante coûte chère mais c’est au moins du domaine du faisable si les enjeux économiques le justifient. A l’inverse il n’existe pas de moyens, même couteux, d’accélérer les accès mémoires des rayons secondaires c’est une des raisons pour lesquels le raytracing ne sera jamais aussi efficace que la rastérisation.
Un autre problème intrinsèque du raytracing concerne l’antialiasing. En effet les rayons lancés ne sont qu’une simple abstraction mathématique, ils n’ont pas de taille à proprement parler. Par conséquent le test d’intersection avec un triangle renvoie un simple résultat booléen : vrai ou faux, mais ne donne pas de détails du style « 40% du rayon intersecte ce triangle ». La conséquence directe de ce comportement est qu’on obtient de l’aliasing.
Alors qu’avec la rastérisation il a été possible de découpler la fréquence de rendu (shading) de la fréquence d’échantillonnage (sampling), ce n’est pas aussi simple avec le raytracing. Plusieurs techniques ont été étudiées pour apporter une solution à ce problème, notamment le Beam Tracing ou le Cone Tracing, qui consistent à donner un volume aux rayons, mais du fait de leur complexité elles n’ont pas vraiment rencontrées un grand succès. La seule technique à offrir de bons résultats consiste donc à lancer plus de rayons que de pixels, revenant donc à effectuer le rendu à une résolution supérieure (supersampling). Il va sans dire que cette technique est largement plus coûteuse que le multisampling utilisé par les GPU actuels.
Un moteur de rendu hybride ?
Arrivé à ce niveau de lecture de l’article vous devriez penser que le raytracing est encore loin d’être prêt à remplacer la rastérisation mais qu’une bonne idée pourrait être, dans un premier temps, de mixer les deux techniques de rendu. En effet elles semblent de prime abord plus complémentaires qu’autre chose et on pourrait très bien imaginer rasteriser les triangles pour déterminer la visibilité afin de bénéficier des excellentes performances de cette technique, et se contenter d’employer le raytracing sur certaines surfaces pour ajouter du réalisme là où cela s’avère nécessaire : ajout d’ombre, de réflexions exactes ou de transparences. Après tout c’est de cette manière que Pixar a procédé pour le rendu de Cars, les modèles géométriques sont rendus avec REYES et il est ensuite possible de lancer des rayons à la demande pour simuler certains effets.

Malheureusement bien que très prometteuse dans l’esprit, cette solution n’est pas facilement applicable. Comme nous l’avons vu, un des principaux inconvénients du raytracing est lié à la structure de données nécessaire pour organiser les objets de façon efficace afin de limiter le nombre de tests d’intersection rayons/objets. Qu’on utilise un modèle de rendu hybride en lieu et place du raytracing pur ne change rien à ce niveau : il faudra toujours mettre en place cette structure de données avec les inconvénients que ça implique. On pourrait par exemple envisager de raytracer les données statiques et d’effectuer le rendu des données dynamiques via la rastérisation mais dans ce cas on perd tout l’intérêt du raytracing : les données dynamiques n’existants pas pour le raytracer, il sera impossible de les voir projeter une ombre ou de voir leurs réflexions.
De plus en termes de performances comme nous l’avons vu le plus gros problème concerne les accès mémoires des rayons secondaires et ce sont typiquement ces rayons là que l’on souhaite conserver dans notre moteur de rendu hybride. Au final le gain de performance obtenu ne serait pas aussi intéressant qu’on peut le penser : la majorité du temps de rendu étant dominé par le calcul des rayons secondaires, le gain obtenu en évitant le calcul des rayons primaires est négligeable.
En clair cette solution risque surtout, en voulant concilier les avantages des deux méthodes, de concilier les inconvénients des deux : en n’obtenant ni l’élégance du raytracing, ni les performances de la rastérisation.
Conclusion
Comme nous venons de le détailler ci-dessus, il reste encore beaucoup de challenges à relever avant de voir le raytracing devenir une alternative crédible à la rastérisation dans le rendu temps réel. Et à bien y réfléchir : est ce vraiment souhaitable ? Les avantages du raytracing ne sont finalement pas assez révolutionnaires pour justifier l’impact de son coût sur les performances. Les points forts de cet algorithme tournent essentiellement autour des réflexions et des transparences, ce sont les deux effets qui sont le plus difficiles à rendre avec l’algorithme de rastérisation actuel mais au final ce n’est pas un si grand inconvénient qu’on pourrait le penser. Le monde qui nous entoure n’est pas vraiment constitué d’objets très brillants ou transparents, de ce fait notre œil est facilement abusé par de grossières approximations.
Il suffit de regarder les simulations de course automobiles récentes comme Gran Turismo ou Forza pour se rendre compte qu’en dépit des réflexions totalement fausses sur les carrosseries, le rendu global est des plus satisfaisant. Ce n’est pas une réflexion exacte du rétroviseur sur la carrosserie qui apportera un avantage suffisant pour donner l’impression d’avoir franchis un cap supplémentaire vers le photoréalisme.

La plupart des gens considèrent le raytracing comme intrinsèquement meilleur que la rastérisation, pour cela ils se basent sur les images obtenues par les moteurs de rendu offline qui offrent un résultat largement supérieur à ce dont on peut rêver dans les jeux actuels. Mais ceci est basé sur la confusion entourant l’algorithme de raytracing. Les images qu’ils comparent à la rastérisation sont en fait la combinaison de plusieurs techniques : raytracing pour les réflexions directes, radiosité pour les réflexions diffuses, photon mapping pour les caustiques… Toutes ces techniques sont combinées pour s’approcher le plus possible de l’équation de rendu écrite par Kajiya.
 Le raytracing dans sa version de base, telle que celle que l’on tente actuellement d’implémenter en temps réel, n’est adapté que pour des réflexions parfaites et des ombres dures. Doom 3 a prouvé, il y a quelques années, qu’il était possible d’obtenir un moteur 3D robuste gérant parfaitement les ombres dynamiques avec la rastérisation, mais avec le recul il a aussi montré que des ombres dures n’étaient pas vraiment réalistes. Pour obtenir des ombres douces, ou des réflexions floues (comme celles obtenues sur du métal brossé par exemple) il faut se tourner vers des techniques de raytracing plus avancées comme le path tracing ou le raytracing distribué, mais ces deux techniques nécessitent un nombre de rayons nettement plus conséquent et sont encore bien loin du temps réel.
Le raytracing dans sa version de base, telle que celle que l’on tente actuellement d’implémenter en temps réel, n’est adapté que pour des réflexions parfaites et des ombres dures. Doom 3 a prouvé, il y a quelques années, qu’il était possible d’obtenir un moteur 3D robuste gérant parfaitement les ombres dynamiques avec la rastérisation, mais avec le recul il a aussi montré que des ombres dures n’étaient pas vraiment réalistes. Pour obtenir des ombres douces, ou des réflexions floues (comme celles obtenues sur du métal brossé par exemple) il faut se tourner vers des techniques de raytracing plus avancées comme le path tracing ou le raytracing distribué, mais ces deux techniques nécessitent un nombre de rayons nettement plus conséquent et sont encore bien loin du temps réel.
Certains pensent qu’à terme, nous disposerons de tellement de puissance de calcul à revendre que l’avantage de performances de la rastérisation ne sera plus un élément déterminant. La loi des rendements décroissants faisant son effet, le gain de performances offerts par la rastérisation sera vite oublié sur l’autel de l’élégance du raytracing, un peu comme le gain de performances offert par la programmation en assembleur n’était pas suffisant pour compenser l’avantage de la programmation avec des langages de haut niveau.
 Mais personnellement nous n’en sommes pas convaincus, ou en tout cas nous sommes encore loin du moment où nous pourrons sacrifier la performance pour l’élégance et la simplicité. Il suffit en effet de regarder ce qui s’est passé ces dix dernières années dans le monde du rendu offline : alors qu’une image du film Toy Story prenait en moyenne deux heures pour être rendue, une image de Ratatouille prenait pour sa part six heures et demie et cela malgré une puissance de calcul multipliée par plus de 400 dans le même temps ! En d’autres termes plus on offre de puissance de calcul aux artistes et de moyens pour l’exploiter et plus ils arriveront à l’absorber.
Mais personnellement nous n’en sommes pas convaincus, ou en tout cas nous sommes encore loin du moment où nous pourrons sacrifier la performance pour l’élégance et la simplicité. Il suffit en effet de regarder ce qui s’est passé ces dix dernières années dans le monde du rendu offline : alors qu’une image du film Toy Story prenait en moyenne deux heures pour être rendue, une image de Ratatouille prenait pour sa part six heures et demie et cela malgré une puissance de calcul multipliée par plus de 400 dans le même temps ! En d’autres termes plus on offre de puissance de calcul aux artistes et de moyens pour l’exploiter et plus ils arriveront à l’absorber.
Si une société comme Pixar, qui peut se permettre de consacrer plusieurs heures de calcul pour produire une image, préfère utiliser le raytracing avec parcimonie du fait de son impact sur les performances, on peut en déduire que le moment où nous aurons de la puissance à ne plus savoir qu’en faire dans le monde de la 3D temps réel pour pouvoir se permettre d’effectuer tout le rendu en raytracing est encore bien loin et qu’il y aura sans doute mieux à faire de toute cette puissance de calculs.