Introduction
Petit retour vers le passé. Nous sommes en 2003, depuis plusieurs années Intel et AMD se livrent une lutte acharnée afin d’offrir des microprocesseurs toujours plus puissants. En quelques années la fréquence a rapidement augmenté du fait de cette concurrence et plus encore sous l’impulsion d’Intel et l’arrivée de son Pentium 4. Pourtant cette situation va soudainement arriver à son terme : après avoir bénéficié d’une augmentation de fréquence soutenue (entre 2001 et 2003 la fréquence des Pentium 4 a ainsi été multipliée par deux, passant de 1.5 à 3 GHz) les utilisateurs doivent désormais se contenter de quelques MHz grappillés difficilement par les fondeurs (entre 2003 et 2005 la fréquence est passée de 3 à 3.8 GHz).
Même les architectures optimisées pour les hautes fréquences comme le Prescott se sont cassées les dents sur ce problème, et pour cause : cette fois il ne s’agissait pas d’un simple défi industriel, les fondeurs venaient tout simplement de se heurter aux lois de la physique. Certains Cassandres se sont mis alors à prophétiser la fin de la loi de Moore mais c’était loin d’être le cas. Bien qu’elle ait souvent été détournée de son sens initial, le véritable sujet de la loi de Moore concerne le nombre de transistors sur une surface de silicium donnée. Pendant longtemps la croissance du nombre de transistors des CPU s’est certes accompagnée d’une augmentation de performance dans le même temps, ce qui explique sans doute la confusion. Mais désormais les choses allaient se montrer plus compliquées : les architectes qui concevaient les CPU se heurtaient à la loi des rendements décroissants. Le nombre de transistors à ajouter pour obtenir un gain de performance donné devenait de plus en plus important et menait tout droit dans une impasse.
Pendant ce temps…
Pendant que les fabricants de CPU se creusaient la tête pour trouver une solution à leurs problèmes, les fabricants de GPU continuaient à bénéficier plus que jamais des avantages de la loi de Moore.
Pourquoi n’étaient ils pas handicapés comme leurs confrères qui concevaient des CPU ? Pour une raison toute simple : les CPU sont conçus pour tirer le maximum de performances d’un flux d’instructions, celui-ci opère sur des données diverses (entiers, flottants), effectue des accès mémoire aléatoires, des branchements… Jusqu’ici les architectes cherchaient à extraire d’avantage de parallélisme d’instructions, c’est-à-dire à lancer le plus d’instructions possibles en parallèle. Ainsi le Pentium a introduit l’exécution superscalaire en permettant de lancer, sous certaines conditions, deux instructions entières par cycle. Le Pentium Pro a pour sa part apporté l’exécution des instructions dans le désordre afin d’utiliser au mieux les unités d’exécution. Le problème est qu’il ya une limite au parallélisme qu’il est possible d’extraire d’un flux séquentiel d’instructions. Par conséquent, augmenter aveuglément le nombre d’unités d’exécution est vain car elles resteront pour la plupart inutilisées la majeure partie du temps.
A l’inverse le fonctionnement d’un GPU est on ne peut plus simple : le travail consiste à prendre un ensemble de polygones d’un côté et à générer un ensemble de pixels de l’autre. Les polygones et les pixels sont indépendants les uns des autres et peuvent donc être traité par des unités parallèles. Un GPU peut donc se permettre de consacrer une grosse quantité de son die à des unités de calcul qui, à l’inverse de celles d’un CPU seront effectivement utilisées.
Autre point de divergence entre les deux unités : les accès mémoire d’un GPU sont extrêmement cohérents : lorsqu’un texel est lu, quelques cycles plus tard on lira le texel voisin, de la même façon lorsqu’un pixel est écrit quelques cycles plus tard un pixel voisin sera écrit. En organisant la mémoire de façon intelligente les performances se rapprochent fortement de la bande passante théorique. Un GPU à l’inverse d’un CPU n’a donc pas besoin d’un énorme cache, son rôle est principalement destiné à accélérer les opérations de texturing : quelques Ko sont donc suffisants pour contenir les quelques texels utilisés dans les filtres bilinéaire ou trilinéaire.
Vive le GeForce FX !
Ces deux mondes sont donc restés étrangers l’un à l’autre pendant longtemps : on travaillait avec un (ou plusieurs) CPU, le GPU n’était bon qu’à produire de jolies images rapidement. Mais un évènement va venir bouleverser tout ça : l’apparition de la programmabilité dans les GPU. Encore une fois initialement il n’y a pas lieu de s’inquiéter pour les CPU : les premiers GPU vantés comme programmables (NV20, R200) sont loin d’être une menace : le nombre d’instructions pour un programme reste limité à une dizaine et ils travaillent sur des types de données exotiques : 9 ou 12 bits à virgule fixe.
Mais la loi de Moore va encore faire son œuvre : non seulement l’augmentation du nombre de transistors permet d’augmenter le nombre d’unités de calcul mais elle permet également d’augmenter leur flexibilité. L’apparition du NV30 va donc être marquante à plusieurs égards. S’il s’agit d’un GPU qui ne restera pas dans les annales pour les joueurs, il va apporter deux éléments importants pour commencer à considérer le GPU autrement que comme un bête accélérateur graphique :
- le support du calcul flottant en simple précision (même s’il ne respecte pas la norme IEEE754)
- le support d’un nombre d’instructions pouvant dépasser le millier
A partir de ce moment toutes les conditions étaient réunies pour attirer quelques chercheurs curieux et toujours à la recherche de davantage de puissance de calcul.
L’apparition du GPGPU : prémices
L’idée d’utiliser les accélérateurs graphiques pour des calculs mathématiques n’est pas récente. Il faut remonter aux années 90 pour en trouver les premières traces. Initialement cela reste très primitif, il s’agit surtout d’utiliser certaines fonctions câblées du hardware comme le rasterizer ou le ZBuffer pour accélérer des tâches comme le path finding ou le tracé de diagramme de Voronoï :
En 2003 avec l’apparition de shaders évolués une étape est franchie, cette fois il s’agit d’effectuer des calculs matriciels sur le hardware de l’époque. Dès cette année là toute une section du Siggraph (« Computations on GPU ») est dédiée à cette nouvelle frange de l’informatique. Il ne s’agit encore que des prémisses de ce qui sera bientôt dénommé GPGPU. Un premier tournant dans ce domaine sera l’apparition de BrookGPU.
Pour bien comprendre le rôle de Brook il faut voir comment les choses se passaient avant son apparition : le seul moyen pour avoir accès aux ressources du GPU en 2003 était de passer par une des deux API graphiques : Direct3D ou OpenGL. Par conséquent les chercheurs qui souhaitaient bénéficier de la puissance de calcul des GPU devaient travailler avec ces API. Le problème est que les personnes en question n’étaient pas forcément expertes de la programmation graphique ce qui compliquait sérieusement l’accès à cette technologie. Là où un programmeur 3D parle de shader, de texture ou de fragment un adepte de la programmation parallèle parle de stream, de kernel, de scatter ou de gather. La première difficulté consiste donc à trouver des analogies entre deux mondes distincts :
- un stream, c’est-à-dire un flux d’éléments de même type peut être représenté sur le GPU par une texture. Pour donner une idée, l’équivalent dans les langages de programmation classiques n’est rien d’autre qu’un tableau.
- un kernel, ou noyau est le programme qui va être appliqué indépendamment à chaque élément du flux, c’est le pixel shader. Conceptuellement on peut voir ça comme la boucle interne d’un programme classique : celle qui va être appliquée sur le plus grand nombre d’éléments.
- pour lire le résultat de l’application d’un kernel sur un stream il faut effectuer un rendu dans une texture. Evidemment il n’y a pas d’équivalent sur un CPU qui a un accès total à la mémoire.
- pour contrôler l’endroit où l’on souhaite écrire en mémoire (scatter) il faut le faire dans un vertex shader car un pixel shader ne peut modifier les coordonnées du pixel en cours de traitement.
BrookGPU
On le voit, même avec ces analogies à l’esprit la tâche reste délicate et c’est là où Brook entre en jeu. Brook est un ensemble d’extensions au langage C, « C with streams » comme il fut présenté par ses créateurs de l’université de Stanford. Concrètement Brook propose d’encapsuler toute la partie gestion de l’API 3D pour exposer le GPU comme un coprocesseur de calculs parallèles. Pour cela Brook se compose de deux modules : d’une part un compilateur qui à partir d’un fichier .br contenant du code C++ et des extensions, va générer du code C++ standard qui sera linké à un runtime offrant divers back-end (DirectX, OpenGL ARB, OpenGL NV3x, x86).
Brook a eu plusieurs mérites, le premier étant de faire sortir le GPGPU de l’ombre et de l’exposer aux yeux du « grand public ». En effet à l’annonce de ce projet plusieurs sites web consacrés à l’informatique se sont fait l’écho de l’arrivée de Brook, en simplifiant parfois de façon caricaturale la réalité : « le CPU est mort, les GPU sont nettement plus puissants et bientôt pourront les remplacer ». 5 ans plus tard ce n’est toujours pas le cas et soyons clairs : ça ne le sera jamais ! En revanche à voir les évolutions successives des CPU qui s’orientent vers de plus en plus de parallélisme (toujours plus de cores, technologie de Simultaneous MultiThreading, élargissement des unités SIMD) et à côté de ça les GPU qui à l’inverse s’orientent vers toujours plus de flexibilité (support des calculs flottants simple précision, des calculs entiers et bientôt des calculs double précision) il semble clair qu’à terme les deux sont destinées à se rencontrer. Qu’adviendra-t-il alors ? Le GPU sera-t-il absorbé par le CPU tout comme le coprocesseur arithmétique avant lui ? C’est possible. Intel et AMD travaillent sur des projets de ce genre mais le temps que cela arrive beaucoup de choses peuvent encore changer.
Mais revenons à notre sujet. Si le premier mérite de Brook a été de populariser la notion de GPGPU, cette API n’a pas eu qu’un rôle de communication : elle a aussi largement simplifié l’accès aux ressources du GPU, permettant à beaucoup plus de monde de commencer à se former à ce nouveau modèle de programmation. En revanche malgré toutes les qualités de Brook il restait encore énormément à faire pour rendre le GPU crédible comme unité de calcul.
Un des problèmes rencontrés venait des différentes couches d’abstraction et en particulier de la surcharge de travail engendrée par l’API 3D qui pouvait être non négligeable. Mais le véritable souci sur lequel les développeurs de Brook n’avaient aucun contrôle venait de la compatibilité. Il n’est pas rare pour les fabricants de GPU d’optimiser régulièrement leurs drivers surtout avec la forte concurrence qu’ils s’opposent. Si ces optimisations sont (la plupart du temps) bénéfiques pour les joueurs, elles pouvaient en revanche briser du jour au lendemain la compatibilité de Brook. Difficile dans ces cas là d’utiliser cette API dans du code de qualité industrielle, destiné à être déployé. Brook resta donc pendant longtemps l’apanage des chercheurs et des programmeurs curieux.
L’API CUDA
Pour autant le succès d’estime de Brook a suffit à attirer l’attention d’ATI et de NVIDIA, les deux géants voyant dans cet intérêt naissant pour ce type d’initiative l’occasion d’élargir un peu plus encore leur marché, touchant ainsi un nouveau secteur qui restait jusqu’ici insensible à leurs prouesses graphiques.
Certains chercheurs à l’origine de Brook ont donc rapidement rejoint les équipes de développement de la firme de Santa Clara pour mettre sur pied une stratégie globale visant à cibler ce nouveau marché. L’idée consistait à offrir un ensemble matériel/logiciel adapté à ce type de calculs : comme les développeurs de NVIDIA connaissent tous les secrets des GPU, plus question de reposer sur une API graphique, elle-même ne communiquant avec le hardware que par le biais d’un driver avec tous les problèmes que cela implique comme nous l’avons vu. L’équipe de développement de CUDA a donc développé un ensemble de couches logicielles pour communiquer avec le GPU.
Comme on le voit sur ce schéma CUDA offre deux API :
- Une API de haut niveau : l’API CUDA runtime
- Une API de bas niveau : l’API CUDA driver
L’API de haut niveau étant implémentée « au dessus » de l’API bas niveau, chaque appel à une fonction du runtime est décomposé en instructions plus basiques gérées par l’API driver. Notons que ces deux API sont mutuellement exclusives : le programmeur doit utiliser l’une ou l’autre mais il est impossible de mélanger des appels de fonction de l’une et de l’autre. Lorsque l’on parle d’API de haut niveau il convient de relativiser : même l’API runtime reste ce que beaucoup considéreraient comme déjà très bas niveau, cependant elle offre des fonctions bien pratiques pour l’initialisation ou la gestion des contextes. Malgré tout ne vous attendez pas à beaucoup plus d’abstraction : elle demande tout de même une bonne connaissance des GPU NVIDIA et de la façon dont ils fonctionnent.
L’API driver est donc plus complexe à gérer, elle demande plus de travail pour lancer un traitement sur le GPU, mais en contrepartie elle est plus flexible, offrant un contrôle supplémentaire au programmeur qui le désire. Notons que les deux API sont capables de communiquer avec des ressources OpenGL ou Direct3D (9 seulement pour le moment). L’utilité est évidente : CUDA pourrait être utilisé pour générer des ressources (géométrie, textures procédurales…) qui seraient ensuite passées à l’API graphique ou à l’inverse on pourrait imaginer que l’API 3D pourrait envoyer le résultat du rendu à CUDA qui serait dans ce cas utilisé pour effectuer un post traitement. Les exemples d’interactions sont nombreux et l’avantage est que les ressources restent stockées dans la RAM du GPU sans nécessiter de passer par le goulot d’étranglement du bus PCI-Express.
A l’inverse soulignons que le partage de ressources, en l’occurrence la mémoire vidéo, avec les données graphiques n’est pas toujours idyllique et peut conduire à quelques petits soucis : dans le cas d’un changement de résolution ou de profondeur de couleur, les données graphiques ont la priorité. Ainsi si les ressources pour le framebuffer doivent augmenter, le driver n’hésitera pas à venir prendre celles allouées aux applications utilisant CUDA, entraînant un plantage de ces dernières. Pas très élégant certes, mais il faut avouer que la situation devrait se présenter peu souvent. Puisque nous en sommes au chapitre des petits inconvénients : l’utilisation de plusieurs GPU par une application CUDA nécessite de désactiver le mode SLI au préalable, sans cela un seul GPU sera visible au niveau de CUDA.
Enfin la troisième couche logicielle est un ensemble de bibliothèques, deux pour être précis :
- CUBLAS qui offre un ensemble de brique de base pour des calculs algèbre linéaire sur le GPU.
- CUFFT qui permet le calcul de transformée de Fourier, un algorithme particulièrement utilisé dans le domaine du traitement du signal.
Quelques définitions
Avant de nous plonger dans CUDA prenons soin de définir au préalable quelques termes qui parsèment les documentations de NVIDIA. La firme Californienne a en effet choisi une terminologie bien particulière qui peut dérouter. En premier lieu il faut définir ce qu’est un thread en CUDA car il n’a pas tout à fait le même sens qu’un thread CPU, et n’est pas non plus équivalent à ce que nous appelons threads dans nos articles sur les GPU. Un thread sur le GPU consiste en un élément de base des données à traiter. A l’inverse des threads CPU, les threads CUDA sont extrêmement « légers » ce qui signifie que le changement de contexte entre deux threads est une opération peu coûteuse.
Deuxième terme fréquemment rencontré dans la documentation de CUDA : warp. Cette fois pas de confusion ce terme n’évoque rien si ce n’est peut être aux « Trekkies » ou aux adeptes de Warhammer. En réalité pour la petite anecdote ce terme vient des machines à tisser, il désigne un ensemble de fils de cotons or (en anglais fil se dit… thread). Un warp en CUDA est donc un ensemble de 32 threads, il s’agit de la taille minimale des données traitées de façon SIMD par un multiprocesseur en CUDA.
Mais cette granularité n’est toujours pas suffisante pour être facilement utilisable par un programmeur, ainsi en CUDA on ne manipule pas directement des warps, on travaille avec des blocs pouvant contenir de 64 à 512 threads.
Enfin ces blocs sont réunis dans des grilles. L’intérêt de ce regroupement est que le nombre de blocs traités simultanément par le GPU est intimement lié aux ressources du hardware comme nous le verrons plus loin. Le nombre de blocs dans une grille permet d’abstraire totalement cette contrainte et d’appliquer un kernel à une grande quantité de threads en un seul appel, sans se soucier de ressources fixées. Le runtime CUDA se charge de décomposer le tout pour nous. Ce modèle est ainsi extrêmement extensible : si un hardware a peu de ressources il exécute les blocs séquentiellement, à l’inverse s’il dispose d’un très grand nombre d’unités il peut les traiter en parallèle. Le même code permet donc de cibler à la fois les GPU d’entrée de gamme, les GPU haut de gamme voire les GPU futurs.
Les autres termes que vous rencontrerez fréquemment dans l’API CUDA sont utilisés pour désigner le CPU qui est ici appelé host (hôte) ou le GPU désigné comme device (périphérique). Après cette petite introduction qui, on l’espère, ne vous aura pas trop refroidi, il est temps de passer aux choses sérieuses !
CUDA d’un point de vue matériel
Fidèle lecteur de Tom’s Hardware, l’architecture des derniers GPU de NVIDIA n’a plus aucun secret pour vous, si ce n’est pas le cas courrez vite rattraper ce manque. Avec CUDA, NVIDIA présente son architecture d’une façon légèrement différente et expose certains détails qu’il n’était pas utile de dévoiler jusqu’à présent.
Comme vous pouvez le constater ci-dessus, le Shader Core de NVIDIA est composé de plusieurs clusters que NVIDIA nomme Texture Processor Cluster. Une 8800GTX est composée par exemple de 8 clusters, une 8800GTS de 6 et ainsi de suite. Chaque cluster regroupe en fait une unité de texture et deux streaming multiprocessors. Ces processeurs sont composés d’un front-end de lecture/décodage et lancement des instructions et d’un back-end composé d’un ensemble de 8 unités de calcul et de 2 unités spéciales, au niveau desquels les instructions sont exécutées de façon SIMD : la même instruction est appliquée à tous les threads du warp. NVIDIA baptise ce mode d’exécution SIMT pour Single Instruction Multiple Threads. Il est important de signaler que le back-end fonctionne à une fréquence double de celle du front-end.
En pratique la partie qui exécute les instructions apparaît donc deux fois « plus large » qu’elle ne l’est (c’est-à-dire comme une unité SIMD 16 voies au lieu de 8 voies). Le mode de fonctionnement des streaming multiprocessors est le suivant : à chaque cycle un warp prêt à être exécuté est sélectionné par le front-end, qui lance l’exécution d’une instruction. Pour appliquer l’instruction à l’ensemble des 32 threads du warp le back-end mettra quatre cycles mais comme il fonctionne à une fréquence double du front-end, il ne se sera exécuté que deux cycles de son point de vue. Pour éviter que le front-end ne reste inutilisé un cycle et maximiser l’utilisation du hardware l’idéal est donc d’alterner les types d’instructions tous les cycles : un cycle une instruction classique et l’autre une instruction de type SFU.
Chaque multiprocesseur dispose également d’un certain nombre de ressources qu’il est utile de connaître afin de les utiliser au mieux. Ainsi ils sont équipés d’une petite zone mémoire appelée Shared Memory d’une taille de 16 Ko par multiprocesseur. Cette mémoire n’est pas une mémoire cache : sa gestion est entièrement à la charge du programmeur. En cela elle se rapproche de la Local Store des SPU du Cell. Cette spécificité est particulièrement intéressante et traduit le fait que CUDA est bien un ensemble de technologies logicielles et matérielles. En effet cette zone mémoire n’est pas utilisée dans le cas des pixels shaders, comme le précise NVIDIA avec humour « nous n’apprécions pas que les pixels parlent les uns avec les autres ».
Point de vue matériel (suite)
Cette shared memoryoffre un moyen aux threads d’un même bloc de communiquer. Il est important de souligner la restriction : tous les threads d’un même bloc sont en effet garantis d’être exécutés par le même multiprocesseur. A l’inverse l’attribution des blocs aux différents multiprocesseurs est complètement indéfinie, deux threads de blocs distincts ne peuvent donc pas communiquer durant leur exécution. Bien utiliser cette mémoire est donc compliqué mais peut se révéler payant car, hormis le cas où plusieurs threads tentent d’accéder à une même banque mémoire ce qui provoque un conflit, le reste du temps l’accès à la shared memory s’avère aussi performant que l’accès aux registres.
La shared memory n’est pas la seule mémoire auquel les multiprocesseurs ont accès, ils peuvent évidemment avoir recours à la mémoire vidéo mais celle-ci offre une bande passante plus basse et une latence plus élevée. Par conséquent pour limiter les accès trop fréquents à cette mémoire NVIDIA a donc doté ses multiprocesseurs de cache (d’une taille d’environ 8 Ko par multiprocesseur) pour l’accès aux constantes ou aux textures.
Les multiprocesseurs disposent aussi de 8192 registres à partager entre tous les threads de tous les blocs actifs sur ce multiprocesseur. Le nombre de blocs actifs par multiprocesseur pour sa part ne peut pas dépasser 8, le nombre de warps actifs étant pour sa part limité à 24 (768 threads). Une 8800 GTX peut donc avoir jusqu’à 12 288 threads en cours de traitement à chaque instant. Connaître toutes ces limites peut sembler rébarbatif mais est utile afin de bien dimensionner son problème en fonction des ressources disponibles.
Optimiser un programme CUDA consiste donc essentiellement à équilibrer au mieux le nombre de blocs et leur taille : plus de threads par blocs s’avère utile pour mieux masquer la latence des opérations mémoires mais d’un autre côté cela diminue le nombre de registres disponibles par threads. De plus un bloc de 512 threads serait particulièrement peu efficace car seul un bloc pourrait être actif sur un multiprocesseur, gâchant ainsi potentiellement 256 threads. NVIDIA conseille donc d’utiliser des blocs de 128 à 256 threads qui offrent le meilleur compromis entre masquage de la latence et nombre de registres suffisant pour la plupart des kernels.
CUDA d’un point de vue logiciel
D’un point de vue logiciel CUDA consiste en un ensemble d’extensions au langage C, qui évoquent des souvenirs de BrookGPU, et en quelques appels d’API spécifiques. Au niveau des extensions on trouve notamment des qualificateurs s’appliquant aux fonctions et aux variables. Le mot clé principal à retenir est __global__. Placé devant une fonction il indique que celle-ci est un kernel c’est-à-dire une fonction qui va être appelée par le CPU et exécutée par le GPU. Le qualificateur __device__ pour sa part désigne une fonction qui sera exécutée par le GPU mais qui n’est appelable que depuis le GPU (autrement dit depuis une autre fonction __device__ ou depuis une fonction __global__). Enfin le mot clé __host__ est optionnel, il désigne une fonction qui est appelée par le CPU et exécutée sur le CPU, autrement dit une fonction traditionnelle.
Notons quelques restrictions associées aux fonctions __device__ ou __global__ : elles ne peuvent être récursives (c’est-à-dire s’appeler elles mêmes) et elles ne peuvent pas avoir un nombre variable d’arguments. Enfin les fonctions __device__ résidant dans l’espace mémoire du GPU il est en toute logique impossible d’obtenir leur adresse. Les variables disposent elles aussi de nouveaux qualificateurs permettant de contrôler la zone mémoire dans laquelle elles seront stockées. Ainsi une variable précédée du mot clé __shared__ indique qu’elle sera stockée dans la shared memory des streaming multiprocessors.
L’appel d’une fonction __global__ est également un peu particulier. Il faut en effet définir lors de cet appel la configuration d’exécution c’est-à-dire plus concrètement : la taille de la grille sur laquelle le kernel est appliqué et la taille de chaque bloc. Exemple un kernel dont la signature est la suivante :
__global__ void Func(float* parameter) ;
Sera appelé ainsi :
Func<<>>(parameter) ;
Avec Dg comme dimension de grille et Db comme dimension d’un bloc. Ces deux variables étant d’un nouveau type vectoriel introduit par CUDA.
L’API CUDA offre quant à elle essentiellement des fonctions de manipulation mémoire en VRAM : cudaMalloc pour allouer de la mémoire, cudaFree pour la libérer ou encore cudaMemcpy pour copier des données entre RAM et VRAM et vice versa.
Terminons ce tour d’horizon par la façon dont un programme CUDA est compilé, qui s’avère intéressante. La compilation est effectuée en plusieurs phases : tout d’abord le code dédié au CPU est extrait du fichier et passé au compilateur standard. Le code dédié au GPU pour sa part est tout d’abord converti en un langage intermédiaire : PTX. Ce langage intermédiaire est proche d’un assembleur et permet donc d’étudier le code source généré et de noter les inefficacités potentielles. Enfin la dernière étape traduit ce langage intermédiaire en commandes spécifiques au GPU et les encapsulent sous forme binaire dans l’exécutable.
En pratique
Difficile, après avoir ingurgité toute la documentation de NVIDIA, de résister à la tentation de mettre les mains dans le cambouis. Après tout quel meilleur moyen de juger une API que d’essayer d’écrire un petit programme l’utilisant ? C’est dans cette situation que se révèlent la plupart des problèmes alors que tout semble parfait sur le papier. C’est aussi le meilleur moyen de voir si nous avons bien assimilé tous les concepts décrits dans la documentation de CUDA.
Rien de plus facile actuellement que de se lancer dans un tel projet : on trouve des outils de très bonne qualité gratuitement, pour ce test nous nous sommes donc basés sur Visual C++ Express 2005 qui offrait tout ce dont nous avions besoin. Le plus dur fut au final de trouver un programme suffisamment simple pour que nous puissions le porter sur le GPU sans y passer des semaines mais qui soit en même temps suffisamment intéressant pour que l’opération ait un minimum d’intérêt. Notre choix s’est porté finalement sur un bout de code dont nous disposions qui calculait à partir d’une heightmap, la normal map correspondante. Inutile de s’éterniser sur les détails de la fonction qui ne présentent pas particulièrement d’intérêt dans le cas présent. Pour être concis il suffit de dire qu’il s’agit d’une convolution : pour chaque pixel de l’image de départ on applique une matrice qui va déterminer, à partir des pixels voisins selon une formule plus ou moins compliquée, la couleur du pixel résultant dans l’image générée. L’avantage de cette fonction est qu’elle est très facilement parallélisable, c’est un cas idéal pour lequel CUDA présente un intérêt.
Répétons le encore une fois : l’objectif de ce test était de se familiariser en pratique avec les outils du SDK CUDA, l’idée n’était pas de faire un bench comparatif entre une version CPU et une version GPU. En temps que premier programme CUDA que nous allions écrire il ne fallait pas s’attendre à des merveilles d’un point de vue performance. De plus, vu qu’elle ne faisait pas partie d’une section de code critique, la version CPU n’était déjà pas optimisée outre mesure, une comparaison directe des résultats n’aurait pas vraiment d’intérêt.
Performances
Malgré cela, nous avons quand même choisi de mesurer le temps de calcul pour vérifier si, malgré notre implémentation naïve, il y avait un intérêt à utiliser CUDA ou si le GPU ne s’apprivoisait qu’après énormément de pratique. La machine de test est notre machine de développement : un ordinateur portable équipé d’un Core 2 Duo T5450 et d’une GeForce 8600M GT le tout tournant sous Vista. C’est bien loin d’une machine de guerre mais les résultats demeurent intéressants car il s’agit d’un cas assez peu favorable pour le GPU : il est bien pratique pour NVIDIA de montrer des accélérations conséquentes sur des systèmes équipés de GPU monstrueux et disposant d’une bande passante énorme, mais en pratique beaucoup des 70 millions de GPU CUDA équipant des PC actuellement sont nettement moins puissants que ça, notre test nous place donc dans un cas pratique.
Les résultats que nous avons obtenus sont les suivants pour le traitement d’une image de 2048×2048 :
- CPU 1 thread : 1419 ms
- CPU 2 threads : 749 ms
- CPU 4 threads : 593 ms
- GPU (8600M GT) blocs de 256 pixels : 109 ms
- GPU (8600M GT) blocs de 128 pixels : 94 ms
- GPU (8800 GTX) blocs de 128 pixels / 256 pixels : 31 ms
Plusieurs observations sont à extraire de ces résultats : tout d’abord vous noterez que nous avons été médisants car nous avons malgré tout modifié l’implémentation initiale du CPU en la threadant. Comme nous l’avons dit le code est idéal pour ce cas de figure, il suffit de décomposer l’image initiale en autant de zones que de threads. Vous noterez que l’on obtient une accélération quasiment linéaire en passant de 1 à 2 threads sur notre CPU dual core ce qui traduit bien la nature fortement parallèle de ce programme de test. De façon assez inexpliquée la version 4 threads se révèle plus rapide alors que nous nous attendions au mieux à ne voir aucune différence sur notre processeur voire même de façon plus logique à une légère perte d’efficacité du fait du surcout engendré par la création des threads supplémentaires. Comment expliquer ce résultat ? Difficile à dire, peut être que l’ordonnanceur de threads de Windows n’est pas totalement innocent là-dessous, en tout cas ce résultat était reproductible. Sur une texture aux dimensions plus réduites (512×512) le gain obtenu en threadant est beaucoup moins sensible (35% environ au lieu de 100%) et le comportement de la version 4 threads est plus logique vu qu’il n’y a aucun gain par rapport à la version 2 threads. Le GPU reste le plus rapide mais de façon moins sensible (la 8600M GT est 3 fois plus rapide que la version 2 threads).
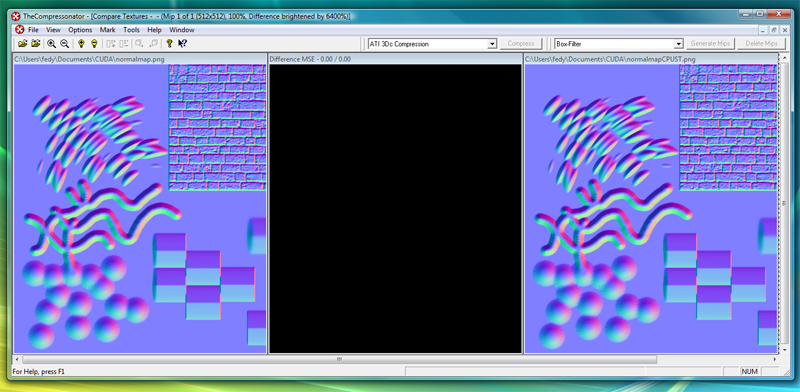
Deuxième point remarquable l’implémentation GPU la plus lente se révèle déjà près de 6 fois plus rapide que la version CPU la plus performante. Pour un premier programme et une version triviale de l’algorithme tout cela est très encourageant. Vous remarquerez aussi que l’on obtient des résultats sensiblement meilleurs en utilisant des blocs plus petits alors qu’intuitivement on pourrait penser l’inverse. L’explication est simple : notre programme utilise 14 registres par threads. Avec des blocs de 256 threads il aurait besoin de 3584 registres par bloc et, pour saturer un multiprocesseur il faut 768 threads comme nous l’avons vu, dans notre cas 3 blocs soit : 10572 registres.
Pas de chance, un multiprocesseur ne dispose que de 8192 registres. Il ne peut donc conserver que deux blocs actifs. A l’inverse avec des blocs de 128 pixels on a besoin de 1792 registres par blocs, 8192 divisés par 1792 et arrondi à l’entier inférieur nous donne 4 blocs en cours de traitement. En pratique le nombre de threads est le même (512 par multiprocesseur alors que théoriquement il en faut 768 pour le saturer) mais le fait d’avoir plus de blocs donne une flexibilité supplémentaire au GPU lors des accès mémoire : lorsqu’une opération ayant une longue latence est exécutée, il peut lancer l’exécution des instructions sur un autre bloc le temps que les résultats soient disponibles. 4 blocs permettent sans doute de mieux masquer cette latence, d’autant que notre programme effectue plusieurs accès mémoire.
Analyse (suite)
Enfin malgré nos beaux discours nous n’avons pas résisté à la tentation d’exécuter ce programme sur une 8800GTX qui se révèle 3 fois plus rapide que la 8600 mobile indépendamment de la taille des blocs. On pourrait penser obtenir un résultat 4 fois supérieur, sinon plus en se basant sur les architectures respectives : 128 ALU contre 32 et une fréquence plus élevée (1.35GHz contre 950 MHz) mais en pratique ce n’est pas le cas. Là encore l’hypothèse la plus vraisemblable est que nous sommes limités par les accès mémoires : pour être plus précis l’image initiale est accédée comme un tableau CUDA multidimensionnel, un terme bien compliqué pour désigner ce qui n’est autre qu’une texture. De cette façon nous bénéficions de plusieurs avantages :
- les accès bénéficient du cache de texture
- nous disposons d’un mode de wrapping, qui nous évite de gérer les cas limites des bords de l’image contrairement à la version CPU
Nous aurions pu également bénéficier d’un filtrage gratuit, d’un adressage normalisé entre [0,1] au lieu de [0, width] et [0, height] mais ça n’était pas utile dans notre cas. Or comme vous le savez en tant que lecteur assidu de Tom’s hardware la 8600 bénéficie de 16 unités de texture contre 32 pour la 8800 GTX. Le rapport n’est donc plus que de deux entre les deux architectures. Ajoutons à ceci la différence de fréquence et nous obtenons un rapport de (32 x 0.575) / (16 x 0.475) = 2.4, on s’approche du rapport X3 observé en pratique. Cette théorie a aussi le mérite d’expliquer pourquoi la taille de blocs ne change pas grand-chose sur G80, les ALU étant de toute façon limitées par les unités de texture.
Outre les résultats encourageants nos premiers pas avec CUDA se sont passés de façon très satisfaisante malgré les conditions pourtant défavorables que nous avions choisies. Développer sur un portable équipé de Vista veut dire obligation d’utiliser le SDK CUDA 2.0 encore en bêta, accompagné du driver 174.55 bêta lui aussi. Malgré tout nous n’avons pas rencontré de mauvaises surprises, juste une petite frayeur lorsque la première exécution de notre programme encore largement buggé a tapé un peu trop loin dans la mémoire, dépassant la place allouée. L’écran s’est alors mis à clignoter frénétiquement avant de passer brusquement au noir…
Le temps pour Vista de lancer le service de récupération de driver vidéo et tout ceci n’était plus qu’un souvenir mais il faut avouer que cela surprend lorsqu’on est habitué à n’obtenir qu’un vulgaire Segmentation Fault dans ce genre de cas sur des programmes standards. Enfin un petit reproche à l’égard de NVIDIA : dans l’ensemble des documentations disponibles pour CUDA il est dommage de ne pas trouver un petit tutorial expliquant pas à pas comment mettre en place son environnement de développement sous Visual Studio. Ce n’est pas trop grave car le SDK est rempli de programmes d’exemples qu’il suffit d’explorer pour comprendre comment faire un squelette de projet minimal pour une application CUDA, mais pour les débutants un tutorial se serait révélé nettement plus pratique.
Conclusion
C’est lors de la sortie des GeForce 8800 que NVIDIA introduisait CUDA. A cette époque les promesses de la firme Californienne étaient définitivement séduisantes mais on ne pouvait s’empêcher de contenir notre enthousiasme. Après tout n’était ce pas juste une manière d’occuper le terrain et de surfer sur la vague du GPGPU ? Sans SDK disponible, comment ne pas craindre que tout ceci ne soit qu’un coup marketing et qu’au final on ne voit rien venir, ou si peu ? Après tout ce ne serait pas la première fois que des bonnes initiatives soient annoncées trop tôt et ne voient finalement pas le jour faute de moyens suffisant pour les mener à terme, surtout dans un secteur aussi concurrentiel. Aujourd’hui un an et demi après cette annonce on peut enfin l’affirmer : NVIDIA a tenu parole.
Non seulement le SDK a été disponible rapidement en version bêta, dès le début de l’année 2007, mais en plus il a été fréquemment mis à jour traduisant l’importance de cette initiative pour NVIDIA. Aujourd’hui CUDA s’est bien développé, le SDK est disponible en version bêta 2.0 sur les principaux systèmes d’exploitation (Windows XP et Vista, Linux, 1.1 pour Mac OS X) et NVIDIA y consacre toute une section de son site dédié aux développeurs.
Non CUDA n’est donc pas un gadget destiné aux chercheurs désireux de se faire offrir une GeForce par leur université, CUDA est vraiment exploitable par tout programmeur connaissant le C au prix toutefois d’un petit investissement personnel histoire de s’adapter à ce nouveau paradigme de programmation. Cet effort ne sera pas une perte de temps pour peu que ses algorithmes se prêtent bien à la parallélisation. Soulignons au passage les efforts de NVIDIA pour fournir une documentation abondante et de qualité afin de répondre à toutes les questions du programmeur débutant.
Conclusion (suite)
Alors que manque-t-il à CUDA pour s’imposer comme l’API incontournable ? En un mot : la portabilité. On le sait, l’avenir de l’informatique est parallèle, tout le monde se prépare à ce changement et toutes les initiatives qu’elles soient logicielles ou matérielles vont dans ce sens. Actuellement en terme de paradigme de développement nous en sommes encore à la préhistoire : créer des threads à la main, en veillant à bien planifier l’accès aux ressources partagées est encore gérable aujourd’hui car le nombre de cores d’un processeur se compte sur les doigts d’une seule main. Mais dans quelques années, lorsque les processeurs en compteront une centaine ce sera inenvisageable. Avec CUDA, NVIDIA propose un premier pas pour résoudre ce problème, mais cette solution est évidemment réservée aux GPU de la firme au caméléon… et pas tous : seules les GeForce 8 et 9 (et les Quadro/Tesla qui en sont dérivés) sont pour le moment capables d’exécuter des programmes CUDA.
NVIDIA peut se vanter d’avoir vendus 70 millions de GPU compatibles CUDA dans le monde, cela reste encore bien insuffisant pour s’imposer comme un standard de fait. D’autant que ses concurrents ne restent pas immobiles : AMD propose son propre SDK (Stream Computing) et Intel a également présenté sa solution (Ct) qui n’est toutefois pas encore disponible. La guerre est donc lancée et il n’y aura pas de place pour trois concurrents, à moins qu’un quatrième larron comme par exemple Microsoft, venait rafler la mise en proposant une API commune ce qui ferait à n’en pas douter le bonheur des développeurs.
NVIDIA a donc encore de nombreux défis à relever pour imposer CUDA. Si d’un point de vue technique il s’agit indéniablement d’une réussite il reste maintenant à convaincre les développeurs qu’il s’agit d’une plate forme crédible et la tâche s’annonce compliquée. Toutefois à en croire les multiples annonces récentes (Les GeForce vont plier des protéines, GPU et mammographie, Nvidia : PhysX sur toutes les Geforce, Mac OS X Snow Leopard pour 2009, entre autres) et à venir autour de cette API il semble que ce soit plutôt bon signe.