Un cadre d’interopérabilité GPU-SSD plus ouvert que ne l’est l’API de Microsoft.
Pas plus tard qu’hier, Microsoft a annoncé le déploiement de son Direct Storage sur PC Windows 10 / 11. Cette API améliore les temps de chargement dans les jeux en se focalisant sur le transfert de données entre le GPU et le HDD / SDD. Cependant, des chercheurs de NVIDIA, d’IBM et de l’université Cornell proposent une alternative intitulée BaM, pour Big Accelerator Memory.
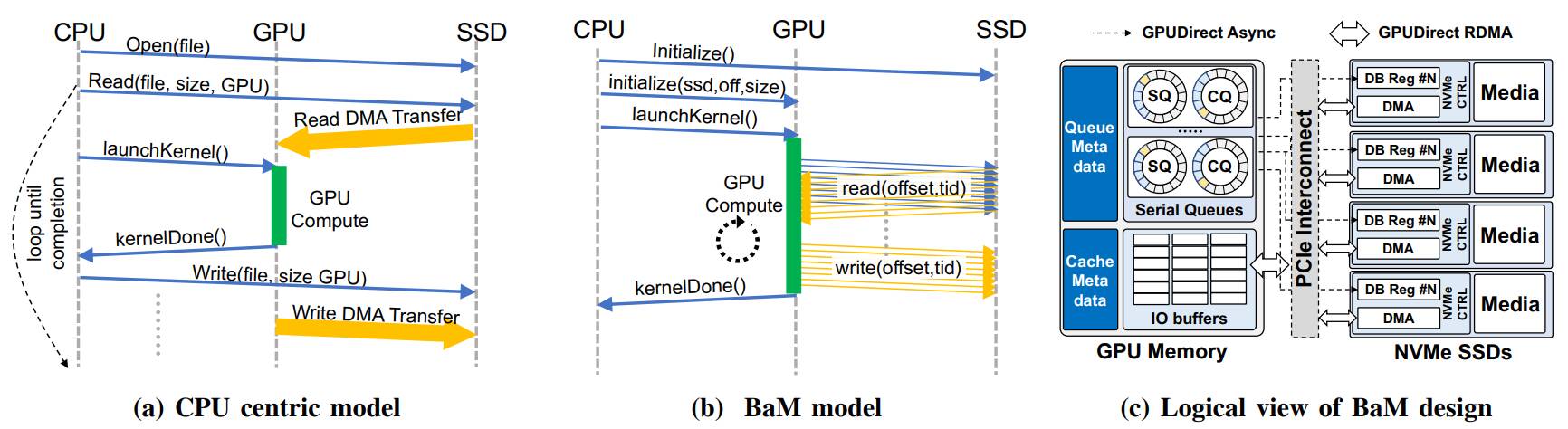
L’article est tout récent puisqu’il date du 9 mars dernier. Pour résumer et vulgariser, BaM permet aux GPU d’aller piocher directement les données dans la mémoire système et le stockage sans passer par le CPU ; elle “émancipe” le GPU du CPU en somme. C’est ce que fait l’API DirectStorage, seulement celle-ci est propriétaire ; les chercheurs définissent ici leur projet comme étant open source.
Au passage, rappelons qu’AMD avait tenté une approche plus ou moins similaire il y a quelques années avec sa Radeon Pro SSG. Sur la page AMD, on peut lire que cette carte embarque 16 Go de mémoire HBM2 mais également 2 To de mémoire graphique à semi-conducteurs (SSG) intégrée.
Explications complètes
Voici comment les chercheurs présentent leur projet :
“Les accélérateurs tels que les unités de traitement graphique (GPU) sont de plus en plus déployés dans les centres de données modernes en raison de leurs capacités de calcul et de leur bande passante mémoire. Ces accélérateurs s’appuient traditionnellement sur le “code hôte de l’application” et le système d’exploitation fonctionnant sur le CPU pour orchestrer leur accès aux dispositifs de stockage des données. L’orchestration par le CPU des accès aux données de stockage fonctionne bien pour les applications GPU classiques, comme l’apprentissage de réseaux neuronaux denses, où les modèles d’accès aux données sont prédéfinis, réguliers, denses et indépendants des valeurs des données, ce qui permet au CPU de partitionner les données de stockage par paquets et de coordonner les accès aux périphériques de stockage et les transferts de données vers les accélérateurs.
Malheureusement, une telle stratégie centrée sur le CPU entraîne des charges de synchronisation excessives entre le CPU et le GPU et/ou une amplification du trafic d’E/S, ce qui réduit la largeur de bande de stockage effective pour les applications émergentes avec des modèles d’accès dépendant directement des données, comme l’analyse des graphes et des données, les systèmes de recommandation et les réseaux neuronaux en graphes.
Dans cette étude, nous proposons de permettre aux GPU d’orchestrer des accès à haut débit et par petits blocs sur le SSD NVMe dans une nouvelle architecture système appelée BaM. BaM atténue l’amplification du trafic d’E/S en permettant aux threads GPU de lire ou d’écrire de petites quantités de données à la demande […]
Nous montrons que (1) le logiciel d’infrastructure BaM s’exécutant sur les GPU peut identifier et gérer l’échange de petits blocs de données à un taux suffisamment élevé pour utiliser pleinement les dispositifs de stockage sous-jacents, (2) même avec des SSD de qualité grand public, un système BaM peut supporter des performances d’application qui sont compétitives par rapport à une solution DRAM seule beaucoup plus coûteuse, et (3) la réduction de l’amplification des E/S peut apporter un avantage significatif en termes de performances.”
Vous pouvez consulter le rapport compet ici.
Sources : Cornell University via The Register, Tom’s Hardware US












come de toutes manières il faudra attendre des apps et des jeux qui permettent d’exploiter cette techno, et vu que sur PC les configurations sont hétéroclite contrairement aux consoles, ça va mettre un peu de temps à se généraliser.