Gravé en 4 nm par TSMC, ce GPU sous architecture Hopper comporte 80 milliards de transistors.
Comme prévu, NVIDIA a révélé les détails de son architecture GPU Hopper et plus précisément de son GPU H100. Ce GPU pour centres de données succède à l’Ampere A100. Précisons d’emblée que l’architecture Hopper se focalise sur le secteur du HPC. Les cartes graphiques grand public GeForce seront basées sur l’architecture Ada. Le GPU H100 doit permettre à NVIDIA de concurrencer plus efficacement les Instinct MI250 / 250X d’AMD.


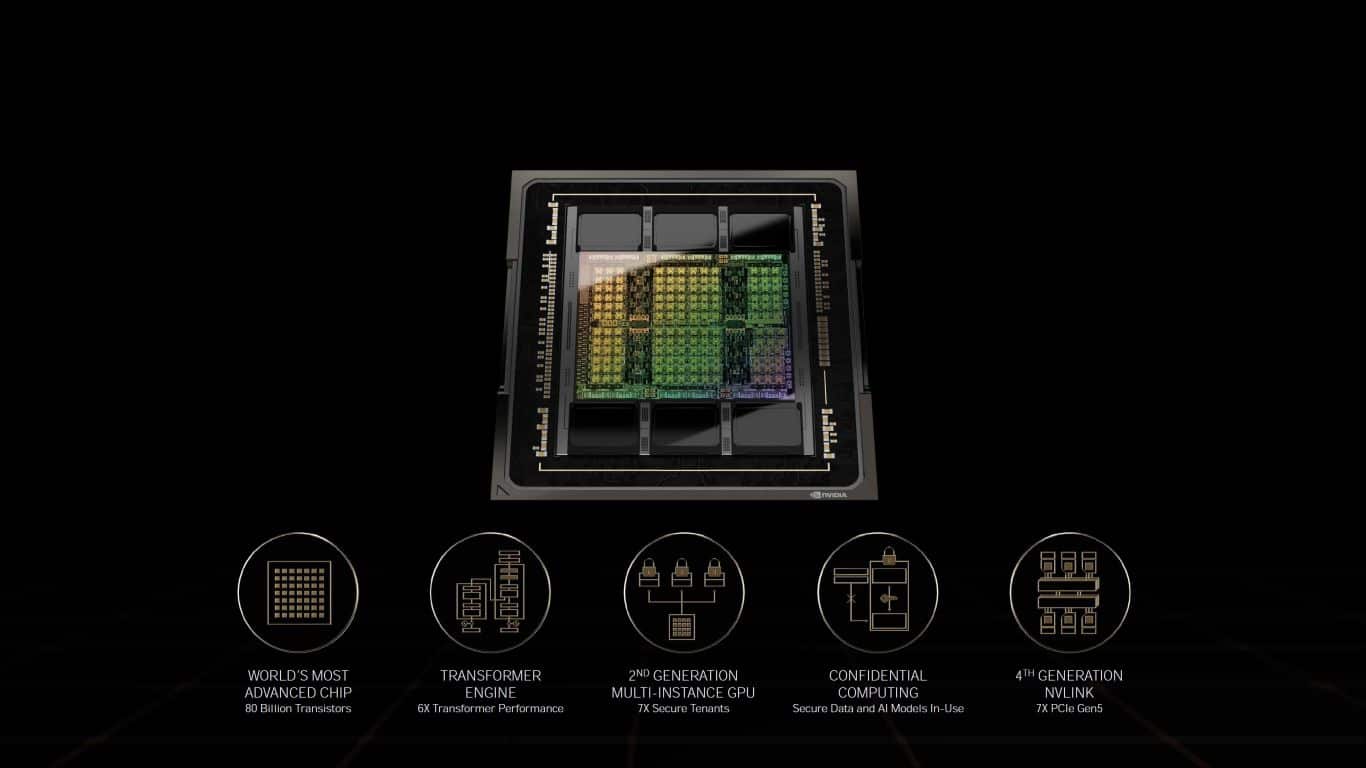
Ce GPU H100 comporte finalement 80 milliards de transistors. En outre, il n’est pas gravé en 5 nm, mais en 4 nm ; plus précisément sur le nœud N4 modifié de TSMC. Pour la comparaison, le GPU A100 est fabriqué à partir du nœud N7 et possède 54 milliards de transistors.
SXM et PCIe
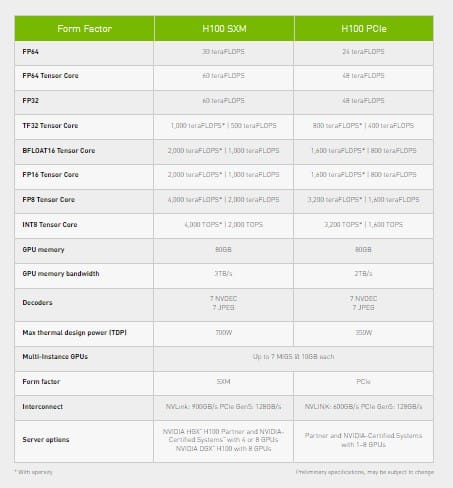
Le H100 prend en charge les interfaces NVLink de quatrième génération et PCIe 5.0. NVIDA décline le H100 dans deux facteurs de forme, SXM et PCIe.
NVIDIA associe le GPU à 80 Go de mémoire HBM3 et annonce une bande passante de 3 To/s pour la solution SXM, de 2 To/s pour la carte en PCIe (mémoire HBM2e). Les vitesses d’interconnexion sont de 900 Go/s avec NVLink pour le H100 SXM, de 600 Go/S avec NVLink pour le H100 PCIe. En PCIe 5.0, les débits maximaux plafonnent à 128 Go/s.
Performances
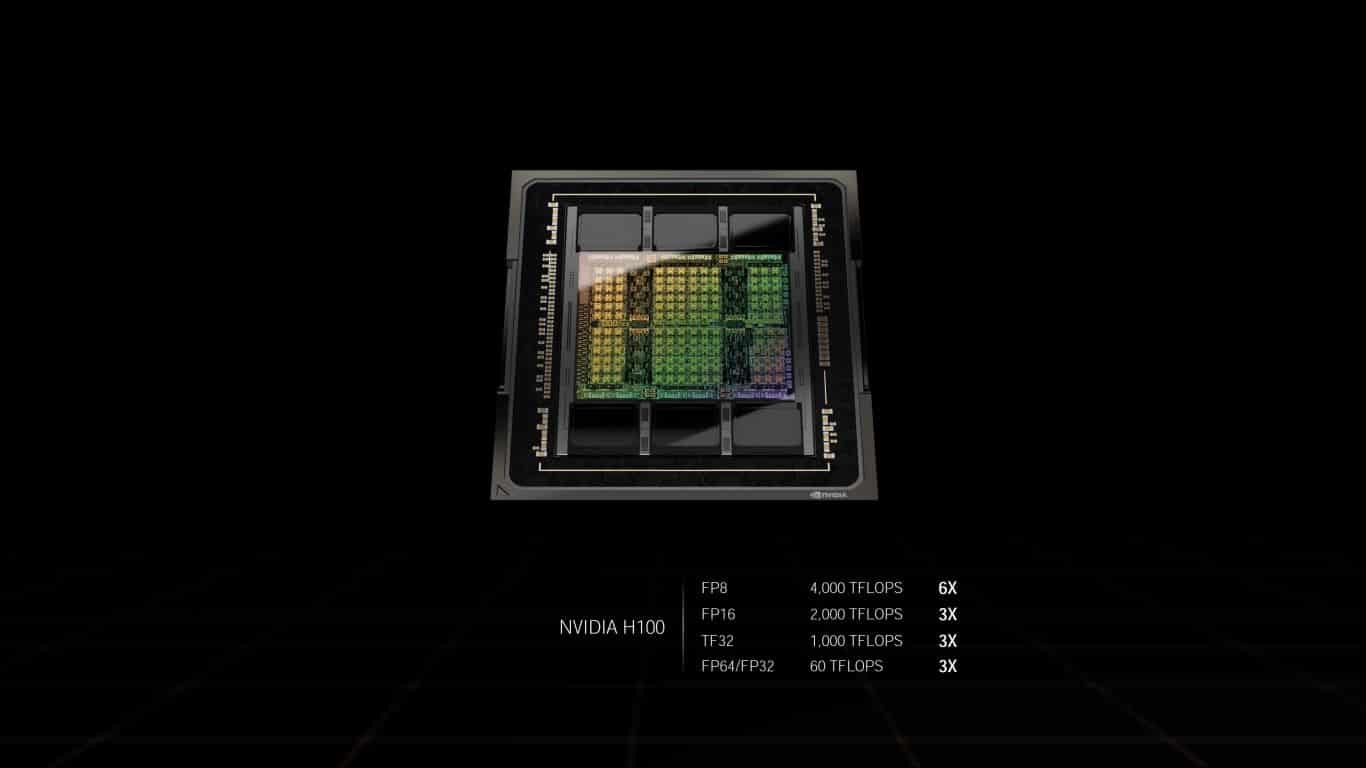
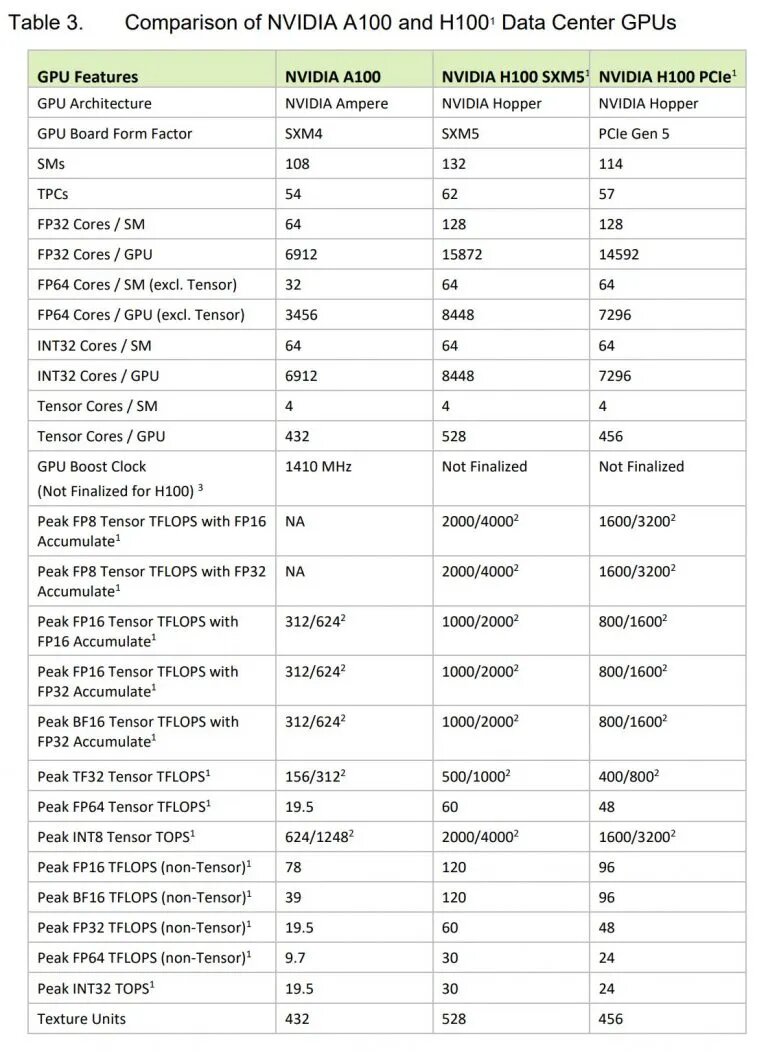
Selon NVIDIA, le H100 affiche des performances FP16 de 2 000 TFLOPS, TFP32 de 1 000 TFLOPS, et FP64 de 60 TFLOPS. Ces valeurs sont trois fois plus élevées que celles de l’A100. Dans l’ensemble, les gains sont compris entre 50 % et 500 % en fonction des charges de travail.
En revanche, le GPU s’avère plus gourmand en énergie que son ancêtre : la variante SXM engloutit 700 W contre 400 W pour l’A100.
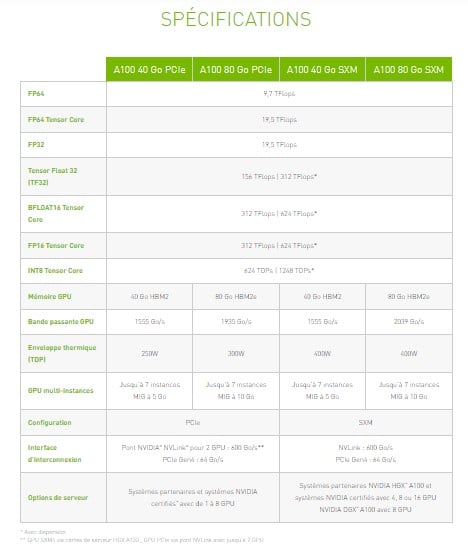
Vous pouvez comparer les écarts avec l’A100 grâce aux tableaux ci-dessous.
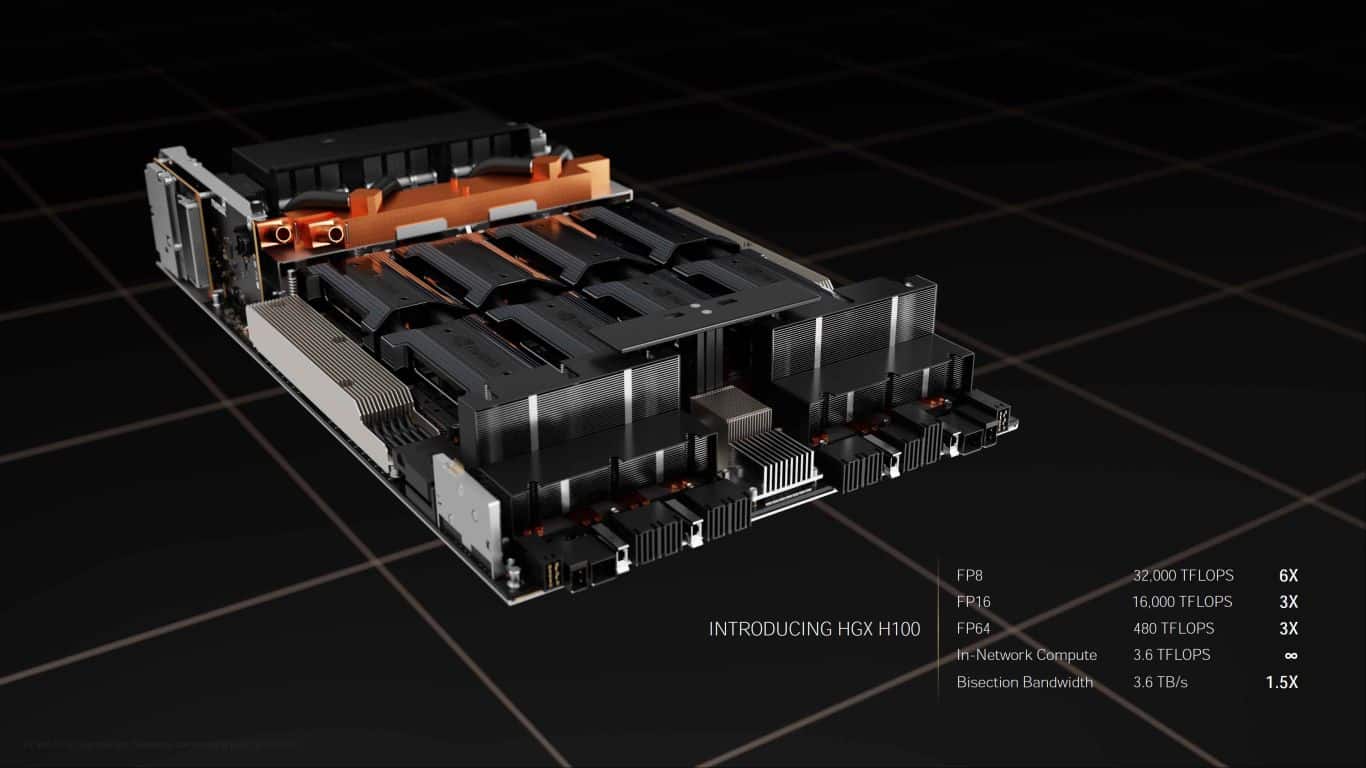
DGX H100
Comme l’A100, le H100 intègre des stations DGX. Chaque système DGX H100 contient huit GPU H100. Un système offre jusqu’à 32 PFLOPS de calcul AI et met à disposition 640 Go de mémoire HBM3. Le DGX H100 dispose également d’une bande passante de 3,6 To/s.


Enfin, 32 systèmes DGX H100 interconnectés via NVLink et Quantum-2 InfiniBand forment un Pod DGX. Un Pod H100 embarque ainsi 256 GPU H100, 20 To de mémoire HBM3 et profite d’une bande passante de 70,4 To/s.



NVIDIA EOS
NVIDIA a annoncé la construction d’un nouveau supercalculateur baptisé EOS. Il se compose de 18 Pods DGX, ce qui représente 4 600 GPU H100. Ce système aura notamment une puissance de calcul de 18,4 EFLOPS FP8 et 9 EFLOPS FP16. NVIDIA précise qu’EOS servira uniquement à des recherches internes. Il sera fonctionnel d’ici quelques mois.













Nvidia a-t-elle annoncé une date de sortie ?
Oui, troisième trimestre 2022.