
Nvidia a pour habitude de tenir sa conférence juste avant l’ouverture du CES et 2015 n’a pas dérogé à la règle. Jen-Hsun Huang avait amené dans ses cartons une grosse nouveauté, le Tegra X1. Ce SoC était connu précédemment sous le nom de code Erista et est le premier de la gamme à embarquer un GPU d’architecture Maxwell. C’est aussi le premier SoC mobile à pouvoir se targuer d’atteindre une puissance de calcul de 1 téraflop, soit 1 000 milliards d’opérations à la seconde.
Denver, déjà un dinosaure ?
Le Tegra X1 contient une bizarrerie : alors que Nvidia a développé à grands frais son propre CPU mobile, Denver, celui-ci est absent du Tegra X1. Nvidia lui a préféré des coeurs ARM standards, quatre Cortex A53 et quatre Cortex A57. Nvidia explique ce choix par une volonté de raccourcir le temps de développement. Denver a été crée en 28 nm et il aurait fallu encore du travail au équipes de Nvidia pour l’adapter à la gravure 20 nm de TSMC. Au contraire, TSMC et ARM mettent à disposition des implémentations Cortex clés en main.
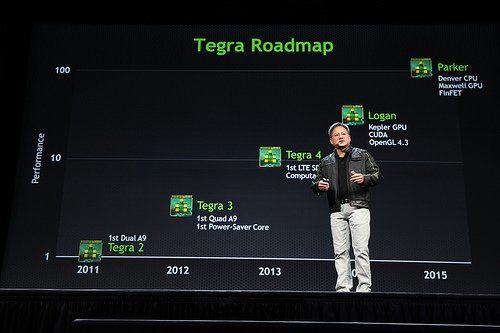
Pour les observateurs les plus attentifs, l’absence de Denver n’est cependant pas une surprise. Le Tegra X1 n’est en effet rien d’autre que le SoC Erista, apparu sur la roadmap du constructeur en mars 2014 en lieu et place de Parker. Parker, tel que présenté en 2013 devait intégrer un CPU Denver, un GPU Maxwell et être gravé en 16 nm FinFET. Deux ans plus tard, Denver et le FinFET sont devenus Cortex A53/A57 et 20 nm classique.
Les performances du X1 devraient cependant être meilleures que celles des autres SoC à Cortex A53/A57, Nvidia n’ayant pas utilisé l’implémentation standard d’ARM. L’interconnexion entre les CPU notamment est propre à Nvidia, tout comme le mode de gestion des coeurs : l’OS ne verra jamais que quatre coeurs, qui seront tour à tour les Cortex A53 pour des temps de veille ou de faible utilisation ou les Cortex A57 pour les applications gourmandes. La migration entre ces deux groupes est gérée via un cache cohérent.
Nvidia promet jusqu’à 40 % de performances en plus (à consommation égale) par rapport au SoC Samsung Exynos 5433 ou 50 % de consommation en moins à performance égale. Les tests à venir nous diront si ces estimations sont vérifiées, mais d’ores et déjà on peut se demander quel avenir aura l’architecture Denver.
Un GPU au moins 50 % plus rapide que Tegra K1
Si la partie CPU peut décevoir, le partie GPU est plus séduisante. Ce coeur Maxwell possède deux SMM de 128 coeurs chacun, soit 256 unités de calcul au total. C’est une nette augmentation par rapport au GPU du Tegra K1, qui ne totalisait que 192 unités. Ces unités sont en outre capables d’exécuter des instructions FP16 deux fois plus rapidement. Sur les précédentes architectures, une instruction FP16 était automatiquement promue FP32 et exécuter sur les unités correspondantes. Le Tegra X1 est plus malin : il est capable de combiner deux instructions FP16 identiques (deux multiplications, deux additions) pour les calculer en un seul cycle sur une unité FP32. Le débit est donc doublé dans le cas théorique le plus favorable : c’est cette astuce qui permet à Nvidia d’annoncer une puissance maximum de 1 téraflops en FP16. Sur des nombres FP32, le Tegra X1 atteint 512 GFlops ; le K1 est à 365 GFlops.
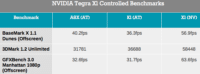
En pratique, les performances seraient entre 1,5x et 2x plus élevées. Nos confrères d’Anandtech rapportent ainsi les résultats suivants, après des tests réalisés devant eux par Nvidia sur une plateforme de référence :
Nvidia met également en avant l’efficacité énergétique de sa puce. En la ralentissant pour maintenir le niveau de performance de l’Apple A8X (dans le test GFX Bench Manhattan 1080p), le constructeur obtient une consommation moyenne de seulement 1,5 W quand le GPU Apple nécessite 2,7 W.
Le Tegra X1 est sur le papier très intéressant. Malheureusement, Nvidia ne se risque pas à donner une quelconque date de disponibilité ni, bien sûr, à annoncer des produits l’embarquant. L’an passé, le Tegra K1 présenté au CES était arrivé à l’été dans sa version 32 bits et à l’automne dans sa version 64 bits.










