Introduction
Personne ne peut prétendre que l’ère des processeurs est révolue. On peut même constater que plusieurs entreprises comme Xilinx vendent encore des dispositifs logiques programmables dont l’intégration des fonctionnalités ainsi que la polyvalence sont nettement inférieures à celles des processeurs modernes. Parfois, la simplicité est gage d’efficacité. Il est vraisemblable que les unités de calcul spécialisées resteront en vogue dans certains segments de marché, tout particulièrement là où le besoin de performances massives est la première des priorités. En revanche, les environnements grand public ne cessent de se diversifier et l’on s’attend donc à ce que le calcul hétérogène – comprendre par là l’intégration de nombreuses ressources de calcul dans un seul composant intégré – continue à gagner en popularité. D’un point de vue conception, ces composants gagneront en complexité eux aussi.
L’aboutissement naturel du calcul hétérogène est le SoC (system-on-a-chip), dans lequel tous (sinon la plupart) les principaux circuits sont intégrés au sein d’une seule puce. Les AMD Geode (sur lesquels s’appuie actuellement le projet « un portable par enfant ») constituent par exemple une évolution des SoC conçus au cours des années 1990. Bien que nombreux SoC accusent encore un déficit de puissance brute pour gérer un PC multi-usages récent, AMD comme Intel vendent des architectures combinant cores CPU, ressources graphiques et contrôle mémoire. Ces APU (accelerated processing unit), tels qu’AMD les appelle, atteignent et même dépassent le niveau de performances que l’on attend de stations de travail spécifiquement orientées productivité. On note tout particulièrement que ces APU associent une conception classique des processeurs à de très nombreuses ALU dont le rôle caractéristique est d’accélérer le rendu 3D, ce qui ne veut pas pour autant dire que ces ressources programmables doivent nécessairement être utilisées pour le jeu : en effet, bon nombre d’autres tâches se caractérisent par un parallélisme naturel. Le fait de les traiter avec un APU muni de centaines de cores plutôt qu’un processeur dual ou quad core ouvre donc un débat intéressant sur le potentiel d’optimisation logicielle pour les SoC à forte intégration.
Historiquement, les circuits graphiques intégrés s’appuyaient sur des fonctions logiques au niveau du northbridge. Cette approche souffrait de sévères goulets d’étranglement et latences, à tel point que l’échelonnement de leurs performances est devenu de plus en plus délicat du fait de l’éloignement des divers composants de la plateforme. On a donc vu cette fonctionnalité migrer vers le CPU, créant ainsi une nouvelle vague de produits non seulement capables de meilleures performances ludiques, mais aussi de traiter un plus grand nombre de tâches à portée générale qui profitent de la nature hybride des SoC (fonctionnalités CPU et GPU).

Pour AMD, cette situation marque le point culminant du projet Fusion, lequel a très probablement motivé l’acquisition d’ATI Technologies en 2006. La firme texane a vu le potentiel offert par l’association de ses propres processeurs à la technologie graphique d’ATI par rapport aux CPU classiques afin d’augmenter sans cesse ses parts de marché ; nul doute qu’AMD était déterminé à être à l’avant-garde de cette transition. De son côté, Intel emploie bien entendu ses propres technologies graphiques, mais le but n’est pas le même : il ne fait aucun doute que le géant de Santa Clara a plus mis l’accent sur ses unités de traitement que sur les technologies graphiques.
Le début de l’année dernière a été marqué par l’arrivée des premiers APU série -C et –E, tous deux gravés en 40 nm. L’intégration a permis d’arriver à produire des modèles basse consommation (9 et 18 Watts), lesquels ont trouvé leur place dans les ultraportables. Aujourd’hui, les APU série –A (Llano) gravés en 32 nm permettent de concentrer suffisamment de ressources afin d’arriver à une architecture digne d’une configuration fixe tout en restant accessibles financièrement parlant.
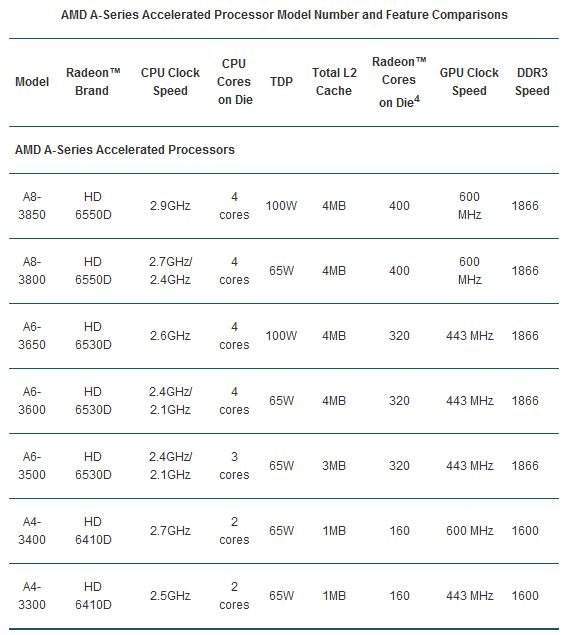
Les spécifications de ces APU varient à plusieurs niveaux, mais le principal différenciateur entre les modèles ci-dessous est probablement la partie graphique. L’A8 s’appuie par exemple sur une configuration décrite par AMD sous l’appellation Radeon HD 6550D, laquelle repose sur 400 Stream processors (ou Radeon cores ou Shaders suivant le terme que l’on préfère employer). L’A6 bénéficie d’une Radeon HD 6530D qui compte 320 stream processors, tandis que la Radeon HD 6410D de l’A4 se contente de 160 stream processors.
Nous avons récemment publié un comparatif de CPU & APU à moins de 200 euros pour évaluer leurs performances ludiques, lequel nous a déjà permis de voir comment se comportaient les APU d’AMD dans ce domaine. Aujourd’hui, le but est de voir dans quelle mesure peut-on profiter de leurs ressources en calcul dans d’autres domaines, et plus particulièrement des tâches qui sollicitent non seulement les cores CPU traditionnels, mais aussi les unités de traitement programmables que l’on trouve dans les solutions graphiques.
Cet article étant le premier d’une série, nous avons fait le choix de nous concentrer exclusivement sur le post-traitement dédié à la vidéo aujourd’hui. Ce domaine s’appuyant largement sur le parallélisme, l’accélération matérielle rendue possible par les nombreux cores d’un processeur graphique est devenu un très bon moyen d’augmenter la productivité et d’améliorer les performances par rapport à un CPU seul.
Dans la pratique, des comparaisons assez simples sont faites entre les différents produits d’AMD (avec qui nous avons été en lien pour cet article) : comment un processeur seul travaille-t-il avec un logiciel accéléré par OpenCL ? Comment s’en tire un APU Llano dans ce même exercice ? Les APU sont ensuite opposés aux CPU avec plusieurs cartes graphiques pour évaluer l’échelonnement des performances en fonction de chaque configuration.
DirectCompute et OpenCL : éléments de contexte
Au cours des deux dernières années, nous avons essayé d’évaluer les efforts consacrés par AMD pour promouvoir Stream de même que l’implémentation de l’infrastructure CUDA chez NVIDIA. Malheureusement, les approches propriétaires limitent sévèrement le nombre de composants que l’on peut opposer entre eux, ce qui rend les comparaisons difficiles.
Depuis un an, AMD a toutefois délaissé son approche propriétaire du GPGPU au profit des API DirectCompute et OpenCL, bien plus courantes dans l’industrie. Grâce à elles, les développeurs peuvent exploiter plus facilement la logique programmable des GPU de manière à traiter les tâches massivement parallélisées plus vite et parfois avec un meilleur rendement qu’un processeur x86 seul. Ces tâches sont bien entendu courantes dans le cas de charges graphiques intenses, mais les développeurs élargissent petit à petit le champ d’application des GPU – et maintenant APU – à d’autres domaines. Les APU pourraient même s’avérer être une solution plus optimisée du fait que leur architecture est idéale aussi bien pour le traitement des SISD (instruction simple, une seule mémoire) que des SIMD (instruction simple, plusieurs mémoires). Si les programmes tendaient à s’appuyer massivement sur l’un ou l’autre par le passé, on voit de plus en plus souvent des interfaces graphiques appliquées aux données logicielles structurées, ce qui rend les approches hybrides du calcul plus tournées vers l’avenir. De son côté, NVIDIA fait encore tout son possible pour promouvoir CUDA mais n’ignore pas OpenCL pour autant : les ForceWare prennent maintenant en charge OpenCL 1.1.

Fin 2006, ATI a commencé à répondre aux attentes des développeurs désireux d’aller plus loin dans les calculs vectoriels SIMD hautement parallèles avec CTM (Close-to-the-Metal). Par la suite, le SDK ATI Stream ainsi que le langage Brook+ et son compilateur ont permis aux développeurs d’exploiter encore plus les processeurs graphiques des Radeon. Néanmoins, une approche plus large et mieux orientée vis-à-vis des standards de l’industrie était nécessaire : c’est là que l’API DirectCompute (issue de la librairie d’API DirectX 11) de Microsoft ainsi que son alternative OpenCL de Khronos Group sont rentrées en jeu. De manière similaire à DirectX et OpenGL, les programmes pour Windows tendent à adopter DirectCompute tandis qu’OpenCL a été conçu dans une optique plus large.
Ces API standard ont eu pour effet de rassurer les développeurs quant à l’adoption de l’accélération GPU/APU, contexte qui tranche radicalement avec l’époque ou AMD comme NVIDIA poursuivaient chacun leur propre intérêt. Si l’on en croit AMD et NVIDIA, l’accélération GPU/APU devrait s’étendre à une plus grande variété de programmes à l’avenir tout en apportant des gains de performances significatifs. Il est prévisible que les GPU haut de gamme ou les APU les plus complexes arrivent aux meilleurs résultats, mais l’intérêt est ailleurs : les APU modestes devraient apporter un gain de performance sensible.
Notons que l’architecture d’AMD permet d’associer un APU avec certains GPU à l’image d’un CrossFire, ce qui pourrait s’avérer intéressant pour faire évoluer en douceur une configuration basée sur un APU seul dans un premier temps. Cette fonctionnalité multi-GPU n’a pas été abordée aujourd’hui, mais nous y viendrons peut-être lors d’un prochain article.
Configuration du test
Lors de la préparation de cette série d’articles, nous nous sommes demandés ce qu’il était nécessaire d’expliquer en matière d’accélération DirectCompute/OpenCL. C’est un domaine facile d’accès vu que les pilotes des cartes graphiques activent cette fonctionnalité par défaut, sachant que la plupart des programmes pouvant en tirer parti proposent généralement un choix activé/désactivé simple au possible. A priori, il n’y a aucune raison de désactiver l’accélération matérielle mais il faut reconnaitre que cette possibilité facilite grandement les benchmarks.
Nous utilisons deux logiciels aujourd’hui pour évaluer l’apport du post-traitement OpenCL : Total Media Theater (TMT) 5.2 d’ArcSoft ainsi que vReveal de MotionDSP.
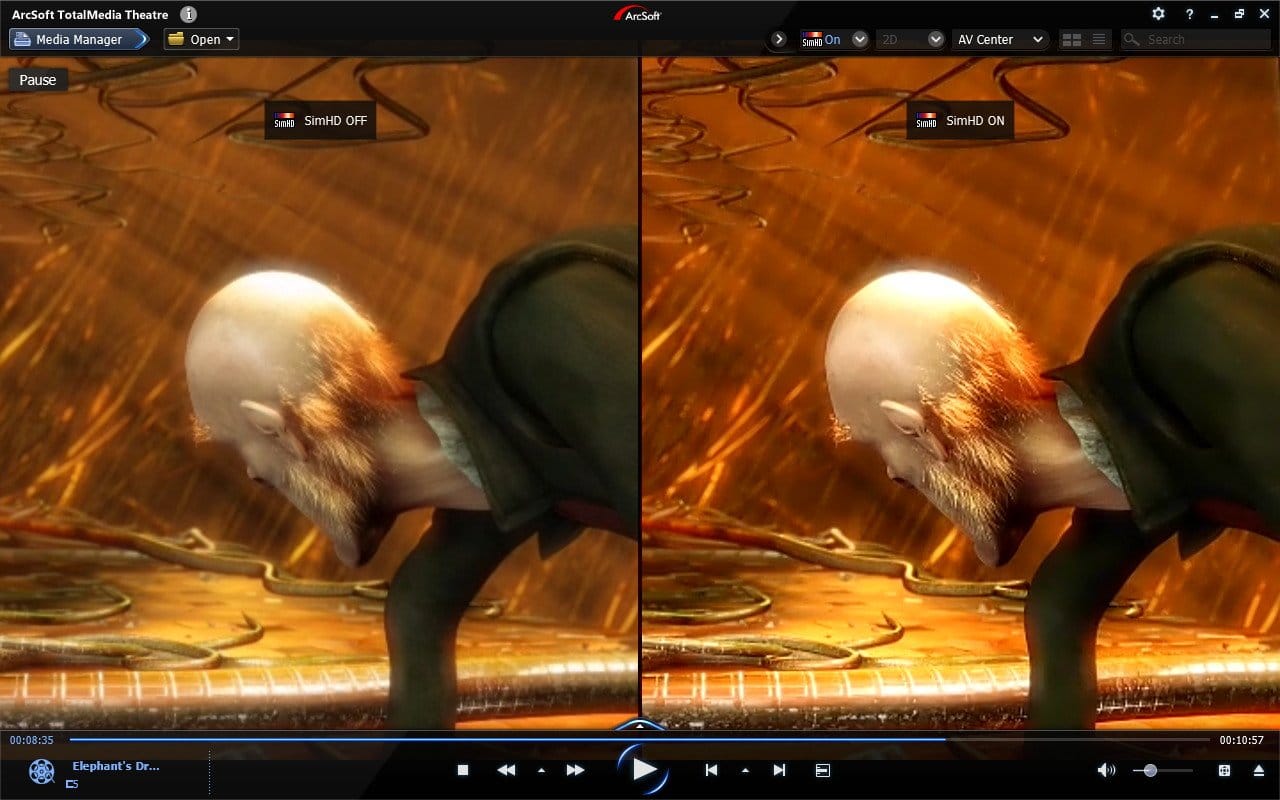
L’extension SimHD de TMT s’appuie désormais sur OpenCL et le traitement GPU pour interpoler des signaux vidéo en définition standard (480p) vers du 720p en temps réel. Pour évaluer cette possibilité, nous avons utilisé le DVD de Minority Report avec (GPU) et sans (CPU) OpenCL : la comparaison a ensuite été faite en écran partagé avec le flux vidéo SD à gauche et le flux 720p à droite. ArcSoft propose quatre principales fonctionnalités au sein de SimHD : mise à l’échelle, éclairage dynamique, réducteur de bruit et adoucissement. Nous n’avons toutefois testé que les trois premières en poussant les réglages au maximum du fait que l’adoucissement n’est pas disponible lorsque le processeur gère seul le rendu vidéo. D’autre part, SimHD a été testé avec une Radeon HD 5870 du fait que notre version pré-sortie de Total Media Theater ne s’accommodait pas de notre Radeon HD 7970. Cela n’a rien de surprenant étant donné que les Radeon HD 7770 et 7750 testées la semaine dernière ont elles aussi connu des difficultés à gérer l’accélération matérielle sous Media Espresso (CyberLink).
De son côté, vReveal de MotionDSP s’est fait connaître en étant le premier logiciel grand public à gérer les problèmes de mouvements parasites dans les vidéos. La puissance de calcul nécessaire à appliquer une stabilisation en temps réel est considérable puisque le logiciel doit analyser plusieurs images en même temps et recalculer de nombreux paramètres. En 1080p, vReveal peut ainsi mettre plus d’une configuration à genoux. La troisième version du logiciel de MotionDSP propose plusieurs fonctionnalités additionnelles parmi lesquelles l’augmentation de la netteté, de l’éclaircissement et le réducteur de bruit, lesquelles peuvent donc toutes être appliquées en même temps que la stabilisation. Le rendu est idéalement fait en temps réel, mais encore faut-il avoir les ressources nécessaires pour cela.
Les vidéos utilisées avec vReveal sont celles qui sont incluses avec la version téléchargeable du logiciel, à savoir « Barcelona » et « San Francisco », respectivement en 480 et 1080p. Deux tests ont été conduits pour chaque vidéo : stabilisation seule, puis stabilisation avec cinq effets additionnels. Naturellement, nous avons évalué l’impact de ces réglages sur un processeur seul, avec accélération APU et enfin avec accélération GPU à l’aide de deux différentes cartes graphiques dans ce dernier cas.
| Configuration n°1 | |
|---|---|
| Processeur | AMD FX-8150 (Zambezi) 3,6 GHz, Socket AM3+, 8 Mo de cache L3 partagés, Turbo Core activé, 125 Watts |
| Carte mère | Asus Crosshair V Formula (Socket AM3+), chipset AMD 990FX/SB950 |
| DRAM | 8 Go (2 x 4 Go) AMD Performance Memory AE34G1609U2 (1600 MT/s, 8-9-8-24) |
| Stockage | Patriot Wildfire 240 Go SATA 6Gb/s |
| Cartes graphiques | AMD Radeon HD 7970 3 Go |
| AMD Radeon HD 5870 1 Go | |
| Alimentation | PC Power & Cooling Turbo-Cool 860 Watts |
| Os | Windows 7 Professionnel 64 bits |
| Configuration n°2 | |
| Processeur | AMD A8-3850 (Llano) 2,9 GHz, Socket FM1, 4 Mo de cache L2, Radeon HD 6550D intégrée, 100 Watts |
| Carte mère | Gigabyte A75-UD4H (Socket FM1), chipset AMD A75 FCH |
| DRAM | 8 Go (2 x 4 Go) AMD Performance Memory AE34G1609U2 (1600 MT/s, 8-9-8-24) |
| Stockage | Patriot Wildfire 240 Go SATA 6Gb/s |
| Cartes graphiques | AMD Radeon HD 7970 3 Go |
| AMD Radeon HD 5870 1 Go | |
| Alimentation | PC Power & Cooling Turbo-Cool 860 Watts |
| Os | Windows 7 Professionnel 64 bits |
| Configuration n°3 | |
| Plateforme | Portable Gateway NV55S05u |
| Processeur | AMD A8-3500M (Llano), 1,5 GHz, Socket FS1, 4 Mo de cache L2, Radeon HD 6620G intégrée, 35 Watts |
| DRAM | 4 Go Elpida PC3-10600S-9-10-F2 2 Go Hynix PC3-10600S-9-10-B1 |
| Stockage | Western Digital Scorpio Blue 640 Go, 5400 tr/min, 8 Mo de ache, SATA 3Gb/s |
| Os | Windows 7 Home Premium, 64 bits |
| Configuration n°4 | |
| Plateforme | Portable HP Pavillion dv6 |
| Processeur | Intel Core i5-2410M (Sandy Bridge), 2,3 GHz, Socket G2, 3 Mo de cache L3 partagés, HD Graphics 3000, 35 Watts |
| DRAM | 4 Go Samsung PC3-10600S-09-10-ZZZ |
| Stockage | Seagate Momentus 7200.4 500 Go, 7200 tr/min, 16 Mo de cache, SATA 3Gb/s |
| Os | Windows 7 Professionnel 64 bits |
Questions/Réponses avec ArcSoft
Outre le fait que Total Media Theater soit un des lecteurs vidéo les plus connus sur PC, son extension SimHD qui permet une mise à l’échelle des vidéos SD avec plusieurs autres options fait partie des précurseurs en matière d’accélération GPU. Kam Shek, directeur du marketing technique chez ArcSoft, s’est livré à un jeu de questions/réponses pour nous donner un aperçu de la transition vers l’accélération basée sur OpenCL.
Tom’s Hardware : Peu de gens sont conscients des efforts, notamment financiers, qu’exigent les fabricants de composants pour arriver à créer des logiciels parés pour le futur. ATI et NVIDIA poussent bien entendu dans leur intérêt à l’adoption d’OpenCL. Dans quelle mesure cet intérêt trouve-t-il un écho chez ArcSoft ?
Kam Shek : Nous avons optimisé nos logiciels sur plusieurs points. Pour AMD, nous avons ajouté la prise en charge du décodage vidéo par l’UVD, ce qui inclut notamment l’accélération matérielle de l’ASP (Advanced Simple Profile) pour le MPEG-4. Nous avons aussi notre technologie SimHD qui est notre propre solution de mise à l’échelle, laquelle a récemment été portée en OpenCL. En fait nous avons utilisé ATI Stream par le passé, mais vu l’émergence du standard OpenCL, nous avons commencé il y a environ 6 mois à travailler dans cette direction en lien rapproché avec AMD.
TH : Pourquoi avoir choisi OpenCL ?
KS : OpenCL nous permet d’avoir un environnement hétérogène, ce qui veut dire que nous pouvons programmer sous OpenCL quels que soient les algorithmes destinés à être traités par le CPU ou le GPU.
TH : Qu’est-ce qu’ArcSoft gagne en passant d’approches propriétaires comme Stream ou CUDA à OpenCL ?
HS : Un des points clés est qu’OpenCL est un standard libre, là où ATI Stream était propriétaire. Ensuite, OpenCL nous permet de mieux répartir la charge entre CPU et GPU. Il faut que je vous en dise un peu plus sur ce que l’on fait avec SimHD. SimHD ne s’arrête pas à la mise à l’échelle. L’extension a plusieurs unités de traitement dont la mise à l’échelle bien entendu, mais aussi la réduction du bruit vidéo, le filtre anti-blocs, l’accentuation des contours, l’éclairage dynamique etc. Certains algorithmes sont de par leur nature mieux gérés par le CPU. Dans le cas d’algorithmes qui basculent entre les deux unités de traitement comme c’est très souvent le cas avec l’éclairage dynamique, le CPU est beaucoup plus efficace. Par contre, les calculs haute précision à virgule flottante sont mieux traités par le GPU. On pense donc notre algorithme de manière à ce que chaque fonction soit traitée par l’unité de calcul qui obtient les meilleurs résultats, après quoi nous répartissons la charge de travail de manière équilibrée.
TH : Avez-vous une idée du ratio d’optimisation CPU contre GPU ?
KS : Sur notre plateforme AMD, le taux d’utilisation CPU baisse d’environ 10 % tandis que celui du GPU grimpe d’environ 20 %
TH : Lorsque l’on augmente le taux d’utilisation GPU de 20 %, on économise donc 10 % sur le CPU ?
KS : Oui, je n’ai pas les chiffres exacts en tête mais c’est effectivement entre 15 et 20 %.
TH : Est-ce qu’il existe des considérations particulières lorsque l’on code pour un APU et non pas un GPU ?
KS : Non, dans une perspective OpenCL, c’est la même chose. Ceci dit, nous formulons une requête vis-à-vis des capacités graphiques avant de lancer les algorithmes. Si la partie graphique a plus de Stream cores disponibles, on lancera donc plus d’algorithmes, mais en général c’est du pareil au même. Nous n’avons donc pas besoin de fichiers binaires spécifiques aux cartes graphiques ou APU, mais il y a tout de même une nuance. Comme je l’ai dit plus tôt, le GPU est mieux adapté pour les calculs haute précision à virgule flottante. L’équivalent CPU de ces algorithmes est en quelque sorte une adaptation partielle, ce qui fait que la précision n’est pas aussi élevée qu’avec un GPU. A contrario, l’algorithme pour GPU est plus complexe et permet donc d’atteindre un meilleur niveau de précision.
Questions/Réponses avec MotionDSP
vReveal de MotionDSP est la déclinaison grand public d’Ikena, logiciel qui vise des clients bien spécifiques comme par exemple les agences gouvernementales et autorités de contrôle. Bien qu’il aient leurs limites, les algorithmes de MotionDSP peuvent produire des résultats assez incroyables. Cependant, ce genre de procédé post-traitement est particulièrement gourmand en ressources. A quoi peut-on s’attendre concrètement ? C’est ce que nous avons cherché à savoir au travers d’un entretien avec le directeur technique (Nik Bozinovic) et le directeur général (Sean Varah) de MotionDSP.
TH : Dans quelles circonstances êtes-vous venus à l’accélération matérielle ?
SV : Lorsque nous avons démarré il y a cinq ans, il n’y avait pas d’approche simple pour programmer les GPU. En fait, on travaillait déjà sur nos propres algorithmes en 2008 et nous avons pris conscience à cette époque que la vidéo passait progressivement de la SD vers la HD, ce qui devait logiquement entrainer un besoin croissant de calcul à hautes performances. Il s’agit d’une évidence pour traiter la vidéo en temps réel, ce qui était un impératif pour notre produit professionnel. Le besoin en calcul hétérogène a donc été une évidence pour nous bien avant qu’il ne le soit globalement, et bien avant que des acteurs comme AMD et NVIDIA ne commencent à militer en ce sens. Le calcul hétérogène était annoncé depuis des années mais en réalité, ça ne fait qu’un à deux ans que l’on voit enfin la promesse de performances dignes d’un supercalculateur avec un GPU se concrétiser. Très franchement, les récentes évolutions ont eu un impact très conséquent sur notre stratégie.

TH : Comment utilisez-vous les possibilités de calcul hétérogène dans vos produits ?
SV : Il y a plusieurs utilités. L’une d’entre elles … en fait plusieurs choses posent problème en simultané tout au long d’une vidéo. Il est rarissime d’avoir le périphérique d’acquisition parfait dans des conditions parfaites, surtout dans le cas des particuliers. Les problèmes peuvent venir de la résolution, du bruit vidéo, de l’éclairage ou encore de la stabilisation. C’est pourquoi nous avons réuni plusieurs filtres vidéo dans vReveal pour résoudre ces problèmes, sachant que le logiciel est très facile d’accès vu qu’il suffit d’un clic pour les faire agir. C’est parce que nous utilisons le calcul hétérogène que l’expérience utilisateur est aussi conviviale.
NB : parallèlement à la stabilisation, nous avons un réducteur de bruit que nous appelons filtre de nettoyage. Nous proposons aussi un réglage automatique pour la luminosité, l’accentuation des contours, l’amélioration du contraste et comme Sean l’a dit, tout cela est automatique, l’utilisateur n’est pas abandonné face à une complexité repoussante. C’est là que le calcul hétérogène se montre extrêmement précieux. Nous avons plusieurs outils de traitement et d’analyse vidéo avancés qui s’appuient sur le calcul hétérogène. Voici quelques exemples : vReveal permet en quasi temps réel de créer une image panoramique à partir de vidéos en filé dynamique (panning). On peut aussi prendre une photo panoramique, cliquer sur un bouton dans vReveal et assembler un panorama composé dans Ikena, notre programme professionnel. De manière similaire à l’assemblage de panoramas à la volée, on peut aussi créer des mosaïques gigantesques, ce qui ne serait pas possible sans l’aide du GPU. Bien entendu, nous avons commencé comme entreprise spécialisée dans le traitement vidéo mais avec l’utilisation des GPU, nous sommes maintenant bien au-delà de notre activité initiale.
TH : Concrètement, qu’est-ce que vos logiciels ne pourraient pas faire sans accélération GPU ?
SV : Et bien le rendu en temps réel ne serait pas possible sans le GPU.
NB : C’est particulièrement vrai avec les médias à haute résolution, parce qu’au-delà du goulet d’étranglement en calcul que l’on supprime avec le GPU (ou plus généralement le calcul hétérogène par opposition au calcul CPU seul), on résout également un problème de bande passante. Pour que notre logiciel marche et parvienne au résultat désiré, il faut examiner plusieurs images en même temps (de 2 à 30,40 voire 50). C’est un problème de mémoire ou bande passante plus qu’une question de calculs. En exécutant ce genre de tâches sur un GPU, on arrive à une situation gagnant-gagnant puisque simple fait de copier une multitude d’images non compressées en haute définition est ingérable pour un CPU. Il y a pratiquement un ordre de grandeur différent entre la bande passante d’un CPU et celle d’un GPU.
Questions/Réponses avec MotionDSP (suite)
TH : Il y a quelques temps, nous étions arrivés à la conclusion que le simple fait d’activer l’accélération GPU apporte un vrai gain de performances et qu’il n’est pas nécessaire pour cela d’investir une fortune dans une carte graphique haute de gamme gérant le GPGPU. La situation a-t-elle changé ? Les APU ont le mérite d’intégrer la possibilité d’accélération GPU d’origine.
SV : Ce qui a changé c’est qu’une entreprise comme AMD vend maintenant des puces Fusion qui combinent CPU et GPU sur le même die. Vous avez raison : auparavant, il fallait avoir un processeur et une carte graphique pour arriver au meilleur rapport performances/prix, ce qui se traduisait tout de même par un investissement considérable pour un portable comme une configuration fixe. Là où Fusion fait fort, c’est que le GPU embarqué de la plateforme Llano est par exemple vraiment performant compte tenu de son format. Pour un budget de 400 à 500 euros, on peut maintenant acheter un portable 15 pouces qui va vraiment faire des merveilles avec notre logiciel, sachant qu’avant cela, il fallait mettre environ 900 euros dans un portable avec une carte graphique dédiée pour arriver au même résultat.
NB : Prenons une autre perspective. Un processeur haut de gamme récent d’AMD ou Intel coûte entre 200 et 300 euros. A coût égal, un GPU peut afficher 3 à 5 fois plus de performances. Avec une carte graphique aux alentours de 250 euros, notre logiciel affichera un nombre d’ips trois à cinq fois plus élevé. Partons maintenant du principe que l’on achète un processeur à 1000 euros. Comme je l’ai dit, quelques cas de goulets d’étranglements engendrés par le traitement d’une multitude d’images sont ingérables avec un processeur à cause de la bande passante mémoire et des limites en calcul. Il faut comprendre que l’on est face à un mur, la gamme du processeur n’a plus d’importance. On peut arriver à 6 ou peut-être 7 images par seconde sans possibilité d’aller au-delà, tandis que les limites inhérentes à un CPU ne se retrouvent pas sur un GPU.

SV : Nik et moi parlons de deux choses différentes. Ce que je dis, c’est qu’un portable à 400 ou 500 euros basé sur Llano permet d’atteindre un niveau de performances qui demandait un investissement de 900 euros il y a peu de temps. De son côté, Nik dit que le rapport performances/prix d’une carte graphique est 3 à 5 fois plus élevé que celui d’un processeur.
NB : Les CPU peuvent généralement mieux gérer les flux vidéo que les GPU si l’on parle exclusivement de vidéo SD. Le fait est qu’aujourd’hui, n’importe qui peut faire de la capture en 720p voir 1080p avec un iPhone ou un smartphone Androïd or c’est là que le GPU creuse l’écart avec le CPU. Comme Sean l’a dit, un portable à 500 euros permet d’avoir les performances d’une tour à 1500 euros de l’époque qui a précédé le calcul hétérogène, tout simplement parce que l’on ne pouvait pas s’appuyer sur le calcul parallèle à ce moment-là.
TH : AMD, NVIDIA et même Intel s’intéressent maintenant de très près à OpenCL. NVIDIA persiste toutefois à mettre CUDA en avant au motif de mieux tirer parti des composants, tandis qu’Intel semble vouloir faire tourner OpenCL sur ses cores CPU. En tant que développeur, vous avez bien évidemment intérêt à offrir la prise en charge la plus large possible, mais techniquement parlant, qu’est-ce que ces différentes stratégies entrainent ?
NB : En tant qu’éditeur de logiciels, l’idéal serait d’avoir un standard unique qui soit fonctionnel sur toutes les architectures. Parce que propriétaire, CUDA nous intéresse moins qu’OpenCL actuellement. Ceci dit, CUDA a été la première technologie GPGPU à voir le jour, NVIDIA a donc du mérite. Mais nous avons été franchement impressionnés par la vitesse de développement des outils sur OpenCL ainsi que toute la chaine logicielle, du SDK aux utilitaires pour Runtime en passant par le fonctionnement des pilotes. Nous avons constaté une réelle implication, sachant que j’ai le point de vue d’un éditeur de logiciels, alors que la situation n’était pas aussi rose il y a 12 à 18 mois. Il était alors très délicat voire impossible pour nous de promettre un produit stable tirant profit du calcul hétérogène sous OpenCL. Tout a changé l’année dernière. AMD est le constructeur derrière le développement et l’implémentation d’OpenCL en ce moment ; on ne sait pas encore ce qu’Intel arrivera à en faire avec Ivy Bridge, mais ARM a déjà annoncé son intention de s’y mettre.
ArcSoft Total Media Theatre & SimHD
Comme nous l’avons évoqué plus tôt, AMD n’a pas encore peaufiné l’accélération matérielle de sa dernière architecture GPU en date, tandis que la HD 5870 ne pose aucun problème. Ses 1600 shaders à 850 MHz lui permettent encore d’afficher des performances tout à fait respectables dans les jeux récents malgré ses deux ans et ½ d’existence, ce qui nous rend donc particulièrement curieux vis-à-vis de son potentiel en calcul.
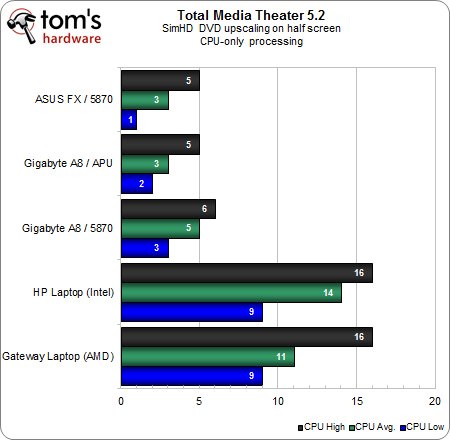
Pour ce premier test, le post-traitement a été confié au seul CPU et l’accélération matérielle désactivée. Les taux d’utilisation processeur bas, moyens et élevés sont exprimés en pourcentages afin de voir quelle est la fourchette de ressources CPU nécessaire pour la mise à l’échelle sous SimHD. Les deux plateformes mobiles évoluent à des niveaux comparables et l’on peut attribuer le léger avantage au portable AMD du fait qu’il bénéficie de 4 cores CPU.
Les résultats des configurations fixes sont plus intéressants. Le taux d’utilisation est environ deux à trois fois plus faible par rapport aux portables, ce qui est logique du fait que les deux processeurs mobiles affichent un TDP de 35 Watts contre 100 et 125 Watts pour l’APU et le FX d’AMD.
Notons tout particulièrement le très faible écart entre l’APU A8 et le FX pourtant plus orienté haut de gamme. Bien que ce dernier compte plus de transistors dédiés au calcul général, un cache L3 conséquent et des fréquences supérieures, il n’affiche presque aucun gain de performances par rapport à l’A8. Il y a donc sans aucun doute un goulet d’étranglement autre part.
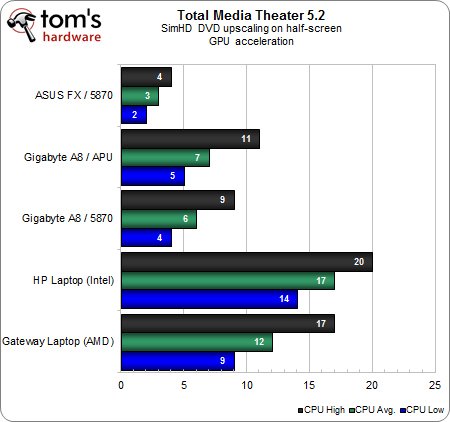
Avec l’accélération GPU, le notebook équipé d’un APU se détache de celui d’Intel qui ne compte que sur son CPU, bien que l’écart ne soit pas aussi grand que ce à quoi l’on pouvait s’attendre. Tout gain de performances est bon à prendre lorsque l’on parle de composants alimentés par une batterie, mais on constate aussi que ces gains grimpent en flèche lorsque c’est une configuration fixe qui traite l’extension SimHD.
A carte graphique identique (HD 5870), l’écart entre AMD FX et AMD A8 varie du simple au double, signe que le logiciel est limité par les ressources CPU de l’A8. SimHD fait donc feu de tout bois.
Si l’on considère le rapport performances/prix, l’A8 et sa Radeon HD 6550D est par contre le grand gagnant : il faut savoir qu’un A8-3850 coûte 120 euros en moyenne. L’APU traduit donc la volonté d’associer deux technologies pour un prix contenu, là où il aurait fallu un processeur entrée de gamme et une carte graphique pour obtenir le même résultat par le passé (de plus, la Radeon HD 5870 est tout sauf un produit entrée de gamme).
vReveal sur FX-8150 et Radeon HD 5870
Là encore, il s’agit d’évaluer l’apport de l’accélération DirectCompute/OpenCL sachant que le plus difficile est encore d’identifier l’environnement que l’on prend comme base de référence. Est-ce que le signal 480p d’un DVD est encore acceptable ou bien doit-on prendre au minimum une source 1080p ? Doit-on estimer que les utilisateurs de vReveal se contenteront de la stabilisation ou bien faut-il prendre en compte tous les filtrages ? Au final, nous avons tenu compte de ces quatre variables tout en jouant sur l’accélération matérielle par GPU.
Les données sont analysées en termes de taux d’utilisation CPU, de répercussion sur les performances ainsi qu’en vitesse d’exécution. Plutôt que d’exprimer les résultats en images par seconde (ce qui n’a pas d’intérêt vu que l’on atteint 30 ips pour le plus en décoller), vReveal donne le pourcentage du travail de rendu effectué en temps réel. Cet indicateur a probablement plus de sens pour une majorité d’utilisateurs : si une séquence vidéo d’une minute est traitée à 50 % en temps réel, cela signifie que le rendu prendra deux minutes au total.
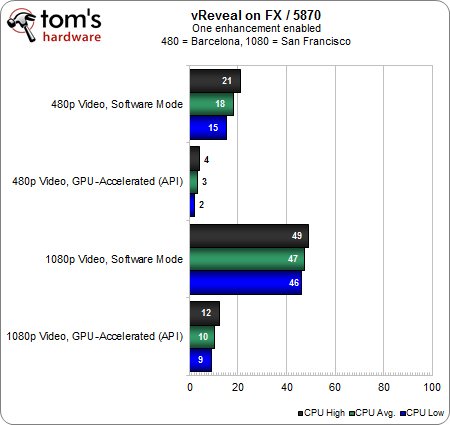
En principe, on devrait constater d’une part que l’accélération GPU décharge significativement le CPU, et d’autre part qu’un flux vidéo 1080p consomme nettement plus de ressources qu’un flux 480p.
Lorsque la Radeon HD 5870 bénéfice de l’accélération OpenCL, elle gère si facilement un seul filtrage post-traitement du flux 480p qu’elle décharge presque intégralement l’AMD FX de cette tâche. Il ne faut pourtant pas imaginer que le processeur soit à l’abri pour autant : sans accélération vidéo, ce même filtrage unique appliqué à un flux 1080p nécessite pratiquement la moitié des ressources processeur. Une fois l’accélération GPU activée, on tombe à 10 %, ce qui confirme la possibilité de multiplication des performances par 4 ou 5 grâce au calcul matériel.
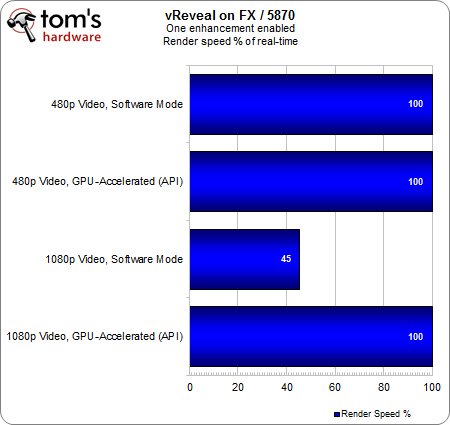
Quel gain de temps procure l’accélération GPU ? Avec un seul filtrage actif, même notre séquence 1080p est traitée en temps réel. On note que le clip 480p peut être rendu en temps réel quelle que soit la solution choisie, tandis que la séquence 1080p nécessite un temps de traitement pratiquement double si l’accélération matérielle est désactivée.
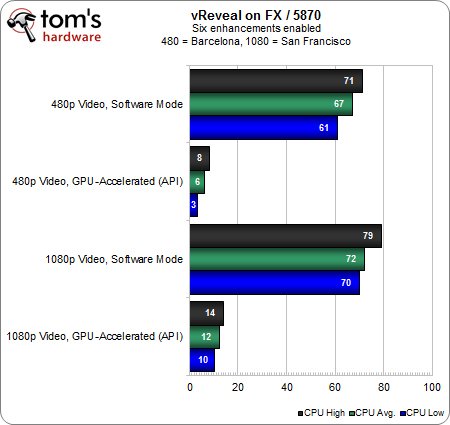
Voyons maintenant ce qu’il en est lorsque l’on applique 6 filtrages post-traitement en simultané. Chose intéressante, l’écart entre les séquences 480 et 1080p est assez négligeable lorsque le plus performant des processeurs AMD est seul en charge : les 6 filtrages en simultané nécessitent la large majorité des ressources CPU et ce quelle que soit la résolution.
Une fois l’accélération matérielle activée sur la Radeon HD 5870, l’augmentation des performances est encore plus frappante qu’avec un seul filtrage : on passe ainsi à un facteur 11x en 480p et 6x en 1080p. En parallèle, il est intéressant de remarquer que la charge de travail est deux fois plus élevée avec la séquence 1080p par rapport à la séquence 480p lorsque 6 filtrages sont appliqués.
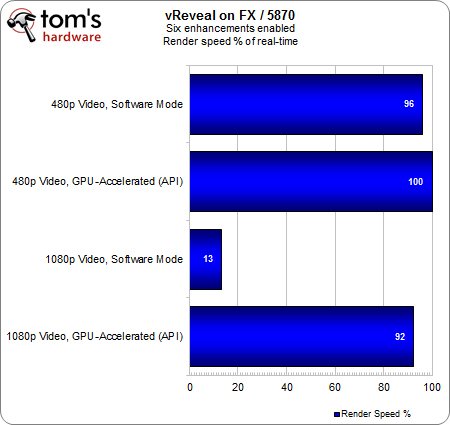
Bien que ce test monopolise presque 70 % des ressources de notre FX-8150, on constate que le rendu du clip 480p sans accélération GPU est presque intégralement effectué en temps réel. On ne peut pas en dire autant de la séquence 1080p puisque seulement 13% du rendu est géré en temps réel, c’est-à-dire qu’il fait à peu près 8 minutes de traitement pour 1 minute de vidéo.
L’accélération matérielle nous permet d’atteindre 92 % d’exécution en temps réel, soit 7 fois mieux que le processeur seul dans ce cas de figure exigeant au possible.
vReveal sur FX-8150 et Radeon HD 7970
Hormis la carte graphique, la plateforme de test reste identique. L’architecture GCN aura-t-elle des conséquences sur les résultats ?
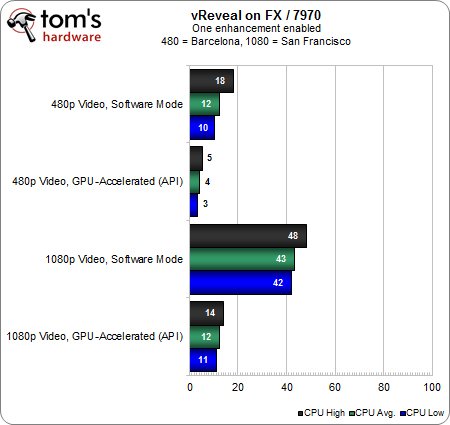
Avec un seul filtrage, lequel n’est pas vraiment gourmand en ressources, la différence avec la HD 5870 est négligeable. Même en 1080p, la HD 7970 permet de faire baisser le taux d’utilisation CPU à 12 % alors qu’il était de … 10 % avec la HD 5870. Ce constat est surprenant mais bien véridique : nos données témoignent d’un taux d’utilisation CPU légèrement plus important avec la plus récente des deux cartes.
Etant donné que la tendance s’inverse au fur et à mesure que l’on ajoute des filtrages supplémentaires, il est possible que les ressources en calcul de la HD 7970 ne soient pas employées avec autant d’efficacité lorsque la charge de travail est faible. Il faut donc une charge de travail plus conséquente afin que les 2048 shaders de la HD 7970 fassent parler leur potentiel. Le principal reste encore le taux d’utilisation à un chiffre avec le flux 480p accéléré, ainsi que les performances multipliées par 4 en 1080p lorsque l’accélération GPU est activée.
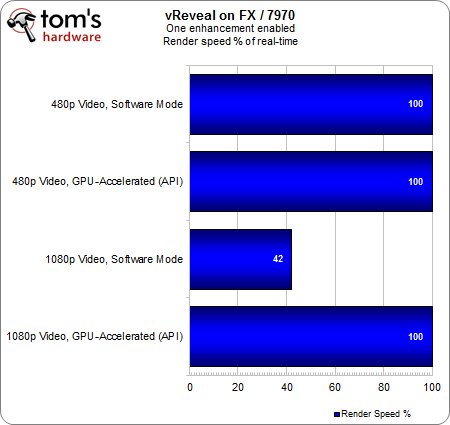
En toute logique, le rendu est tout aussi rapide avec la HD 7970 qu’avec la HD 5850 vu que la durée du traitement en temps réel plafonne à 100 % avec accélération matérielle. En parallèle, le changement de carte graphique ne doit pas avoir d’incidence sur le temps de traitement lorsque ce dernier est exclusivement logiciel.
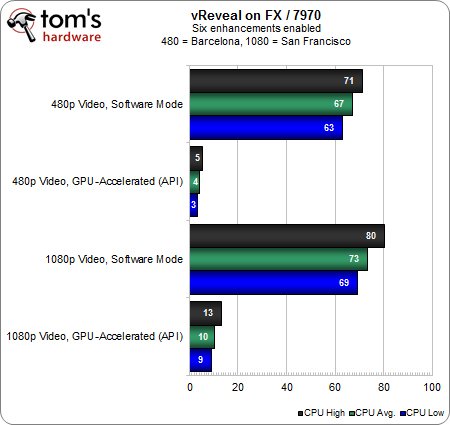
Encore une fois, le taux d’utilisation CPU montre que la Radeon HD 7970 n’apporte presque aucun bénéfice par rapport à la HD 5870 malgré les évolutions architecturales entre les deux cartes. Au-delà de l’éventuelle déception, il faut surtout en déduire que l’on ne peut pas systématiquement s’attendre à un échelonnement des performances en fonction des capacités de chaque GPU. Bien entendu, la situation varie d’un logiciel à l’autre et dans certains cas, la carte graphique la plus performante sera celle qui offre les meilleures performances.
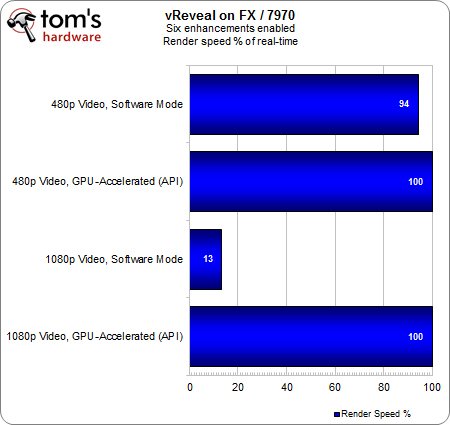
Exception faite de la toute petite différence en décodage logiciel avec la séquence 480p, les résultats sont les mêmes suivant que l’on utilise la Radeon HD 7970 ou la HD 5870.
vReveal sur A8-3850 & carte graphique
Nous nous rapprochons de la grande question : est-ce qu’un APU est capable de gérer des tâches exigeantes pour lesquelles on recommande généralement un FX ou Core i5/i7 ? Commençons par étudier le comportement de la partie CPU lorsque l’APU est épaulé par une carte graphique.
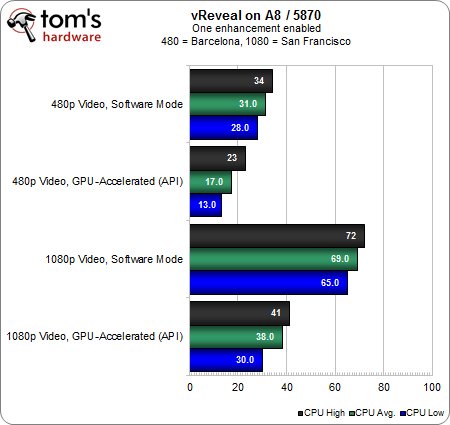
Dans ce contexte, les résultats en mode logiciel devraient être les plus parlants. On peut s’apercevoir que la séquence 480p sans accélération matérielle permet au FX-8150 d’afficher un taux d’utilisation 13 % inférieur à celui de l’A8, tandis que la séquence 1080p fait grimper cet écart à 22 %. L’A8 étant alors quasiment à 70 % d’utilisation, c’est le genre d’exercice que l’on hésiterait tout simplement à lancer dans un environnement multitâche quotidien.
D’autre part, on peut voir que l’A8 reste significativement sollicité quand bien même l’accélération GPU est activée : avec le flux 1080p, la plateforme FX-8150 et Radeon HD 5870 n’affichait que 10 % d’utilisation CPU, contre 38 % pour l’A8-3850 lorsque ce dernier est associé à la même carte graphique. On tient ici la preuve évidente que, malgré OpenCL et l’accélération matérielle, il faut un équilibre entre CPU et GPU pour obtenir les meilleurs résultats possibles. MotionDSP table encore clairement sur un processeur correct pour faire tourner son logiciel.
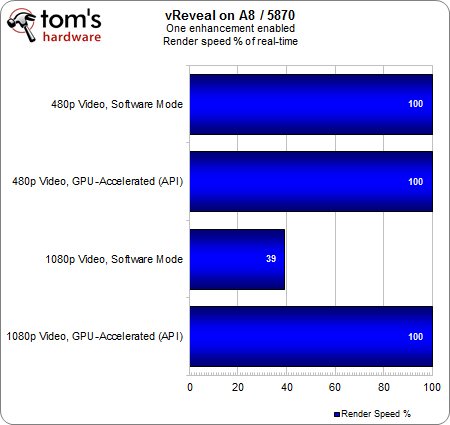
Avec un seul filtrage actif, le rendu est toujours effectué à 100 % en temps réel à l’exception de la séquence 1080p lorsque celle-ci est traitée en mode logiciel. Malgré une différence significative au niveau du taux d’utilisation, l’écart de performance entre nos deux processeurs n’est que de 6 %.
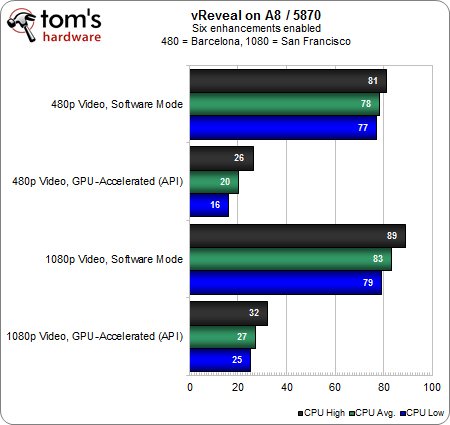
En mode logiciel avec 6 filtrages on voit à nouveau le FX un peu moins sollicité que l’A8, mais étant donné que fer de lance d’AMD est au moins à 67 % d’utilisation lorsqu’il traite la séquence 1080p, cette avance est négligeable.
Bien entendu, les résultats s’améliorent grandement une fois que l’on active l’accélération GPU, mais l’A8 continue d’afficher un taux d’utilisation deux fois plus important que celui du FX.
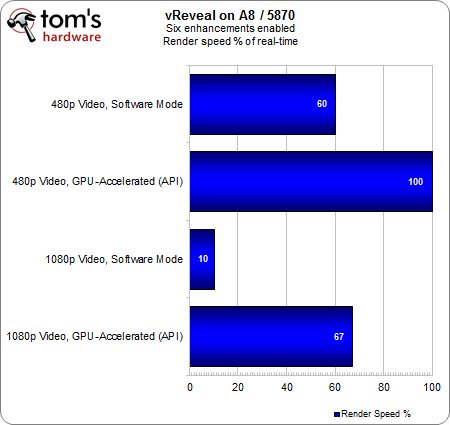
Cette tendance est confirmée par la proportion de rendu effectuée en temps réel : avec une HD 5870 dans les deux cas, l’A8 affiche un déficit de 25 % par rapport au FX en 1080p. Cet écart est particulièrement intéressant : le FX semblait souffrir quelque peu en termes de taux d’utilisation et pourtant, il apporte un gain de temps appréciable par rapport à l’A8 dans un contexte de charge intense.
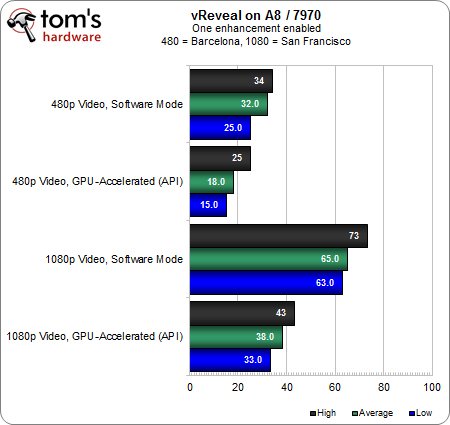
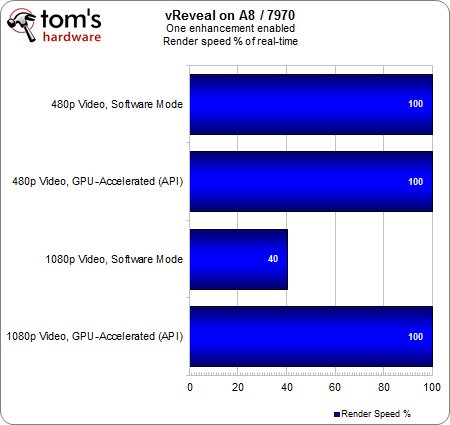
Pas de surprises ici, l’APU affiche un taux d’utilisation 15 à 20 % plus élevé que celui du FX.
Plus important encore, si le couple FX-8150 et Radeon HD 7970 affiche des performances 3,5 fois supérieures à celles du processeur seul en 1080p, le gain n’est que doublé avec l’A8-3850. Là encore on peut voir le déséquilibre entre une carte graphique franchement haut de gamme et un processeur qui n’arrive pas toujours à suivre. Dans un souci d’optimisation des performances, il faut donc monter en gamme côté CPU quand on a une carte graphique de ce niveau.
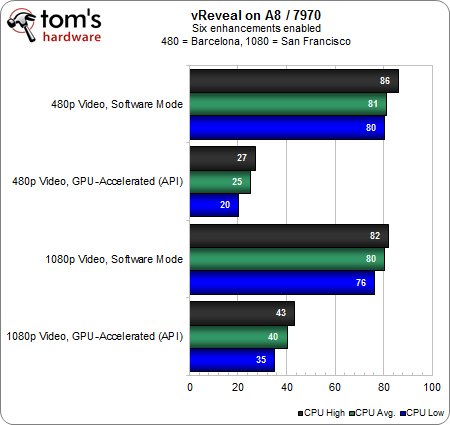
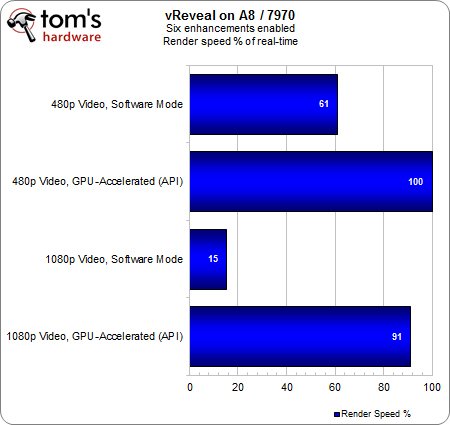
Le flux 1080p avec accélération GPU se traduit par 27 % d’utilisation sur l’A8 lorsque ce dernier est associé à la Radeon HD 5870. Ce taux grimpe à 40 % lorsque l’on passe à une HD 7970 et malgré cela, la proportion de rendu en temps réel progresse de 24 %. Qu’est-ce que cela signifie ?
La HD 7970 semble travailler plus dur que la HD 5870, ce qui augmente également la charge de travail de l’A8. Bien que la plus récente des deux Radeon fasse grimper le taux d’utilisation de l’A8, le résultat final est plus proche de l’idéal. Cette situation est illustrée par le fait que le rendu est presque intégralement gérable en temps réel, ce qui n’était pas le cas avec la HD 5870.
vReveal sur A8-3850 avec Radeon HD 6550D intégrée
L’intégralité des benchmarks avec cartes graphiques étant derrière nous, il est temps de voir comment l’APU s’en sort lorsque son circuit graphique intégré est mis à contribution.
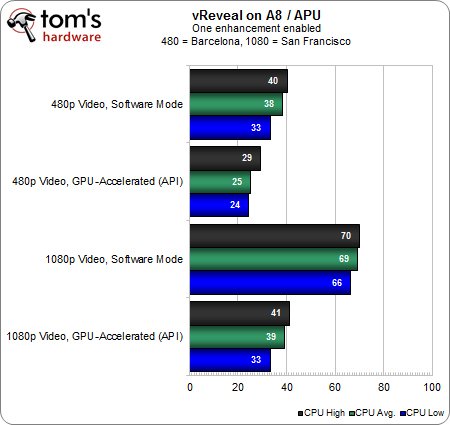
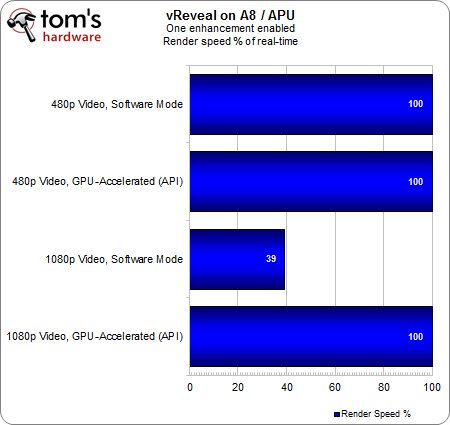
Dans le cas de l’accélération GPU activée, on peut voir que la présence d’une carte graphique permet d’un peu mieux soulager l’APU que son propre circuit graphique intégré en est capable en 480p.
Le plus intéressant est ailleurs : le taux d’utilisation CPU est presque identique lorsqu’une carte graphique/le circuit graphique intégré gère l’accélération matérielle en 1080p. L’explication est assez simple. Une charge modeste ne va pas faire souffrir la HD 6550D, ce qui permet à l’APU d’effectuer l’intégralité du rendu en temps réel. Etant donné qu’il n’est même pas nécessaire d’ajouter une carte graphique pour arriver à ce résultat, on en conclut donc que les APU peuvent offrir un excellent rapport performances/prix pour un tarif contenu.
Peut-on tirer les mêmes conclusions lorsque l’on passe d’un à 6 filtrages de rendu post-traitement en simultané ?
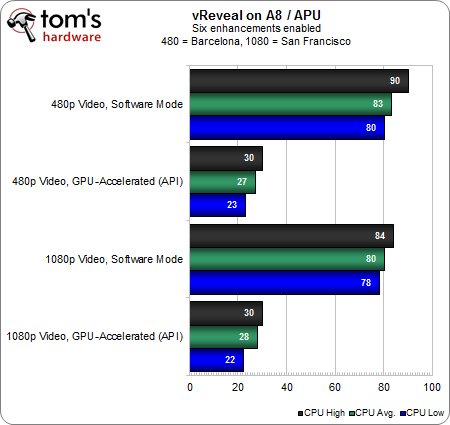
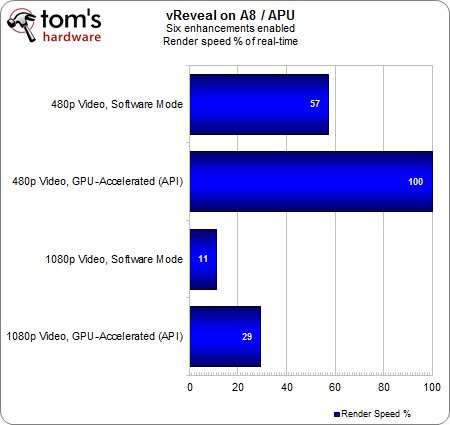
Pas tout à fait. Etant donné que la puissance graphique de l’APU est très nettement inférieure à celle que proposent les Radeon HD 5870/7970, le taux d’utilisation CPU reste à peu près constant quelle que soit la résolution vidéo. Notons tout de même que l’accélération vidéo permet de ramener le taux d’utilisation CPU à un niveau acceptable, environ 27 % en 480 comme en 1080p.
Le second graphique complète le tableau : l’accélération GPU permet donc non seulement de faire baisser la charge CPU, mais aussi d’assurer le rendu intégral de la séquence 480p en temps réel. En revanche, l’APU plafonne à 29 % lorsqu’on le met face à la séquence 1080p, soit à peine la moitié de ce dont le couple APU & HD 5870 est capable. Il est évident qu’une carte graphique dans toute sa complexité constitue le premier choix avec de pareilles charges.
vReveal sur plateforme mobile
Dans le cas des portables, il nous faut répondre à deux questions. Premièrement, est-ce que le circuit graphique intégré d’un processeur mobile basse consommation offre un réel gain de performance avec une charge portée sur le calcul ? Deuxièmement, que valent les APU mobiles d’AMD par rapport à leurs équivalents pour configurations fixes ?
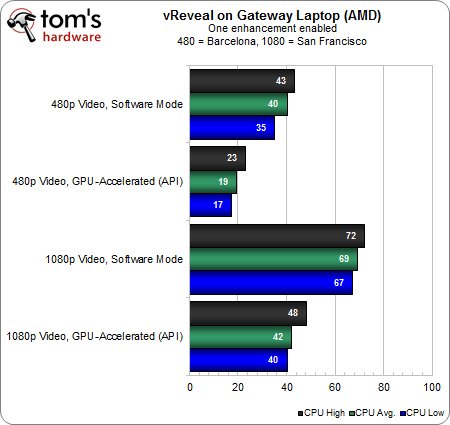
Commençons par comparer le portable Gateway équipé d’un A8-3500M à la configuration fixe munie d’un A8-3850. Sur le papier les deux APU sont assez proches (à l’exception de leur fréquence), ce qui est assez remarquable étant donné que le premier affiche un TDP de 35 Watts contre 100 Watts pour le second.
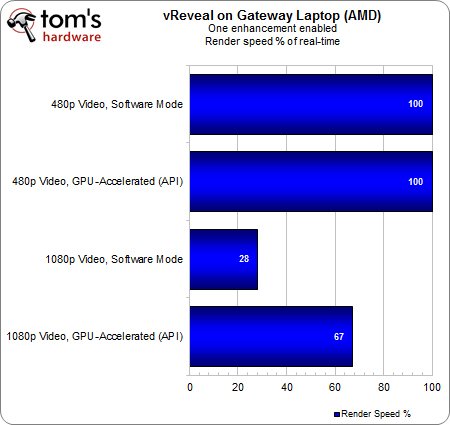
Le flux 480p ne pose aucun problème sur les deux plateformes, mais les fréquences CPU et contrôleur graphique inférieures sur l’APU mobile finissent par se faire sentir : en 1080p, la proportion d’images traitées en temps réelle baisse d’environ un tiers par rapport à l’A8-3850.
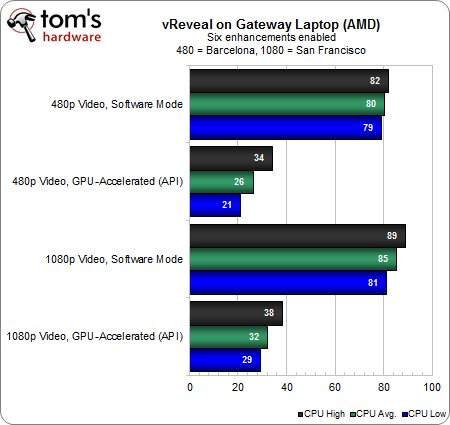
Avec 6 filtrages actifs en mode logiciel, le taux d’utilisation CPU grimpe à 80/85 % suivant la résolution du flux vidéo. Avec accélération GPU, l’A8 mobile affiche des résultats assez proches de ceux atteints avec l’A8-3850 (surtout en 480p), ce qui indique que la plateforme est à nouveau plafonnée compte tenu de la répartition CPU/GPU de la charge de travail.
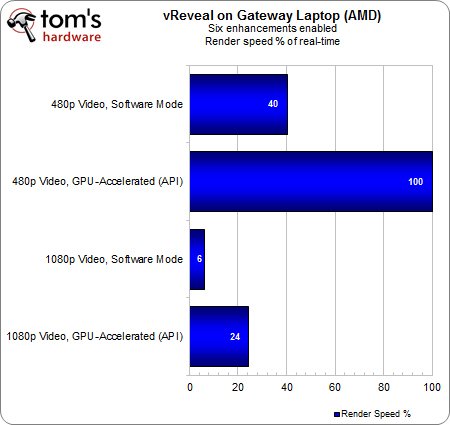
Malgré une charge conséquente, le notebook Gateway arrive tout de même à rendre l’intégralité de la séquence 480p en temps réel. Nous sommes également impressionnés du fait que l’APU mobile ne perde que 5% d’exécution en temps réel par rapport à l’A8-3850. Certes, la perspective de n’effectuer qu’un petit quart du rendu en temps réel semble assez médiocre par rapport aux 67 % du couple Radeon HD 5870 & A8-3850, mais il faut rappeler que l’on compare un APU mobile donné à 35 Watts de TDP à l’association d’un APU et d’une carte graphique dont les TDP respectifs sont de 100 et 188 Watts !
Enfin, voyons maintenant comment l’APU se situe face à un Core i5 Sandy Bridge avec Intel HD Graphics 3000. Bien entendu, tous les tests sont exécutés en mode logiciel : nous évaluons les performances sans accélération OpenCL.
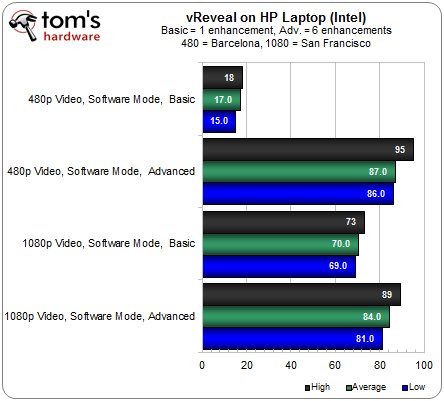
Lors du traitement de la séquence 1080p, l’APU était utilisé à 69 et 85 % suivant que l’on applique 1 ou 6 filtrages. Dans les mêmes conditions, le Core i5 affiche respectivement 70 et 84 % d’utilisation.
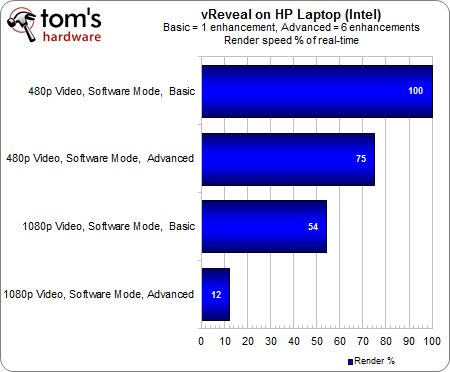
Malgré cela, le Core i5 parvient à des résultats corrects : le rendu en temps réel est possible pourvu que l’on se contente d’un seul filtrage et d’une résolution 480p. Avec 6 filtrages, 75 % du rendu est effectué en temps réel sachant que l’A8-3850 n’arrivait qu’à 40 % dans ce même test. Cependant, l’APU d’AMD devance son rival dès lors que l’on met ses 400 cores Radeon à contribution.
Ces résultats sont largement amplifiés en 1080p : si l’on compare les seules ressources CPU entre elles, Intel fait deux fois mieux qu’AMD. Mais une fois que l’on active l’accélération GPU, l’APU se rebiffe pour distancer significativement son concurrent.
Conclusion
Que peut-on tirer ce que l’on a vu aujourd’hui ?
- Lorsque le temps est crucial, rien de remplace les composants haut de gamme. Aucune des configurations testées n’a été en mesure d’approcher le couple FX-8150 & Radeon HD 7970. Avec des processeurs encore plus haut de gamme, les résultats des tests sans accélération GPU auraient très probablement été encore meilleurs. Quoi qu’il en soit, la notion d’équilibre entre les composants est absolument cruciale, notamment lorsque l’on s’apprête à renouveler sa configuration.
- Quand le budget se doit d’être contenu, l’association de ressources GPU et CPU sur une seule et même puce est susceptible d’offrir des gains de performances appréciables pourvu que les logiciels utilisés le permettent. Une carte graphique milieu de gamme fera certainement mieux du fait de son architecture plus complexe, mais l’APU permet de goûter aux joies de l’accélération GPU sans le surcoût constitué par une carte graphique. Ceci ne suffira pas à ceux qui parmi nous sont habitués aux cartes graphiques haut de gamme, mais il faut tout de même reconnaître qu’AMD a fait un réel progrès en termes de fonctionnalités intégrées : les précédents moteurs graphiques au niveau chipset ou processeur étaient nettement moins séduisants.
- Les avantages que procurent un APU mobile peuvent être proches voire équivalents à ceux d’un APU pour configuration fixe, là encore sous réserve de prendre les programmes adaptés pour cela. L’écart de TDP entre l’A8-3850 (100 Watts) et l’A8-3500M (35 Watts) n’est pas ce qu’il est sans raison, mais il faut aussi souligner l’équilibre pertinent entre puissance de traitement et ressources graphiques qui permettent d’aboutir à une meilleure expérience utilisateur sur portable.
Très franchement, les récentes évolutions d’AMD sont les plus prometteuses que la firme texane nous ait donné à voir depuis bien longtemps et elles méritent donc plus d’attention. Nous aurons l’occasion de voir d’ici quelques semaines si les APU permettent d’aboutir à des résultats similaires (ou encore meilleurs !) dans d’autres domaines…