Introduction
Les logiciels de traitement vidéo sont connus pour leur gourmandise : il suffit d’une ou deux pistes en 1080p et de quelques filtres pour occuper 100 % de la puissance de traitement de la plupart des ordinateurs.Peu de gens, cependant, sont conscients de la pression que peut mettre un logiciel de retouche photographique moderne sur un processeur.Ajouter un filtre sépia à une image de 8 mégapixels n’a rien de bien sorcier, mais il n’en va pas de même pour un flou complexe sur une image RAW de 18 mégapixels…
Même si une telle tâche ne met pas le processeur à genoux, elle prend toujours un temps considérable pour s’exécuter, surtout quand il s’agit de traiter un lot de plusieurs images.Malheureusement pour les professionnels, le temps d’attente, c’est du manque à gagner.Qui plus est, les pauses dans le flux de travail représentent aussi des perturbations dans le flux créatif : l’idéal est de pouvoir travailler au rythme de ses idées, sans devoir attendre qu’un traitement se termine pour pouvoir lancer le suivant.
Les professionnels veulent donc des ordinateurs plus puissants et qui accomplissent leurs tâches plus vite.Dans nos deux précédents articles, nous avons examiné la manière dont les GPU modernes, y compris ceux intégrés aux processeurs et aux APU, interagissaient avec les API les plus courantes en vue d’accélérer les opérations de traitement hautement parallèles dans les logiciels de traitement vidéo et dans les jeux.Aujourd’hui, nous allons nous pencher sur leur application dans le monde de la retouche photo.
Adobe, par exemple, a depuis longtemps adopté les technologies matérielles qui se prêtent le mieux à l’accélération de ses logiciels.La société fait ainsi appel à OpenGL pour accélérer (via le GPU) certaines fonctions de Photoshop depuis sa version CS4, et la liste de ces fonctions n’a fait que s’allonger à chaque nouvelle version.Aujourd’hui, avec Photoshop CS6, l’éditeur a décidé de ratisser plus large encore en ouvrant la porte à OpenCL.

Adobe n’est d’ailleurs pas la seule société à procéder de la sorte.Un petit utilitaire de traitement photo peu connu mais très intrigant, nommé Musemage, utilise également OpenGL et OpenCL pour bon nombre de ses filtres ; le célèbre logiciel de retouche photo open source GIMP fait de même ; et la prochaine version de Corel AfterShot Pro, sur laquelle nous avons pu mettre la main avant tout le monde, prendra en charge OpenCL.
Pour cet article, nous allons tester chacune de ces applications sur cinq configurations différentes afin de tenter d’y déceler des tendances. Nous allons essayer de voir dans quelle mesure l’accélération par GPU influe sur la rapidité des tâches de traitement photo, de déterminer quels sont les écarts de performances des APU et celles des GPU, et de découvrir si l’accélération est proportionnelle à la puissance du moteur graphique.
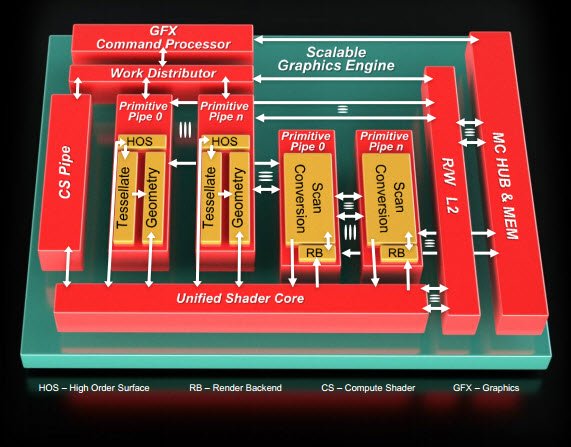
Q/R avec AMD
L’un des objectifs de cette série sur le calcul hétérogène est de mieux faire comprendre certaines des décisions prises par les acteurs liés à l’OpenCL et à DirectCompute.Pourquoi tel ou tel éditeur choisit-il de faire appel à ces deux API plutôt qu’à d’autres, comme OpenGL ou DirectX ?Que font réellement ces deux interfaces dans les coulisses ?Quelles sont leurs limites et quelle part de leur potentiel reste encore inexploité ?
Ces questions ne trouvent pas leurs réponses dans les documents marketing.Heureusement, nous avons eu la possibilité de rencontrer deux autorités en la matière.La première est Alex Lyashevsky, ingénieur performances chez AMD et membre éminent du personnel technique ayant rejoint AMD suite à l’acquisition d’ATI en 2006.Alex Lyashevsky n’a rien d’un baratineur du département marketing : il est détenteur de brevets sur la parallélisation de la compression sans perte des images et sur le premier décodeur H.264 via GPU au monde.Peu de gens comprennent le calcul GPGPU aussi bien que lui et moins encore sont en mesure de faire le rapprochement entre celui-ci et l’accélération via OpenCL.

Tom’s Hardware :Photoshop CS6 est notre principale application de benchmarking pour cet article ; cela fait longtemps que le logiciel utilise OpenGL, mais pourquoi bénéficions-nous maintenant de l’accélération OpenCL ?
Alex Lyashevsky :OpenGL est assez populaire et a en effet bon nombre de capacités en commun avec OpenCL, mais il est plus tourné vers les graphismes.Lorsqu’on utilise OpenGL, on part généralement du principe qu’il y a une image ou un tampon sur lequel on essaie de dessiner.OpenCL est une plateforme de programmation beaucoup plus généraliste qui vous laisse totalement libre de définir votre propre domaine de calcul, au lieu de vous cantonner à un élément bidimensionnel composé de pixels.Mis à part cela, très franchement, il m’arrive parfois d’encourager les gens à utiliser OpenGL, car cette API gère très bien l’accélération matérielle du filtrage de tampon d’entrée, par exemple, ou la composition du tampon de couleur en sortie.
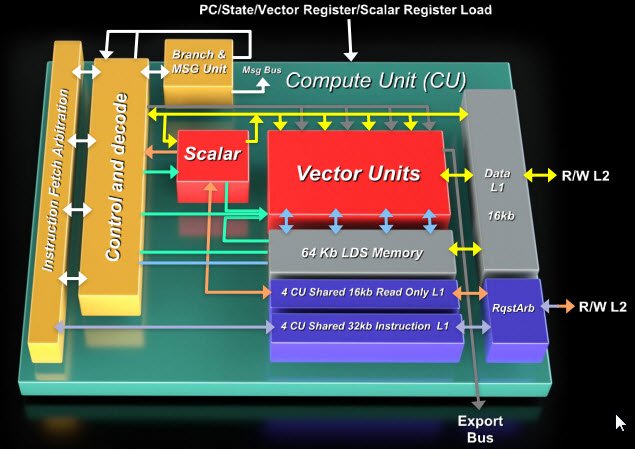
Tom’s Hardware :Pour les développeurs, en termes de codage, est-ce qu’il existe une grande différence entre les deux API ?
Alex Lyashevsky :Le langage des shaders d’OpenGL peut s’avérer difficile à maîtriser.OpenCL est sans doute un peu plus facile pour les développeurs.OpenGL suppose que vous travaillez dans un contexte graphique, ce qui signifie qu’il faut définir le point de vue, les transformations de matrices et de modèles, etc.C’est un langage graphique, ce qui fonctionne bien pour certains types d’opérations, lorsqu’il s’agit de faire des calculs portant sur des graphismes, mais c’est un non-sens pour les développeurs généralistes.Si vous voulez faire de la manipulation de données, à quoi bon définir un triangle, un point de vue ou un matrice ?C’est là qu’intervient OpenCL, qui permet de faire du calcul plus générique sur GPU.Par exemple, il n’est probablement pas très utile d’utiliser OpenGL pour accélérer quelque chose comme le deflate ou le chiffrement dans les logiciels de compression ; par contre, il est souvent utile pour les logiciels de traitement d’image.
Q/R avec AMD (suite)
Tom’s Hardware :Est-ce que la communauté des développeurs se montre enthousiaste ?Est-ce qu’ils viennent à votre rencontre en vous demandant de les aider à se lancer dans OpenCL ?
Alex Lyashevsky :En tout cas, il n’y a pas de résistances.Très franchement, OpenCL n’est pas très facile, mais j’essaye de faire tomber les barrières psychologiques.Souvent, les développeurs se lancent dans OpenCL mais, parce qu’il s’agit d’un langage assez lourd, ils n’obtiennent pas les performances que leur promettent les documents marketing, et ils pensent donc qu’il ne fonctionne pas correctement.Ils croient qu’il s’agit d’un artifice marketing et arrêtent de l’utiliser.Mon objectif est de briser les barrières et de leur montrer que ce langage a de nombreux avantages.La manière d’obtenir ces avantages, par contre, c’est une autre histoire.Le problème de l’OpenCL est que, bien que ce ne soit pas bien différent du C, ce n’est pas non plus tout à fait pareil. Tout réside dans la façon de réfléchir.Il faut avant tout comprendre que l’on tente de résoudre des problèmes extrêmement parallélisés.Le problème est donc plus de se mettre en tête comment exécuter en parallèle 32 ou 64 tâches synchrones ; c’est la principale pierre d’achoppement et la principale raison pour laquelle on ne trouve pour l’instant pas plus de développeurs qui travaillent en OpenCL.
Après, il y a effectivement des problèmes d’architecture.Il faut tenir compte système dans son ensemble, car il est nécessaire de déplacer les données depuis la pile « processeur » vers la pile « vidéo » pour obtenir les meilleurs performances.Ce déplacement pose problème et engendre des résistances chez les développeurs, et il diminue les performances, car il faut faire transiter les données.Il est donc important de le faire de manière efficace.Mais nous sommes là pour expliquer aux développeurs comment faire sans trop diminuer les rendements.À l’avenir, l’architecture HSA (NDLR : Heterogeneous Systems Architecture, le nouveau nom de l’architecture Fusion) comprendra une mémoire pleinement unifiée, et c’est d’ailleurs déjà le cas au niveau physique sur nos APU, mais pas encore sur nos cartes graphiques.Pour tirer les meilleures performances de nos produits, il faut donc utiliser une mémoire ou un bus dédié.Les développeurs ont tendance à oublier ce détail lorsqu’il commencent à coder en OpenCL.Ils pensent qu’ils ne peuvent pas, voire ne devraient pas, faire la différence entre les architectures CPU et GPU.Malheureusement (ou heureusement… c’est difficile à dire), si OpenCL fonctionne aussi bien sur CPU que sur GPU, il n’y a aucune garantie que les performances seront identiques.Il faut donc bien savoir si l’on code pour un GPU ou un CPU pour exploiter pleinement le potentiel d’OpenCL.

Tom’s Hardware :Pourriez-vous nous résumer votre mission ?Quel est le message que vous voulez absolument faire passer aux développeurs ?
Alex Lyashevsky :Premièrement, il faut bien comprendre qu’il faut déplacer les données.Deuxièmement, comprendre que le code doit fortement paralléliser les données.Et troisièmement, ce qui est presque la même chose que le deuxièmement, il faut comprendre que l’optimisation des performances vient de la parallélisation.Il faut bien avoir conscience de l’architecture pour laquelle on code.C’est sur ces points que porte l’aide que nous apportons aux développeurs, et notre travail commence à porter ses fruits.D’après nos enquêtes, OpenCL est en train de gagner énormément en popularité.
Tom’s Hardware :Parlons maintenant des APU dans le contexte de l’informatique mobile et de la gestion de la consommation.Est-ce que les règles des algorithmes de gestion de l’énergie ont changé ?Est-ce qu’un APU fonctionne différemment selon qu’il est branché sur secteur ou qu’il fonctionne sur batterie ?
Alex Lyashevsky :Pour la partie CPU, malheureusement, les choses restent inchangées.La mémoire et le système de gestion de l’énergie sont quant à eux très sophistiqués ; parfois, tout dépend de la catégorie dans laquelle on a placé l’APU (NDLR : normal, mobile, basse tension, ultra-basse tension, etc.) ; c’est le facteur le plus déterminant dans la gestion de l’activité.Par contre, notre GPU est très flexible, au point qu’il arrive que son activité affecte notre gestion des performances.Tant que le matériel ne reçoit pas de charge de travail suffisante, il essaye de consommer le moins possible.Il ralentit automatiquement quand il n’a pas assez de travail.Donc oui, il est très flexible ; je n’irais pas jusqu’à dire qu’il est absolument parfait, mais nous essayons de le rendre aussi efficace que possible.
Configurations de test
Comme dans nos précédents articles sur le sujet, nous avons utilisé les configurations suivantes :
| Conifgurations de test | |
|---|---|
| Configuration 1 | |
| Processeur | AMD FX-8150 (Zambezi) 3,6 GHz, socket AM3+, 8 Mo de cache L3 partagé, Turbo Core activé, 125 watts |
| Carte-mère | Asus Crosshair V Formula (socket AM3+), AMD 990FX/SB950 |
| Mémoire | 8 Go (2 x 4 Go) de mémoire AMD Performance Memory AE34G1609U2 (1600 MT/s, 8-9-8-24) |
| SSD | Patriot Wildfire 240 Go SATA 6 Gbit/s |
| Cartes graphiques | AMD Radeon HD 7970 3 Go |
| AMD Radeon HD 5870 1 Go | |
| Alimentation | PC Power & Cooling Turbo-Cool 860 watts |
| OS | Windows 7 Professionnel 64 bits |
| Configuration 2 | |
| Processeur | AMD A8-3850 (Llano) 2,9 GHz, socket FM1, 4 Mo de cache L2, 100 watts, moteur graphique Radeon HD 6550D |
| Carte-mère | Gigabyte A75-UD4H (socket FM1), AMD A75 FCH |
| Mémoire | 8 Go (2 x 4 Go) de mémoire AMD Performance Memory AE34G1609U2 (1600 MT/s, 8-9-8-24) |
| SSD | Patriot Wildfire 240 Go SATA 6 Gbit/s |
| Cartes graphiques | AMD Radeon HD 7970 3 Go |
| AMD Radeon HD 5870 1 Go | |
| Alimentation | PC Power & Cooling Turbo-Cool 860 watts |
| OS | Windows 7 Professionnel 64 bits |
| Configuration 3 : Gateway NV55S05u | |
| Processeur | AMD A8-3500M (Llano) 1,5 GHz, socket FM1, 4 Mo de cache L2, 35 watts, moteur graphique Radeon HD 6620G |
| Carte-mère | Gateway SJV50-SB |
| Mémoire | 1 x 2 Go de mémoire Hyundai HMT325S6BFR8C-H9 PC3-10700 (667 MHz), 1 x 4 Go de mémoire Elpida EBJ41UF8BCS0-DJ-F PC3-10700 (667 MHz) |
| SSD | Western Digital Scorpio Blue 640 Go, 5400 tr/min, 8 Mo de cache, SATA 3 Gbit/s |
| Carte graphique | Moteur graphique intégré AMD Radeon HD 6220G |
| OS | Windows 7 Édition Familiale Premium 64 bits |
| Configuration 4 : HP Pavillion dv6 | |
| Processeur | Intel Core i5-2410M (Sandy Bridge) 2,3 GHz, socket G2, 3 Mo de cache L3, Turbo 35 watts, moteur graphique Intel HD Graphics 3000 |
| Carte-mère | Hewlett-Packard 1658 |
| Mémoire | 4 Go (2 x 2 Go) de mémoire Samsung M471B5773CHS-CH9 PC PC3-10700 (667 MHz) |
| SSD | Seagate Momentus 7200.4, 500 Go, 7200 tr/min, 16 Mo de cache, SATA 3 Gbit/s |
| Carte graphique | Moteur graphique intégré Intel HD Graphics 3000 |
| OS | Windows 7 Professionnel 64 bits |
Avec un peu de chance, nous aurons prochainement l’occasion d’ajouter un portable à base de Trinity (la prochaine génération d’APU made in AMD) à notre line-up, mais ce n’est malheureusement pas encore pour cette fois-ci, le matériel n’étant pas encore disponible.
Les applications : GIMP, AfterShot Pro et Musemage
Pour cet article, nous avons réalisé nos tests à l’aide de quatre applications : GIMP, Corel AfterShot Pro, Musemage et Adobe Photoshop CS6.
GIMP
GIMP (GNU Image Manipulation Program) est un logiciel open source lancé en 1995 et est probablement le programme de retouche photo le plus populaire pour tous ceux qui ne sont pas prêts à délier les cordons de leur bourse.Bardé de fonctions avancées, il a été porté sur de nombreux systèmes d’exploitation, de Windows à OS X en passant par Linux, FreeBSD et même AmigaOS 4.Nous avons utilisé la version 2.8 pour Windows (build du 2 avril 2012), qui prend en charge l’accélération OpenCL pour 19 filtres.Nous avons accédé à trois d’entre eux (flou gaussien, bilatéral et de mouvement) via le menu GEGL (Generic Graphics Library) qui a fait son apparition dans la version 2.6 et qu’AMD nous décrit comme suit :
« GEGL est un pipeline de calcul en virgule flottante qui va servir de fondation à la prochaine version majeure de GIMP.GEGL nécessite plus de puissance de traitement que le vieux pipeline de GIMP, qui fonctionne en 8 bits, mais offre nettement plus de possibilités.Étant donné qu’en ce qui concerne GIMP, l’avenir passe par GEGL, nous avons concentré nos efforts sur l’accélération de ce dernier plutôt que sur celle du vieux pipeline.Par conséquent, seules les opérations GEGL vont bénéficier de l’accélération OpenCL.GEGL est intégré progressivement à GIMP, raison pour laquelle ses opérations se trouvent dans des menus séparés ; cela va rester comme cela jusqu’à ce que GEGL soit pleinement intégré à GIMP ; à ce moment là, il n’y aura plus de menus séparés, vu que tout passera par GEGL. »
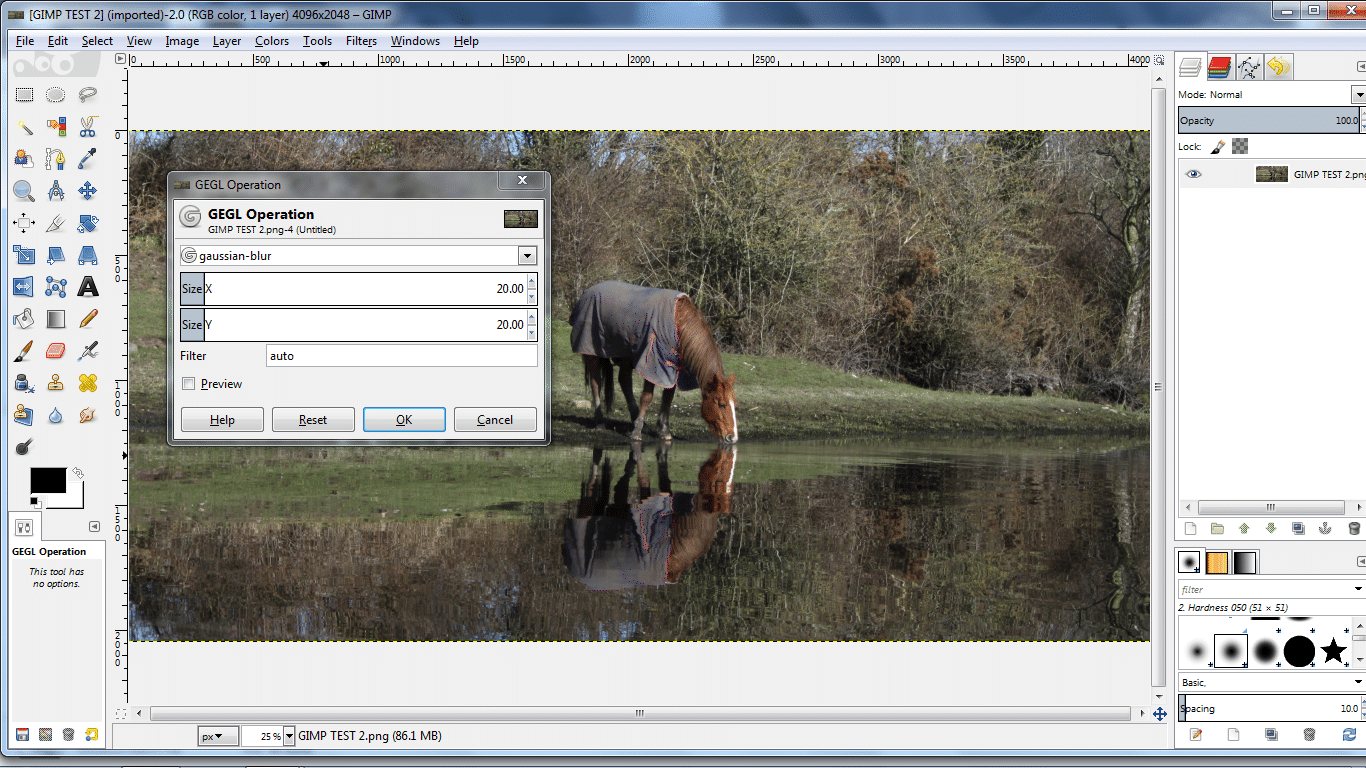
Nous avons obtenu des informations intéressantes en discutant avec Victor Oliveira, développeur pour GIMP/GEGL.OpenGL est spécifiquement conçu pour le traitement graphique ; nous avions longtemps pensé qu’il en allait de même pour OpenCL et que ce dernier était simplement prévu pour traiter des tâches graphiques légèrement différentes.Il apparaît toutefois que cette API est nettement plus robuste et flexible que ce que croient la plupart des gens.
« OpenCL ne permet pas seulement de faire de l’accélération par GPU : on peut également l’utiliser avec le CPU pour optimiser le multithreading (qui n’était pas terrible dans GIMP) et pour gérer la vectorisation.Notez que GIMP s’adresse à un public très varié ; si, par exemple, nous voulions prendre en charge le jeu d’instructions AVX dans notre code, nous devrions créer deux builds ou effectuer une détection au lancement, car la nouvelle version ne fonctionnerait pas sur les anciennes machines.Dans les deux cas, ce n’est pas une bonne solution.Avec OpenCL, nous nous en sortons avec une seule build, ce qui rend la technologie très intéressante. »
Notre build de GIMP dispose de paramètres en ligne de commande lui permettant de fonctionner avec ou sans la prise en charge d’OpenCL et nous offre la possibilité d’afficher une fenêtre de débogage indiquant les résultats du benchmark.Comme fichier de test, nous avons utilisé une image bitmap de 30 Mo et d’une résolution de 4096 x 2048 pixels.
Corel AfterShot Pro
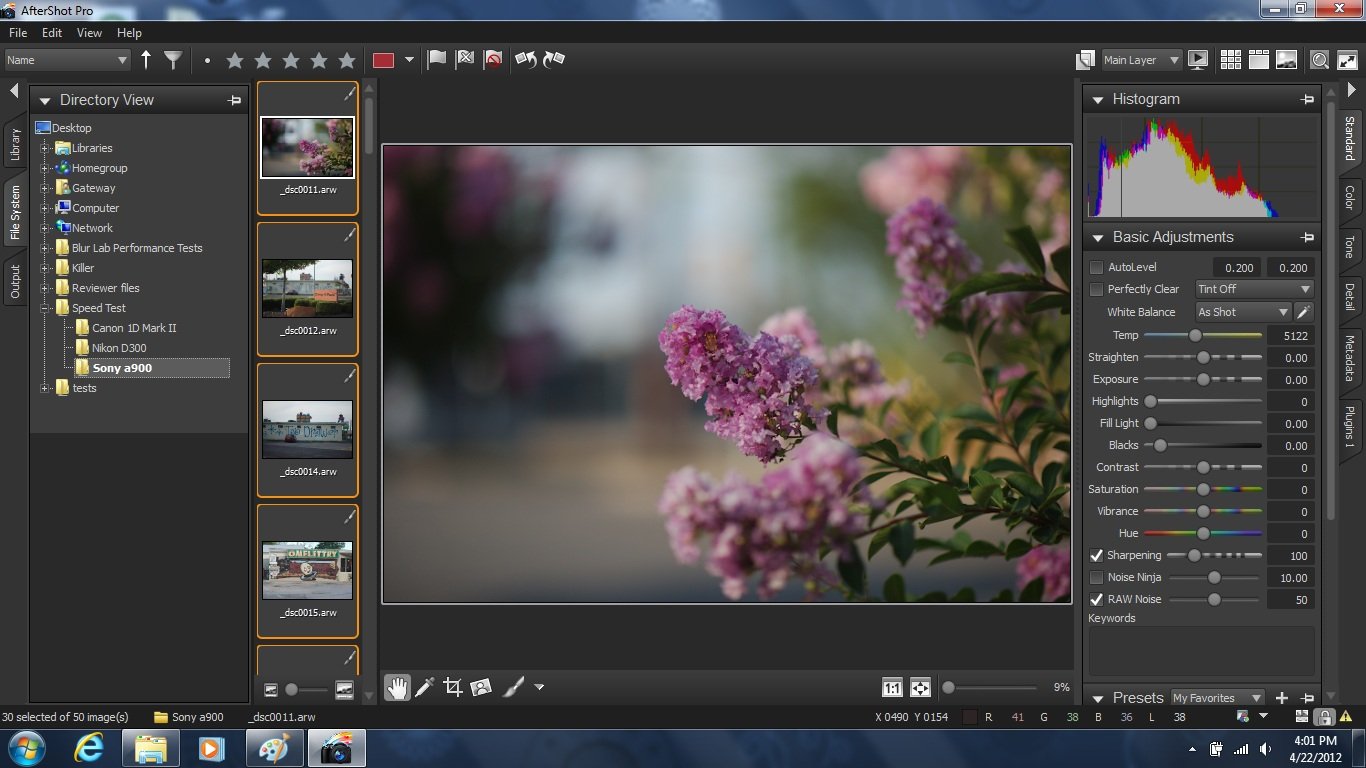
Corel AfterShot Pro est un logiciel de traitement photo non destructif.D’un point de vue technique, cela signifie qu’à chaque fois qu’il ouvre, modifie ou génère une image, il réapplique l’ensemble des traitements appliqués depuis le tout début, du décodage au rendu final, sans éliminer aucune donnée.Les modifications sont donc superposées et peuvent être altérés à tout moment.Bien entendu, si l’utilisateur décide de fusionner les modifications, l’aspect non destructif du flux de travail disparaît.
Corel a eu la gentillesse de nous fournir une préversion spéciale d’ASP qui utilise OpenCL pour accélérer la conversion de fichiers.Nous avons donc réuni 50 images RAW de 6048 x 4032 et environ 37 Mo chacune, puis avons utilisé ASP pour les convertir (par lot) en JPEG, avec et sans l’aide d’OpenCL.
Musemage
Musemage est un logiciel de retouche photo récent qui gagnerait à être plus connu.D’après ce que nous a confié AMD, cette application a été développée par des ingénieurs chinois, ce qui expliquerait sa quasi-absence sur le marché occidental. Il s’agit pourtant d’une véritable merveille d’utilité et de convivialité, en particulier pour le traitement par lot.Son manque de popularité est d’autant plus regrettable que, contrairement à la plupart des logiciels de retouche photo, sur lesquels l’accélération matérielle n’a été greffée qu’après coup, Musemage a été conçu dès le départ pour en tirer parti.
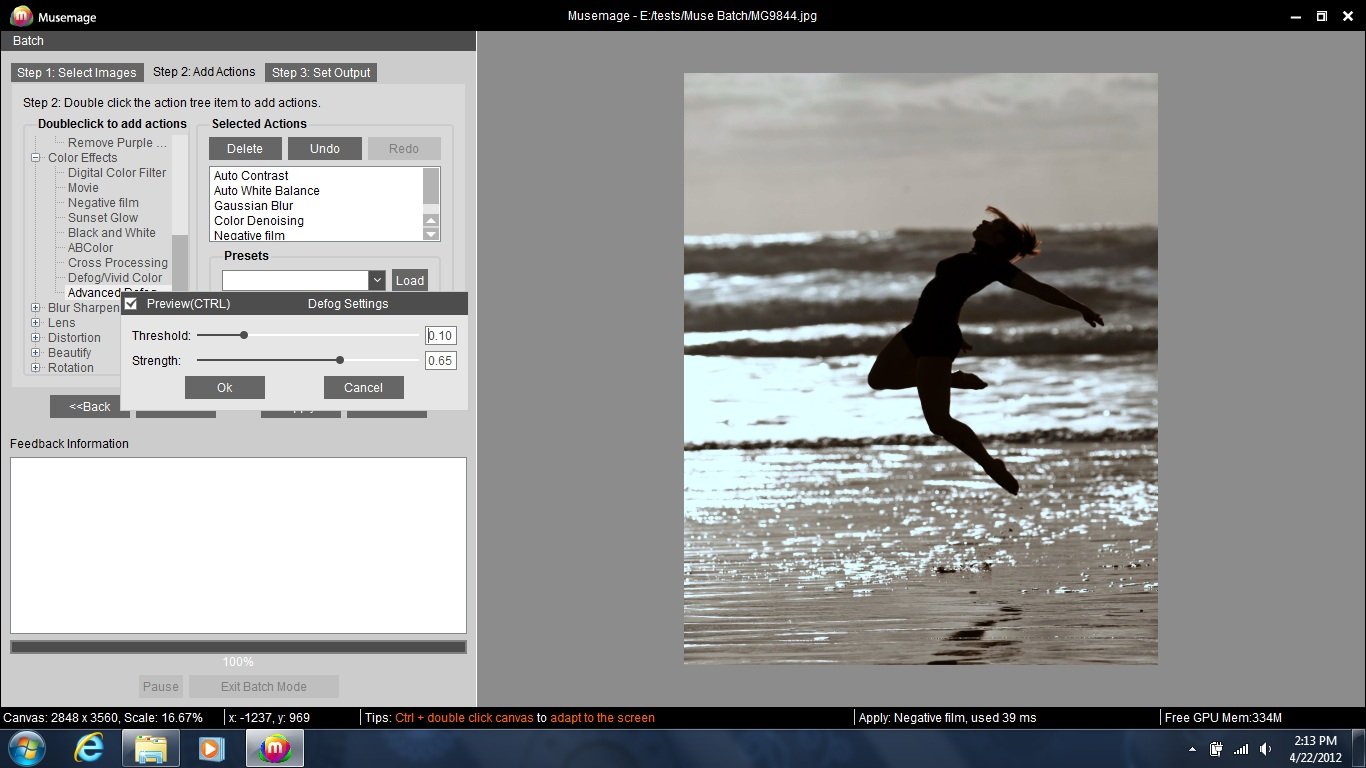
Pour notre test sous Musemage, nous avons utilisé huit images JPEG tirées de JLucasPhoto.com, faisant chacune entre 10 et 12 mégapixels et pesant au total 35,4 Mo.Musemage permet d’appliquer des dizaines de modifications : filtres de couleur, lentilles, distorsions, redimensionnement, etc.Lors du test, nous avons appliqué 11 traitements à chaque image : contraste auto, balance des blancs auto, flou gaussien (4,0 pixels), réduction du bruit en couleur (0,8 pixel), négatif (zones claires 50, zones sombres 50), defog avancé (seuil 0,10, force 0,65), vignettes (angle 45°), adoucir les tons chair (rayon 3,3 pixels, force 0,05, blanchiment 0,02), retourner horizontalement, redimensionnement (150 % avec respect des proportions) et ajout de texte (opacité 40 %).
Les applications : Adobe Photoshop CS6
L’une des définitions les plus courantes du calcul hétérogène prend en compte l’intégration d’un moteur graphique (GPU) sur le même die qu’un processeur classique (CPU).Adobe voit les choses sous un angle un peu différent, plus systémique : l’éditeur examine les différentes manières dont ses logiciels peuvent exploiter les ressources de calcul disponibles puis détermine quelles parties du système fournissent le mieux ces ressources.Pour Adobe, le calcul hétérogène consiste à définir « plusieurs jeux d’instructions et types de codes sur le même ordinateur, puis à utiliser toutes ces ressources pour proposer à l’utilisateur une meilleure expérience ».
Photoshop CS6 illustre à merveille cette philosophie.Pionnier du multithreading, le célèbre logiciel de retouche photo peut aujourd’hui se targuer de prendre en charge OpenCL. L’objectif ? Accélérer toujours plus de fonctions et faire en sorte que l’utilisateur doive passer le moins de temps possible à attendre.Idéalement, les filtres devraient pouvoir être appliqués en temps réel et l’ordinateur devrait pouvoir gérer aisément une image de 30 mégapixels avec 30 calques.L’approche traditionnelle fait la part belle aux capacités du CPU, mais comme les dernières puces d’AMD et d’Intel nous l’ont récemment montré, il ne faut plus trop s’attendre à des bons spectaculaires en ce qui concerne les performances de ce composant.À l’heure actuelle, le progrès vient avant tout de l’intégration de différents sous-systèmes (dont le GPU), de l’accélération des bus, du parallélisme, etc.
Dans la mesure où chaque logiciel, chaque fonction et chaque tâche à exécuter profite différemment des optimisations apportées au matériel, il est impossible d’aborder l’accélération matérielle par GPU de manière complète sans examiner la manière dont ces accélérations sont obtenues.Photoshop CS6 apporte la prise en charge de l’OpenCL pour les outils de la galerie Flous.En parallèle, le logiciel continue à faire appel à OpenGL pour accélérer d’autres fonctions : Liquify, grand angle adaptif, transformations, warp, puppet warp, effets d’éclairage ainsi que la grande majorité des fonctions 3D (ombres, vanishing point, sketch rendering, etc.) à l’exception du ray tracer.OpenGL accélère également le filtre « peinture à l’huile » et le multithreading de certaines nouvelles fonctions comme l’enregistrement en arrière-plan (extrêmement utile dans les gros travaux).
Bien qu’Adobe soit une grande entreprise et que Photoshop soit l’une de ses applications les plus renommées, le nombre de personnes travaillant sur celle-ci est étonnamment faible : moins de 60 développeurs et ingénieurs qualité.Lors de nos entretiens, Adobe nous a confié que « Mettre plus de têtes sur un problème, ça ne fait pas toujours un meilleur logiciel ».Il est par contre remarquable de constater que, malgré cette équipe restreinte, l’éditeur est parvenu à réduire la durée de son cycle de révision, qui est passé de 18-24 mois anciennement à 12 aujourd’hui. Il faut juste garder à l’esprit le fait que cette diminution entraîne en pratique un ralentissement apparent de l’adoption des nouvelles technologies d’une version à l’autre.
Adobe nous a fourni deux scripts pour tester les performances de son logiciel sous OpenCL et OpenGL.Dans le premier cas, le choix a été inévitable : la galerie de flous, étant donné qu’il s’agit de la seule série de filtres Photoshop accélérés par OpenCL.Nous avons exécuté quatre itérations du flou général sur un fichier PSD de 5615 x 3744 pixels et de 60,2 Mo : en RVB et en CMJN, et avec une valeur de flou de 25 ou de 300.Le script a appliqué l’effet sept fois et écrit les résultats dans un fichier CSV dont nous avons extrait le temps moyen nécessaire pour exécuter l’opération.
Côté OpenGL, Adobe nous a fourni un script très similaire pour le filtre Liquify, qui n’est assorti d’aucun paramètre.
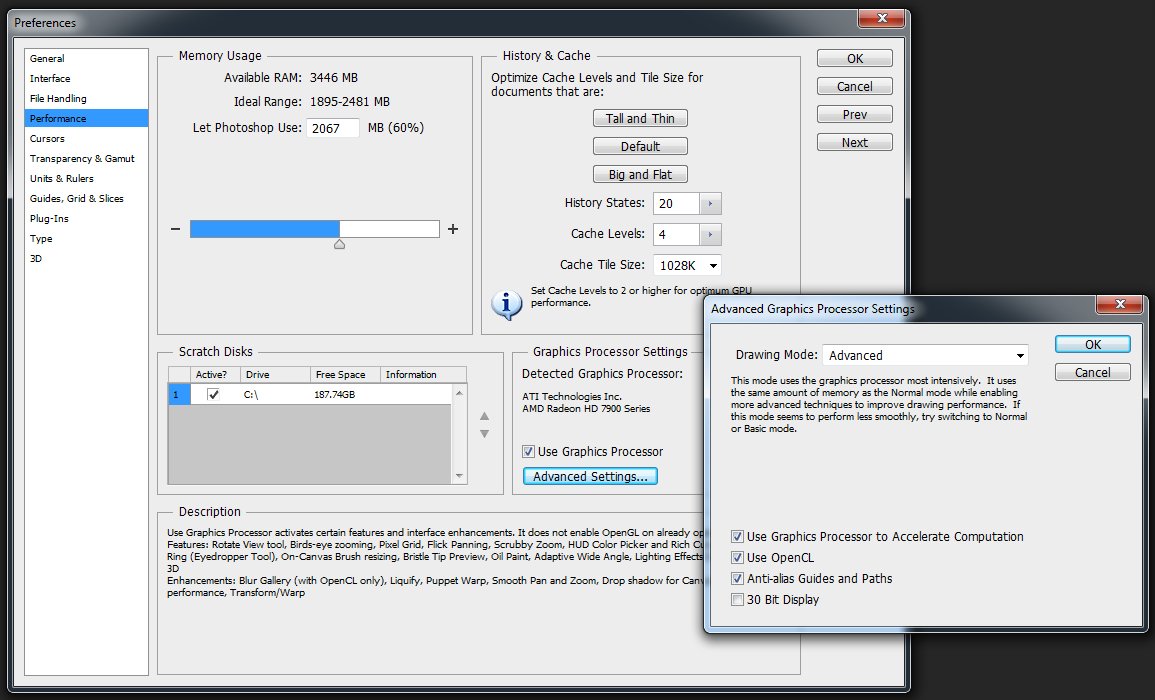
Notez que nous avons réglé l’accélération GPU à l’aide du menu Préférences > Performances > Paramètres du processeur graphique de Photoshop.Dans cette fenêtre, décocher la case « Utiliser le processeur graphique » désactive toute accélération OpenGL et OpenCL, ce qui représente la seule manière d’obtenir des résultats sans accélération fiables.En effet, le bouton « Paramètres avancés », qui ouvre une fenêtre permettant théoriquement de désactiver OpenGL (« Utiliser le processeur graphique pour accélérer le traitement », on a vu plus intuitif comme intitulé) et OpenCL, laisse tout de même OpenGL activé…
Q/R avec Adobe
Dans le monde de la retouche photo, aucun éditeur ne possède la même aura ni autant d’expérience qu’Adobe. Il nous a donc semblé important d’aborder OpenCL avec quelqu’un qui savait réellement comment Photoshop avait été conçu et avait évolué au fur et à mesure de ses versions.Nous avons donc obtenu un entretien avec Russell Williams, principal scientifique et architecte de l’équipe Photoshop chez Adobe.Si vous faites bien attention, vous verrez d’ailleurs que son nom apparaît en troisième position sur l’écran d’accueil de Photoshop CS6.Son travail consiste à gérer la direction technique du logiciel et à prendre les décisions concernant les technologies à utiliser, dans quelle mesure, et comment y parvenir.
Tom’s Hardware :De la prise en charge du dual-threading à celle d’OpenGL, Photoshop a toujours été un pionnier en matière d’adoption de techniques d’accélération.Mais on ne peut pas tout adopter ; comment décidez-vous quel chemin vous allez prendre ?
Russell Williams :Nous n’avons pas vraiment de processus de décision spécifique.Il faut savoir que nous avons des ressources limitées, un temps limité, une équipe d’une certaine taille…À chaque fois que nous décidons de ce qui va être intégré à la prochaine version, les performances sont l’un des éléments sur lesquels il faut faire des compromis.Comme pour toute nouvelle fonctionnalité, nous essayons de déterminer quel va être notre retour sur investissement.Par exemple, réduire le temps de démarrage de l’application n’a pas grand-chose de sexy, mais cela affecte tous les utilisateurs et cela a une incidence énorme sur la manière dont les gens perçoivent la rapidité de Photoshop.Et sur la productivité des utilisateurs.
Tom’s Hardware :Avec CS6, nous voyons apparaître dans Photoshop les premiers éléments d’OpenCL.En termes de développement, combien de temps a-t-il fallu pour intégrer la prise en charge de cette API ?Est-ce qu’OpenCL n’aurait pas déjà pu être ajouté dès la CS5.5 ?
Russell Williams :En règle, générale, nous n’implémentons pas de nouvelles fonctions majeures dans les versions intermédiaires (telles que CS5.5).Il faut donc retourner à la CS5, qui a été publiée au printemps 2010, mais que nous avons conçue à partir de fin 2008.À l’époque, OpenCL n’était pas encore assez mûr ; qui plus est, les pilotes multi-plateformes n’ont pas été disponibles avant fin 2009, époque à laquelle nous étions déjà en phase de test.CS6 a donc réellement été notre première opportunité de prendre en charge cette interface.
Tom’s Hardware :Vous aviez d’autres choix d’API pour gérer l’accélération des fonctions.Pourquoi avoir choisi OpenCL ?
Russell Williams :Premièrement, parce qu’il s’agit d’une norme ouverte, contrairement aux autres technologie de calcul sur GPU telles que CUDA ou DirectCompute.C’est important parce que cela signifie qu’OpenCL fonctionne sur toute les plateformes.Avec les ordinateurs de bureau, en particulier sous Windows, vous avez généralement le choix de la carte graphique que vous souhaitez acheter, mais ce n’est souvent pas le cas avec les ordinateurs portables.Nous n’aimons pas abandonner une plateforme et réécrire chaque fonctionnalité pour chaque plateforme n’aurait pas été faisable.Si nous écrivions une fonction en CUDA, seules les cartes Nvidia la prendraient en charge.En DirectCompute, elle ne fonctionnerait que sous Windows et pas sur Mac ; et même en combinant les deux, nous laisserions encore de côté bon nombre de clients.Le support multi-plateformes, tant pour l’OS que pour la carte graphique, est donc essentiel pour nous.
Deuxièmement, il y a une raison pour laquelle nous avons choisi OpenCL plutôt qu’OpenGL. Deux raisons, en fait.D’une part, l’avantage d’un langage de calcul sur GPU comme OpenCL est qu’il permet d’utiliser certains composants matériels qui ne sont pas nécessairement accessibles via OpenGL, par exemple les unités de traitement des algorithmes à bas niveau.Et d’autre part, OpenGL, comme DirectX est avant tout conçu pour une chose : faire du rendu 3D.Si vous voulez faire autre chose, il faut se demander « comment puis-je me débrouiller pour faire comme si mon problème était du rendu 3D ? ».Cela demande énormément de préparation.Les développeurs qui veulent juste accélérer un algorithme en passant par le GPU, par exemple comme le flou dans Photoshop CS6 ou toute autre fonction qui serait traitée plus rapidement par un GPU, n’ont pas d’expérience en rendu 3D.Ce n’est pas sous cet angle qu’ils abordent leurs problème et il devient donc très pénible d’utiliser OpenGL.OpenCL permet à un bien plus grand nombre de nos développeurs d’adopter le calcul sur GPU.
Tom’s Hardware :CS6 contient beaucoup de nouvelles fonctionnalités et optimisations, mais une seule fait appel à OpenCL : la galerie Flous.Sans voulu manquer de tact, pourquoi n’y en a-t-il qu’une ?Est-ce que c’est un premier test ou est-ce qu’il y a d’autres facteurs qui entrent en jeu ?
Russell Williams :Il faut bien commencer quelque part.L’écosystème OpenCL n’en est qu’à ses balbutiements et nous-mêmes manquons encore d’expérience en la matière.OpenCL n’est réellement disponible et mûr que depuis peu ; nous avons l’intention d’y avoir beaucoup plus recours dans la CS7.Par ailleurs, nous faisons très attention au « retour sur investissement » lors du choix des fonctions à accélérer.La pipette, par exemple, est déjà suffisamment rapide ; il vaut mieux accélérer les fonctions qui sont vraiment trop lentes et perturbent les flux de travail les plus courants.Le but est d’accélérer le travail des utilisateurs, pas d’utiliser OpenCL pour le principe.
Je tiens également à ajouter que nous ne sommes pas les seuls à faire nos premiers pas en OpenCL : c’est le cas de tout le monde ! Quand il s’agit de travailler avec des pilotes qui gèrent OpenCL, le secteur tout entier n’en est qu’à ses débuts.Quand nous avons commencé CS6, sa prise en charge était encore assez limitée.
Q/R avec Adobe (suite)
Tom’s Hardware :Dans Photoshop, quelles sont les limites de ce que vous pouvez faire avec ces API ?
Russell Williams :On voit directement que certaines choses ne sont pas adaptées au traitement via OpenCL ou même via GPU en général.Pour d’autres, il faut essayer, faire quelques efforts, avant de se rendre compte que l’accélération obtenue n’en vaut pas la peine.Le GPU est tout à fait adapté à certaines tâches et pas du tout à d’autres.Je crois que c’est AMD qui m’a dit que, si un GPU pouvait multiplier par un facteur de plusieurs centaines la vitesse de traitement d’un problème auquel il est adapté, il pouvait aussi ralentir par dix celle d’un problème auquel il n’est pas adapté, de quelque chose de fondamentalement séquentiel.
Certaines personnes se demandent « Si le GPU est si rapide, pourquoi ne pas tout faire dessus ? », mais le GPU ne convient qu’à certaines opérations.Qui plus est, il faut réécrire chaque opération que l’on porte sur GPU.Par exemple, nous avons accéléré le filtre Liquify avec OpenGL et non OpenCL, et cela a fait une différence énorme.Pour les pinceaux de grande taille, nous sommes passés de 1 ou 2 images/s à une fluidité parfaite.Ce type de réactivité avec autant de données à modifier n’est faisable que sur un GPU.Mais un ingénieur a passé tout le cycle de développement de CS6 à réécrire la fonction.
Tom’s Hardware :Ce qui nous ramène à la raison pour laquelle vous n’avez transposé qu’une seule fonction en OpenCL cette fois-ci.Vous n’avez pas beaucoup de développeurs et seulement un an entre chaque version.
Russell Williams :C’est exactement cela.Et bien entendu, nous avons encore mois de développeurs qui connaissent déjà OpenCL.
Tom’s Hardware :Les fabricants de cartes graphiques ont-ils joué un rôle dans l’adoption d’OpenCL ?Formations, outils, etc. ?
Russell Williams :Ils ne nous ont pas donné beaucoup d’infos sur la création de leurs outils, mais ils nous ont énormément aidé à apprendre OpenCL et à utiliser les outils qu’ils nous ont fournis.Nvidia et AMD nous ont tous deux apportés leur soutien lors du prototypage des algorithmes, car il est dans leur intérêt de faire en sorte que nous utilisions le GPU.Pour nous, le gros problème réside dans les performances : malheureusement, nous ne pouvons pas partir du principe qu’OpenCL sera parfaitement pris en charge par tous les ordinateurs.Beaucoup de machines sont équipées de moteurs graphiques Intel, dont la partie GPU ne gère OpenGL que de manière limitée et pas du tout OpenCL.Il faut donc aussi écrire les fonctions de manière traditionnelles, en C.Mais d’un autre côté, le GPU peut nous offrir une puissance de traitement nettement plus importante dans certains cas.
À part cela, AMD a mis ses ingénieurs qualité à notre entière disposition.Nous les avons appelés toutes les semaines, avons eu du matériel à disposition pour les tests, etc.Nvidia et Intel nous ont aussi aidé, mais AMD en a vraiment fait beaucoup pour nous.
Tom’s Hardware :Donc quelle société a les meilleurs produits ? AMD ou Nvidia ? [rire]
Russell Williams :Vous travaillez pour Tom’s Hardware, ce n’est pas à vous que je dois dire que cela dépend de l’application.C’est pour cela qu’il est si essentiel pour nous d’être compatible avec les deux fabricants.Enfin, trois si on tient compte des moteurs graphiques intégrés d’Intel, qui commencent à devenir viables.
Tom’s Hardware :À certains moments, vous rencontrez inévitablement des goulots d’étranglement.Jusqu’où allez-vous pour tenter de les éviter ?Est-ce que vous vous dites « OK, ça va déjà cinq fois plus vite, ça suffit ! » ou est-ce que vous continuez à pousser jusqu’à ce que vous vous heurtiez à un mur ?
Russell Williams :C’est une chose à laquelle nous pensons, mais il est impossible de savoir à l’avance quels gains de performances nous allons obtenir.Nous savons que nous devons passer beaucoup de temps à régler les problèmes de bande passante.Photoshop traite des quantités astronomiques de pixels, et leur déplacement représente un problème considérable, raison pour laquelle nous faisons particulièrement attention à chaque passage par le pipeline de traitement.Souvent, c’est un facteur plus limitant que les calculs effectués sur les pixels !C’est en particulier le cas avec les cartes graphiques séparées : il faut déplacer les pixels vers la carte graphique puis les rapatrier.
Tom’s Hardware :Donc c’est généralement le bus qui constitue votre goulot d’étranglement ?
Russell Williams :Oui, le bus PCI Express.Je pense sincèrement qu’à l’avenir, les APU vont nous obliger à repenser aux fonctions que nous souhaitons accélérer, en particulier lorsqu’ils commenceront à utiliser le « zéro copie ».Avec un APU, il n’est plus nécessaire de passer par le bus PCI pour atteindre le GPU ; on a moins de latence.Actuellement, il faut encore passer par le pilote, qui doit copier les données d’une position en mémoire système vers une autre, c’est-à-dire de l’espace réservé au CPU à celui réservé au GPU.Les fabricants sont en train d’essayer d’éliminer cette étape.Plus ils amélioreront l’efficacité de leurs puces, plus il sera rentable d’effectuer des petites opérations sur les APU.
Par contre, les APU ne sont pas aussi rapide que les cartes graphiques séparées.D’une certaine manière, tout dépend de la bande passante de la mémoire de la carte par rapport à celle de la mémoire système.Mais il faut aussi tenir compte de la consommation : les cartes graphiques consomment souvent à elles seules plusieurs centaines de watts ; c’est ce qui se passe quand on copie d’énormes quantités de données en passant par un petit tuyau pour atteindre un composant qui chauffe autant qu’un toaster.Bref, ça dépend toujours.Il faut que la puissance de traitement de la carte soit suffisante pour compenser le passage aller-retour par le bus PCI.
Q/R avec Adobe (suite)
Tom’s Hardware :Est-ce que les opérations de retouche photo peuvent saturer les 16 lignes d’un bus PCI Express 2.0 ?
Russell Williams :Je n’ai pas les chiffres en tête, mais prenez une photo 16 mégapixels prise avec un réflex numérique.Imaginez que vous voulez, par exemple, modifier l’inclinaison du plan de flou dans la galerie Flous, et que vous voulez le faire en temps réel, à 30 ou 60 images/s.Il faut ensuite composer le résultat avec 50 autres calques, et cette composition doit se faire sur le CPU parce que le moteur de composition ne se fait pas sur le GPU.Il faut recopier les données dans l’autre sens à 30 ou 60 images/s ; on copie donc toute une image entière qui doit être traitée deux ou trois fois par image/s.Là, d’un coup, le bus PCI Express paraît bien plus maigre qu’au départ…
On peut aussi voir la chose sous un autre angle.Que le bus PCI soit suffisamment rapide ou non, ce qui compte réellement, c’est de savoir s’il ne fait pas perdre tous les gains que l’on obtient en effectuant les calculs sur la carte graphique.Si le traitement prend deux fois moins de temps sur la carte graphique, par exemple, le passage par le bus est capable de ramener le gain total à quelque chose comme 10% à peine.J’ai une métaphore : c’est comme aller jusqu’à New York pour faire un sandwich.

Tom’s Hardware :Pardon ??
Russell Williams :Imaginez que vous vouliez faire un sandwich, et qu’il y ait à New York une machine capable de faire un sandwich en deux secondes ; en dépit de la rapidité de cette machine, cela n’a tout de même pas de sens de rouler jusqu’à New York pour l’utiliser si vous habitez en Californie.La faible latence des APU nous permet d’utiliser la portion GPU de tout un tas de manières qui n’auraient aucun sens sur une carte graphique séparée.L’APU est vraiment un nouveau type de calculateur.À l’avenir, il est très probable que notre code contienne pas mal de cases disant « SI carte graphique séparée, ALORS utiliser carte graphique », mais il y en aura probablement beaucoup plus disant « SI APU, ALORS utiliser APU ».
Tom’s Hardware :Quel est l’avenir des shaders face à OpenCL et aux API du même type ?Adobe a adopté une approche propriétaire avec le Pixel Bender, mais pensez-vous continuer dans cette voie alors que le marché évolue vers les normes ouvertes ?
Russell Williams :Les shaders ont toujours énormément d’avenir ; les API graphiques telles qu’OpenGL et DirectX ne sont pas prêtes de disparaître.OpenGL avec des shaders personnalisés reste la meilleure solution pour les problèmes similaires au rendu 3D, comme le rendu 3D ou le filtre Liquify dans Photoshop.Pour ce qui est du Pixel Bender, je ne peux pas m’avancer à la place d’Adobe, mais d’après moi, la programmation GPGPU a beaucoup évolué depuis l’époque où nous l’avons lancé, et il y a aujourd’hui une approche normalisée, l’OpenCL, qui fait la même chose ; c’est donc ce vers quoi je me dirigerais.Nous sommes membres du Khronos Group et nous allons partager l’expérience que nous avons acquise lors de la conception du Pixel Bender pour améliorer les futures versions d’OpenCL.
Tom’s Hardware :J’ai l’impression que la plupart des gens perçoivent encore les processeurs avec moteur graphique intégré (les APU) comme des puces d’entrée de gamme.Peut-être est-ce juste parce que nous avons souffert si longtemps des faibles performances des northbridges avec moteur graphique Intel, je ne sais pas…Mais est-ce qu’aujourd’hui, le marché a évolué ?Est-ce que les APU et l’architecture de calcul hétérogène change vraiment la donne ?
Russell Williams :Aujourd’hui, nous avons à notre disposition plusieurs sources de puissance de calcul.Auparavant, nous n’en avions qu’une seule, le processeur, et il fallait coder en C pour l’utiliser.De nous jours, on a accès à énormément de puissance sur le GPU, mais celui-ci ne convient que pour certains problèmes, et sur le CPU, une bonne partie de la puissance de traitement réside dans des cores multiples et dans des unités séparées comme les modules de calcul vectoriel, qui ne servent qu’à résoudre des problèmes bien spécifiques.Pour profiter pleinement de toutes les ressources disponibles, il faut donc utiliser ces différentes unités de traitement ; il faut les utiliser toutes en même temps et leur faire faire ce qu’elle font le mieux.Notre objectif est de les utiliser toutes simultanément et d’offrir à l’utilisateur quelque chose d’aussi réactif que possible : nous essayons de nous éloigner du modèle « je paramètre, je clique sur OK et je patiente en regardant avancer la barre de progression » en faveur de quelque chose de plus ludique, plus immédiat, où on modifie l’image directement et où on a directement le résultat.La seule manière d’y parvenir est d’utiliser toutes les sources de calcul disponibles.
L’intérêt des processeurs avec moteur graphique intégré, c’est qu’ils permettent à un plus grand nombre de plateformes différentes de bénéficier de capacités de calcul hétérogène : beaucoup de plateformes n’ont en effet pas l’espace, le budget ou la puissance électrique nécessaires pour une carte graphique séparée.Dans les environnements de ce type, les APU apportent énormément de performances supplémentaires.L’autre avantage des APU réside dans le rapport performances/consommation : quand on a une enveloppe énergétique fixe, il est difficile d’obtenir des gains de performances significatifs avec le seul CPU.L’époque des CPU avec des performances en hausse de 50 % tous les ans, c’est fini.Et ce n’est pas en ajoutant des cores qu’on va résoudre le problème, car il est trop difficile de les utiliser correctement : le nombre de programmes qui pourraient réellement tirer profiter d’un processeur mono-socket à 24 cores est proche du zéro absolu.Bref, le GPU est actuellement le meilleur moyen d’augmenter le budget « transistors » de manière utilisable.
Je pense que le calcul GPGPU et les APU commencent seulement à tenir leurs promesses ; il aura fallu de nombreuses années pour y arriver, mais leur potentiel va être de plus en plus exploité, non seulement au sein de Photoshop, mais dans les futures versions d’autres applications Adobe.
Résultats : GIMP
Dans un premier temps, nos tests sous GIMP n’ont pas donné les résultats escomptés.Nous avions commencé par tester les effets GEGL que sont le filtre bilatéral, edge-laplace et flou de mouvement, mais sur la machine AMD A8 avec OpenCL activé, les deux derniers effets ne cessaient de donner des résultats identiques, peu importe que l’on utilise le moteur graphique intégré ou la carte graphique Radeon HD 7970, alors que la 7970 aurait normalement dû laisser l’APU sur le carreau.
C’est en discutant avec AMD et les développeurs que nos soupçons se sont confirmés : nous nous trouvions face à un goulot d’étranglement au niveau de la partie CPU de l’A8.Les calculs n’étaient tout bonnement pas assez intensifs pour que la présence du GPU se fasse ressentir.Ce qui nous permet de souligner un point important : si votre charge de travail n’est pas suffisamment intense, il est possible, selon la manière dont votre logiciel est codé, que le GPU ne vous apporte pas autant d’accélération que prévu.
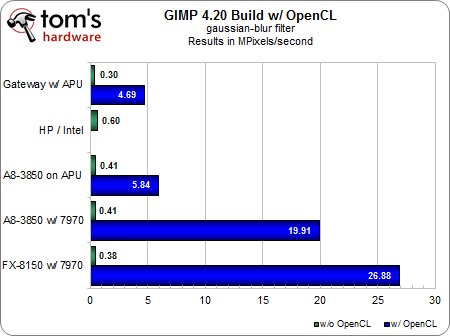
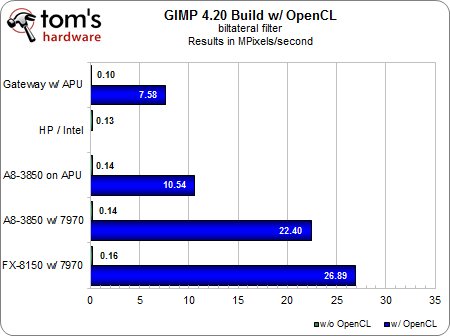
Nous avons donc dû modifier nos tests afin d’accroître la charge de travail et de mettre en lumière les différences entre les plateformes.Nous avons remplacé l’edge-laplace par le flou gaussien, dont nous avons gonflé les valeurs des variables X et Y à 20,0 ; nous avons conservé le flou de mouvement, mais avons fait passer le paramètre « longueur » à 100 et l’angle à 45.Ce qui nous a donné les résultats suivants.
Flou gaussien
Filtre bilatéral
Flou de mouvement
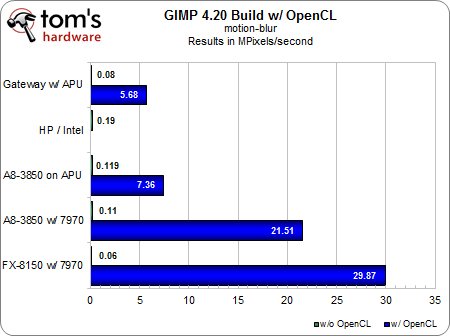
Dans ce test comme dans les suivants, vous remarquerez le vide à l’endroit où devraient normalement se trouver les résultats obtenus par notre ordinateur portable HD en OpenCL ; la raison en est toute simple : le moteur graphique des Intel Sandy Bridge ne gère pas OpenCL (et nous n’avons pas encore de machine de test à base de Core i5 Ivy Bridge).Nous avons toutefois décidé de laisser cet ordinateur dans la liste, car il y a quelques cas où les performances du processeur Intel fonctionnant en mode logiciel pur permettent de faire une comparaison intéressante avec l’accélération par GPU.Après tout, cette dernière n’en est encore qu’à ses balbutiements et la plupart des applications ne sont pas encore optimisées pour elle ; il est donc important de garder un œil sur la manière dont se comportent les plateformes non accélérées.
Sous GIMP, les avantages de l’OpenCL et de l’accélération par GPU sont toutefois plus qu’évidents, au point qu’il serait même ridicule de calculer la différence en pourcentage : sans accélération, ces filtres sont pratiquement inutilisables, quelle que soit la configuration utilisée.Il devient impossible de travail et le système applique le flou un bloc à la fois.Activez l’OpenCL et c’est une toute autre histoire : d’un seul coup, les performances grimpent en flèche et évoluent de manière parfaitement naturelle au fur et à mesure que l’on passe de l’APU mobile à l’APU de bureau puis aux cartes graphiques.Notez que le moteur graphique ne fait pas tout le travail : selon le test, la partie CPU contribue encore à 20 à 40 % du résultat final.
Bien entendu, tout cela ne vaut que si votre charge de travail est suffisante.N’oubliez pas que nous avons dû modifier notre protocole de test original pour mettre en évidence les différences entre les configurations.Sans cette pression délibérément exagérée, les cores x86 des processeurs AMD prennent le pas sur les moteurs graphiques, dont le taux d’utilisation tombe pratiquement à zéro.Nous sommes certains que les développeurs savent ce qu’ils font en matière d’équilibrage des ressources et que les tests que nous avons effectués aujourd’hui ne vont pas tarder à devenir une réalité pour beaucoup plus de gens ; mais à l’heure actuelle, attendez-vous tout de même à des résultats plus mitigés.
Résultats : AfterShot Pro
Comme nous l’avons indiqué précédemment, Corel a eu la gentillesse de nous fournir une préversion d’AfterShot Pro prenant en charge OpenCL, et nous l’en remercions sincèrement.Comme nous l’a confié Jeff Stephens, directeur du développement d’AfterShot Pro et ancien président de Bibble Labs, AfterShot se focalisait jusqu’à présent sur les optimisations côté CPU :
« AfterShot Pro 1.0 n’utilise absolument pas le GPU.Il y a des années, Bibble Labs, que Corel a racheté il y a environ un an, avait décidé de se concentrer sur le multi-core plutôt que sur le calcul via le moteur graphique.Cette décision s’est très longtemps avérée payante : Bibble 4, Bibble 5 et maintenant AfterShot Pro sont aujourd’hui encore les logiciels de conversion RAW les plus rapides du marché.C’est non seulement vrai en présence d’un seul processeur, mais également de plusieurs : les performances évoluent de manière très linéaire jusqu’à huit processeurs et continuent à grimper jusqu’à 16 cores, et même au-delà en fait.La nouveauté, c’est qu’OpenCL nous permet aujourd’hui de doubler les performances du logiciel sur les ordinateurs existants en utilisant le GPU, qui restait précédemment au repos, tout en continuant à utiliser tous les cores CPU disponibles. »
Conversion de 50 images RAW en JPEG (résultats en secondes)
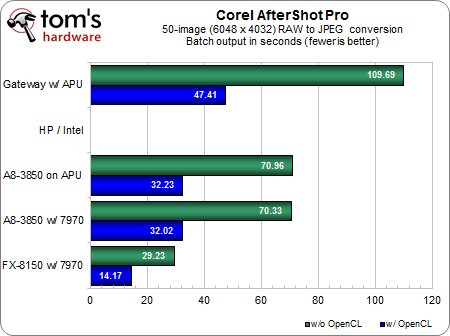
Comme promis, Corel double les performances de nos configurations de tests lorsqu’OpenCL est activé.
Vous remarquerez sans doute que notre machine de bureau à base d’A8 offre des résultats pratiquement identiques avec et sans carte graphique séparée. Cela nous a paru familier, mais avons de tirer des conclusions hâtives et de crier au goulot d’étranglement, nous avons transmis nos résultats à Corel.Celui-ci a refait le test sur une machine très similaire à la nôtre (AMD A8, Radeon HD 7970, etc.), mais a obtenu des résultats légèrement différents et plus conformes à nos attentes : 27,35 s avec OpenCL sur la 7970 et 36,30 s avec OpenCL sur l’APU.Malheureusement, même après avoir revérifié notre configuration (BIOS, pilotes, version d’OpenCL identiques, etc.), nos résultats sont restés inchangés.Vous êtes donc prévenu : les performances peuvent varier d’une machine à l’autre.
Enfin, AfterShot Pro (en préversion, ne l’oublions pas) n’a pas daigné fonctionner sur notre ordinateur portable HP / Sandy Bridge en raison d’une erreur de type « program can’t start because OpenCL.dll is missing » ; nous n’avons donc aucun résultat à vous présenter pour cette configuration.
Résultats : Musemage
Les photographes amateurs parmi nous se demandaient tout particulièrement ce qu’allait donner le test sous Musemage.Qui ne s’est jamais retrouvé à la fin d’un week-end en famille avec des dizaines de photos à retoucher ? Si chaque prise de vue est différente, il est bien souvent nécessaire de d’atténuer le flash, d’améliorer la saturation, de redimensionner les fichiers pour les envoyer par e-mail, etc.Le plus souvent, nous abandonnons avant même d’avoir commencé car ces opérations prennent trop de temps, mais Musemage nous promet de les accomplir en quelques secondes à peine… si toutefois il fonctionne comme prévu.
Score (benchmark intégré)
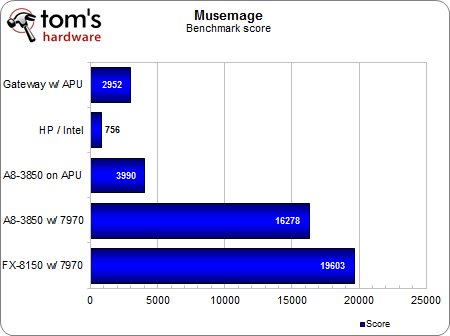
Nous avons commencé par lancer le module de benchmark intégré au logiciel, petit clin d’œil des développeurs aux journalistes et aux amateurs de performances.Celui-ci charge une image prédéfinie et la soumet à environ 80 effets.Le score obtenu est proportionnel aux performances, et nous constatons d’immense écarts entre les différentes configurations, et notamment entre la Radeon HD 7970 et l’APU.Il apparaît clairement que Musemage est particulièrement adepte à l’utilisation du GPU ainsi qu’à éviter les goulots d’étranglements qui, comme l’indique Adobe, sont imposés par le bus PCI Express.
Nous avons découvert lors du test que Musemage, comme Photoshop CS6, utilise essentiellement OpenGL pour l’accélération matérielle : la seule fonction que le logiciel fait actuellement transiter par OpenCL est le traitement HDR.
Traitement HDR
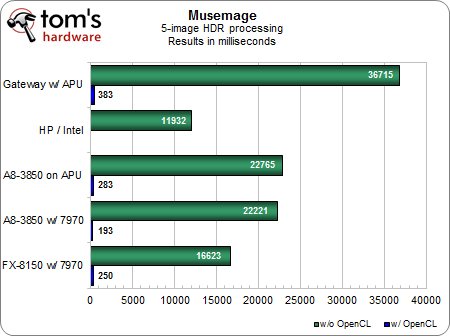
Avec les pilotes actuels, l’Intel HD Graphics 3000 est compatible OpenGL 3.0 (mais ne prend pas en charge l’OpenCL), ce qui explique pourquoi notre petit ordinateur portable à base de Core i5 parvient à battre toutes les autres configurations, même l’AMD FX-8150, lors du test de traitement HDR.
Il suffit toutefois de réactiver OpenCL pour que les résultats prennent une toute autre dimension.Il est quelque peu étrange que notre configuration à base d’AMD FX + Radeon HD 7970 soit légèrement plus lente que l’A8 avec la même carte, mais au vu de la vitesse de traitement obtenue, il est probablement que les 60 millisecondes d’écart soient imputables à la marge d’erreur.
Traitement par lot (8 images, 11 opérations)
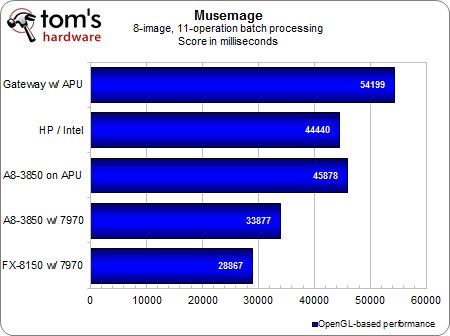
Nous terminerons par le test que nous attendions avec le plus d’impatience : celui du traitement par lot.Les performances des puces AMD correspondent bien à nos attentes, la configuration FX/7970 prenant environ deux fois moins de temps que notre portable à base d’APU.Nous avons été quelque peu surpris de voir le portable Intel obtenir des résultats situés dans la moyenne et même légèrement meilleurs que ceux de l’A8 desktop sans carte graphique.Cela semble indiquer que Musemage utilise OpenGL version en 3.1 ou inférieure et non la version actuelle (4.x) afin de profiter au maximum du parc de machines Intel présentes sur le marché.Notons que l’Intel HD Graphics 4000 gère bien l’OpenGL 4.0 et l’OpenCL 1.1.Il n’en reste pas moins que pour obtenir des performances optimales sous OpenGL, l’idéal est d’avoir une vraie carte graphique.
Résultats : Photoshop CS6
Nous terminerons par le joyau de notre batterie de tests : Photoshop CS6.
Script « Liquify »
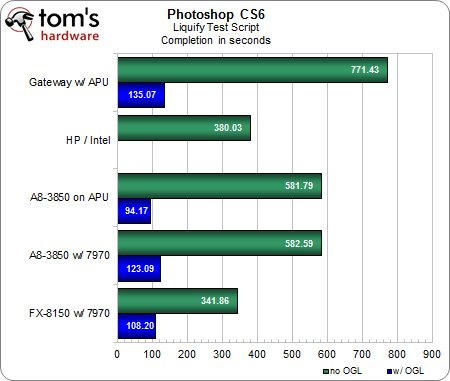
Une fois de plus, sans accélération matérielle, l’Intel Core i5 s’en tire avec les honneurs et ne se laisse dépasser que par la configuration AMD FX / Radeon HD 7970.Dès que l’on active OpenGL, par contre, les performances des autres machines augmentent de 200 à 500 %.Étonnamment, la configuration avec A8 sans carte graphique est celle qui obtient le meilleur temps, tandis que les machines avec Radeon HD 7970 affichent des performances inférieures à celles attendues.
Script « flou », CMJN 25 et RVB 25
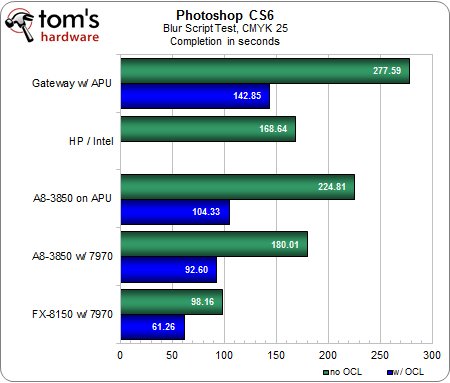
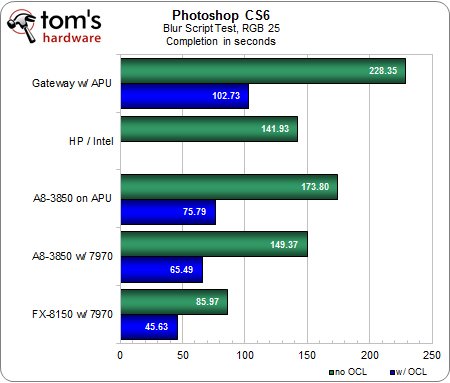
Sans surprise, le test en CMJN prend 10 à 20 % de temps en plus à réaliser que celui en RVB, à mais à part cela, les tendances sont identiques.La première tentative d’Adobe d’utiliser l’OpenCL dans Photoshop donne des résultats probants et conformes à nos attentes : la configuration AMD FX / Radeon HD 7970 est environ deux fois plus rapide que l’AMD A8 mobile, qui du coup ne s’en tire pas trop mal.Après tout, 50 % des performances d’une carte graphique haut de gamme pour un prix pratiquement nul, c’est une affaire.L’AMD A8 desktop termine pile entre les deux, ce qui le rend encore plus attrayant pour les utilisateurs ne souhaitant pas casser leur tirelire.
Script « flou », CMJN 300 et RVB 300
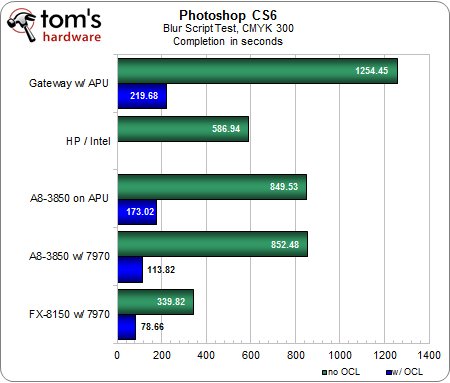
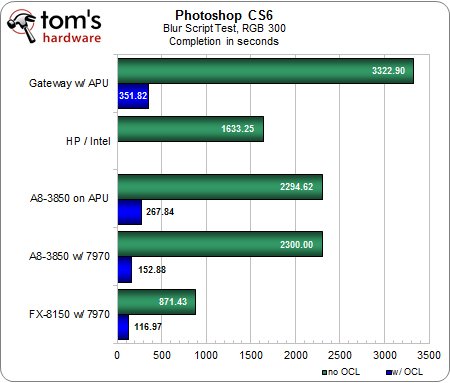
Curieusement, le flou en CMJN devient nettement plus rapide lorsque nous le paramétrons sur 300… allez comprendre.Néanmoins, le classement et les écarts de performances restent similaires, bien que la différence entre la configuration d’entrée de gamme et la machine haut de gamme soit maintenant plus proche des 200 % avec l’OpenCL activé.Par ailleurs, la hausse de la charge de travail permet de voir plus clairement à quel point l’accélération via GPU peut donner des résultats spectaculaires par rapport au mode logiciel pur : sur notre machine A8 / Radeon HD 7970, le test s’effectue 15 fois plus rapidement !
Conclusion
Au final, les résultats de nos tests démontrent clairement que l’accélération du calcul par le GPU est désormais presque un passage obligé pour toute personne ayant du travail de retouche sérieux à effectuer.De nos jours, les créateurs de contenu doivent non seulement se doter de matériel capable d’accélérer leurs applications, mais également faire attention à la manière dont ces applications utilisent leur matériel.Si les outils que vous utilisez ne tirent pas encore parti de l’accélération par GPU, il vaut peut-être la peine de se demander pourquoi.Toutes les tâches ne se prêtent en effet pas au parallélisme que nécessite le traitement par GPU, mais force est de constater que celui-ci convient en fait à la plupart des opérations de type multimédia.La question est maintenant celle de l’adoption de cette nouvelle technologie par les éditeurs…

Comme l’indique Victor Oliveira, développeur sur GIMP/GEGL, « l’API OpenCL en elle-même n’est pas particulièrement difficile à maîtriser.En fait, pour du calcul généraliste, elle me paraît même plus propre que les autres API telles qu’OpenGL ou CUDA.Là où les choses se corsent, c’est quand il faut intégrer OpenCL dans une application qui, à la base, ne gère pas les performances et le parallélisme.Quand il faut traiter des données réparties entre plusieurs fonctions puis mettre le tout dans un noyau, cela peut devenir compliqué, ce qui peut expliquer pourquoi OpenCL a tant de mal à se faire adopter ».
D’après Victor Oliveira, les API d’accélération propriétaires vont probablement conserver leur implantation dans les marchés de niches tels que le calcul intensif (high-performance computing).Côté grand public, par contre, les API open source devraient finir par se tailler la part du lion ; plus il y aura d’éditeurs qui les adopteront, plus la transition sera rapide.
« Je trouve très positif qu’AMD soutiennent les normes ouvertes », déclare le développeur.« Cela contribue réellement à mettre les développeurs (c’est en tout cas valable pour moi) en confiance vis-à-vis d’OpenCL, surtout dans le monde de l’open source.Plus OpenCL sera populaire, plus il y aura d’applications comme GIMP qui l’utiliseront, en premier lieu dans les domaines qui ont le plus à gagner du modèle de programmation parallèle qu’introduit le GPGPU : la retouche photo/vidéo/audio, l’apprentissage automatique, les jeux, etc. »
« Nous allons continuer à suivre de près toutes les avancées en matière de GPGPU, en plus de celles du monde des processeurs, dans le but d’accélérer nos produits », ajoute Jeff Stephen, de Corel.« La rapidité, ce n’est plus juste faire les mêmes choses en moins de temps ; c’est également quelque chose qui nous ouvre de nouvelles portes et nous permet de faire des choses qui étaient auparavant trop lentes pour que nous espérions pouvoir les utiliser ».
En ce qui nous concerne, nous attendons ces évolutions avec impatience.Tant que les utilisateurs effectuent leurs calculs localement plutôt que via le cloud, il nous semble que les configurations prenant en charge le calcul GPGPU vont engendrer de nouveaux besoins, en particulier dans le domaine de la mobilité.Jusqu’il y a peu, personne n’aurait osé exécuter une tâche graphique intense sur un ordinateur portable ni osé rêver que les plateformes hétérogènes puissent réaliser les opérations de ce type avec autant d’élégance.