Après Stable Diffusion pour les images, Stability AI se lance dans la vidéo avec Stable Video Diffusion. Le modèle d’IA générative de l’entreprise peut générer une séquence de quelques secondes à partir de peu d’éléments.
La société Stability AI, qui a déjà la maternité du modèle d’IA générative d’images Stable Diffusion, vient d’annoncer Stable Video Diffusion. Comme son nom l’indique, il s’agit toujours d’une IA générative, mais pour la vidéo cette fois.
À ce stade, Stable Video Diffusion reste en version preview et n’est disponible qu’à des fins de recherche ; le modèle n’a pas d’applications commerciales pour le moment. L’entreprise écrit : « Désormais disponible en avant-première, ce modèle vidéo d’IA générative de pointe représente une étape importante dans notre démarche visant à créer des modèles pour tout le monde, quel que soit le type de vidéo. »
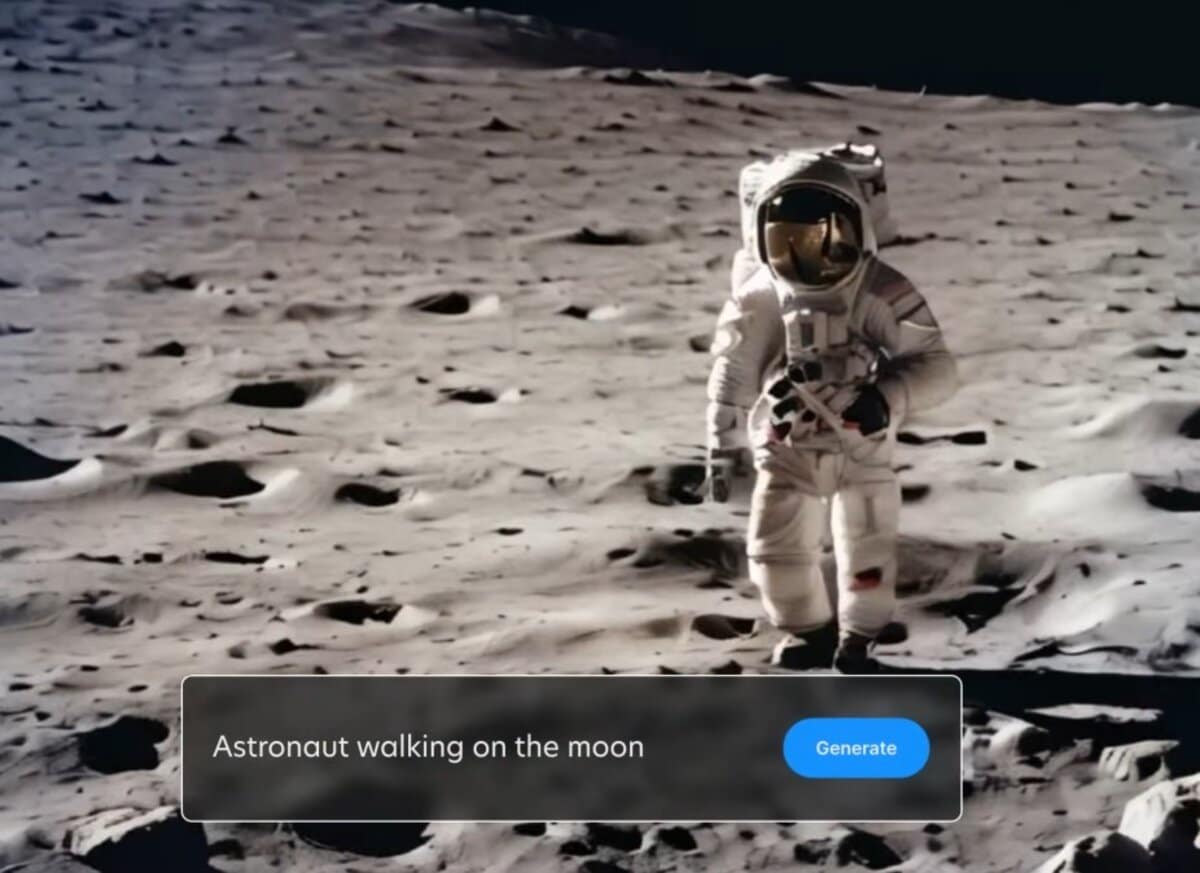
En pratique, l’outil est capable de générer des vidéos à partir d’images ou de texte en langage naturel (méthode montrée dans la vidéo de présentation ci-dessous, similaire à Pika Labs notamment). Les exemples utilisés sont un dragon de glace dans la montagne, un astronaute marchant sur la Lune ou encore deux geais bleus au sommet d’un bâtiment.
Jusqu’à 25 images générées
D’autre part, n’attendez pas de génération en 4K à 120 images par seconde pour le moment, puisque le modèle peut générer de 14 à 25 images dans une définition de 576 x 1024 pixels et les afficher à une fréquence comprise entre 3 et 30 images par seconde.
Selon l’entreprise, Stable Video Diffusion peut servir à des fins de recherche sur les modèles génératifs, à la génération d’œuvres d’art et plus globalement dans le processus créatif, ainsi que pour des applications éducatives.
Précisons que Stability AI a été poursuivie par Getty Images pour avoir utilisé illégalement certaines archives pour entraîner Stable Diffusion et que l’un de ses cadres, Ed Newton-Rex, a été contraint de démissionner la semaine dernière à cause du non-respect des droits d’auteur.
Pour entraîner Stable Video Diffusion, la société prétend qu’elle a utilisé des vidéos publiques uniquement (sur un ensemble de données issues de millions de vidéo avant de perfectionner le modèle sur des ensembles plus restreints).
Pour finir, les limites techniques mentionnées par l’entreprise sont les suivantes : l’outil génère des vidéos relativement courtes (moins de 4 secondes), n’est pas parfaitement photoréaliste, ne peut pas effectuer de mouvements de caméra à l’exception de panoramiques lents, n’a pas de contrôle du texte, ne peut pas générer de texte lisible et peut ne pas générer correctement des personnes et des visages.
Source : Stability.Ai