Introduction
De combien de cores a-t-on réellement besoin ? Deux ? Quatre ? Six ? La réponse, comme souvent, dépend de ce que l’on fait de son ordinateur. D’après notre expérience, la plupart des jeux tournent mieux sur une machine en possédant au moins trois. Bon nombre de logiciels de retouche vidéo sont capables de gérer tous les cores disponibles. À l’inverse, les logiciels de bureautique ont plutôt tendance à ne pas profiter du tout du parallélisme.
Nous l’affirmons depuis toujours : un bon ordinateur est un ordinateur équilibré ; c’est en effet cet équilibre qui permet d’éviter les goulots d’étranglement. Aujourd’hui, AMD, fabricant de processeurs et de cartes graphiques, semble vouloir faire passer le même message.

Lorsque les diapositives marketing d’une société devant présenter son nouveau processeur haut de gamme pour ordinateur de bureau font la part belle aux machines à bas prix, on peut en toute légitimité s’attendre à… un processeur pour machines à bas prix. Sans vouloir trop en dévoiler, les amateurs de performances qui espéraient voir l’architecture Bulldozer d’AMD mettre la pâtée aux Intel Sandy Bridge et faire concurrence aux Sandy Bridge-E vont devoir revoir leurs attentes à la baisse : la société vise en effet plutôt un marché en pleine effervescence en ce moment, celui des utilisateurs cherchant à payer moins pour leur matériel que par le passé.
Mais après tout, où est le problème ? Les Sandy Bridge ont montré aux power users qu’il n’était plus nécessaire de prendre un processeur à 500 € pour obtenir des performances dignes de ce nom : pour 200 € à peine, on a aujourd’hui une puce déverrouillée capable de fonctionner de manière stable à 4,5 GHz et d’atomiser les Intel Gulftown Extreme Edition dans bon nombre de tests, y compris dans les jeux. Si AMD parvient à nous offrir un meilleur rapport performances/prix sur ce marché, ce n’est pas nous qui nous en plaindrons… ni personne d’autre, d’ailleurs.
La gamme AMD FX
Sur papier au moins, la gamme de processeurs qu’AMD compte lancer prochainement nous paraît complète et concurrentielle. Elle comporte sept modèles différents allant, par ordre décroissant de puissance, du FX-8150 au FX-4100. Tous sont de la famille Zambezi, gravés en 32 nm par GlobalFoundries et composés d’environ deux milliards de transistors. Leur die fait 315 mm², soit moins que les Thuban (346 mm³), mais plus que les Deneb (258 mm²) ; les Sandy Bridge d’Intel, à titre de comparaison, font 216 mm².
| Modèle | Fréq. de base | Fréq. Turbo Core | Fréq. Turbo Core max. | TDP | Cores | Cache L2 total | Cache L3 partagé | Fréq. northbridge |
|---|---|---|---|---|---|---|---|---|
| FX-8150 | 3,6 GHz | 3,9 GHz | 4,2 GHz | 125 watts | 8 | 8 Mo | 8 Mo | 2,2 GHz |
| FX-8120 | 3,1 GHz | 3,4 GHz | 4,0 GHz | 125 / 95 watts | 8 | 8 Mo | 8 Mo | 2,2 GHz |
| FX-8100 | 2,8 GHz | 3,1 GHz | 3,7 GHz | 95 watts | 8 | 8 Mo | 8 Mo | 2,0 GHz |
| FX-6100 | 3,3 GHz | 3,6 GHz | 3,9 GHz | 95 watts | 6 | 6 Mo | 8 Mo | 2,0 GHz |
| FX-4170 | 4,2 GHz | – | 4,3 GHz | 125 watts | 4 | 4 Mo | 8 Mo | 2,2 GHz |
| FX-B4150 | 3,8 GHz | 3,9 GHz | 4,0 GHz | 95 watts | 4 | 4 Mo | 8 Mo | 2,2 GHz |
| FX-4100 | 3,6 GHz | 3,7 GHz | 3,8 GHz | 95 watts | 4 | 4 Mo | 8 Mo | 2,0 GHz |
La manière la plus simple d’analyser cette gamme est de la diviser en fonction du nombre de cores : quatre, six ou huit (c’est-à-dire, comme nous allons le voir plus tard, deux, trois ou quatre modules Bulldozer). Le numéro de chaque modèle nous aide d’ailleurs à faire cette même différenciation : les FX-8xxx contiennent huit cores, les FX-6xxx six et les FX-4xxx quatre.
Les trois chiffres qui suivent indiquent de manière arbitraire les performances au sein de chaque sous-catégorie. Ils ne correspondent pas à la fréquence, ni au TDP ou à la quantité de cache L2 ; il faut simplement se dire que, parmi les FX-8xxx par exemple, le 8150 est plus rapide que 8120, lui-même plus performant que le 8100.

Tous les processeurs de la gamme FX, du plus modeste au plus performant, ont un coefficient multiplicateur déverrouillé, ce qui signifie qu’il y aura peut-être des aubaines à saisir selon l’agressivité du mode Turbo Core. Vous vous souvenez du lancement des Intel Nehalem en 2008 ? Les amateurs de performances se sont rués sur le Core i7-920 parce qu’il pouvait monter à 4 GHz et qu’il était bon marché. Il reste juste à voir si les puces 32 nm de GlobalFoundries parviendront à se forger la même réputation.
Pour le lancement, AMD a choisi d’éviter de provoquer la moindre confusion sur les noms, car seuls quatre modèles seront disponibles dans un premier temps : les FX-8150, FX-8120, FX-6100 et FX-4100.
| Modèle | Fréq. de base | Fréq. Turbo Core | Fréq. Turbo Core max. | TDP | Cores | Prix public conseillé (USA) |
|---|---|---|---|---|---|---|
| FX-8150 | 3,6 GHz | 3,9 GHz | 4,2 GHz | 125 watts | 8 | 245 $ |
| FX-8120 | 3,1 GHz | 3,4 GHz | 4,0 GHz | 125 watts | 8 | 205 $ |
| FX-6100 | 3,3 GHz | 3,6 GHz | 3,9 GHz | 125 watts | 6 | 165 $ |
| FX-4100 | 3,6 GHz | 3,7 GHz | 3,8 GHz | 95 watts | 4 | 115 $ |
En termes de prix, ce quatuor démarre où la gamme Phenom II s’arrête. Le FX-4100 sera commercialisé à un prix similaire à celui des processeurs de la génération précédente (environ 115 $), mais offrira quatre cores et des fréquences comprises entre 3,6 et 3,8 GHz ; le FX-6100, cadencé à 3,3 GHz de base et pouvant atteindre 3,9 GHz, sera disponible au prix de 165 $ ; le FX-8120, armé de huit cores, cadencé à 3,1 GHz et pouvant monter jusqu’à 4 GHz, devrait être proposé à 205 $ ; et le FX-8150, modèle le plus puissant de la série avec sa fréquence de 3,6 GHz pouvant grimper jusqu’à 4,2 GHz, affiche un prix public recommandé de 245 $.
Pour cette évaluation, AMD ne nous a fait parvenir qu’un seul modèle : le FX-8150. Nos impressions sur les trois autres processeurs devront donc attendre. Nous n’avons reçu aucune information sur la date de sortie des quatre autres modèles, ni sur le prix auquel ils seront commercialisés, mais très franchement, peu nous importe pour l’instant : le processeur le plus rapide jamais créé par AMD nous attend avec impatience sur notre banc d’essai, et il nous tarde de voir ce qu’il a dans le ventre.
Carte-mère : AM3+ obligatoire
Lorsqu’AMD a lancé son chipset 990FX (voir notre article intitulé 990FX (AM3+) : le renouveau d’AMD et du SLI ?), il n’y a pas eu grand-chose à en dire, si ce n’est qu’il apportait la prise en charge du socket AM3+ et du SLI. Pour autant, cette idée de mettre à jour les cartes-mères avant de proposer les processeurs compatibles est loin d’avoir été mauvaise : elle a en effet permis de préparer le terrain pour les FX. Tous les processeurs pour socket AM3 déjà disponibles à l’époque pouvant s’insérer dans les cartes-mères à chipset 990FX, on trouve aujourd’hui chez les utilisateurs bon nombre de machines comportant d’ores et déjà un socket AM3+ qui n’attend plus qu’une chose : un changement de processeur.
Comme nous le signalions dans l’article, précité : « Pour pouvoir bénéficier des fonctionnalités de gestion de l’énergie et de la fréquence des Zambezi, il faut absolument avoir un socket AM3+ (également appelé AM3b), à 942 broches. »
Si vous possédez déjà une carte-mère équipée d’un socket AM3+, vous devrez flasher son firmware à l’aide d’un processeur pour socket AM3 avant de remplacer celui-ci par un FX. Cette mise à jour, qui modifie le module AGESA (AMD Generic Encapsulated Software Architecture) du BIOS, est nécessaire pour activer la gestion de l’architecture Bulldozer.
Petite mise en garde à destination des utilisateurs de Phenom II Thuban ou Deneb : il est déconseillé de procéder à cette mise à jour si vous ne comptez pas opter pour un FX. D’après ce que nous ont dit les fabricants de cartes-mères, les importants changements apportés au module AGESA affectent en effet négativement les performances de ces anciens processeurs.
Les processeurs FX ne fonctionnent pas avec les cartes-mères AM3. AMD a délibéré verrouillé cette combinaison dans le BIOS. Mais que se passe-t-il si vous possédez une carte-mère socket AM3+ et chipset 890FX ? AMD ne prend pas explicitement en charge cette configuration. La compatibilité avec les processeurs FX est donc à vérifier au cas par cas ; reste que si le fabricant de votre carte-mère affirme que celle-ci les gère, il n’y a aucune raison de ne pas le croire.
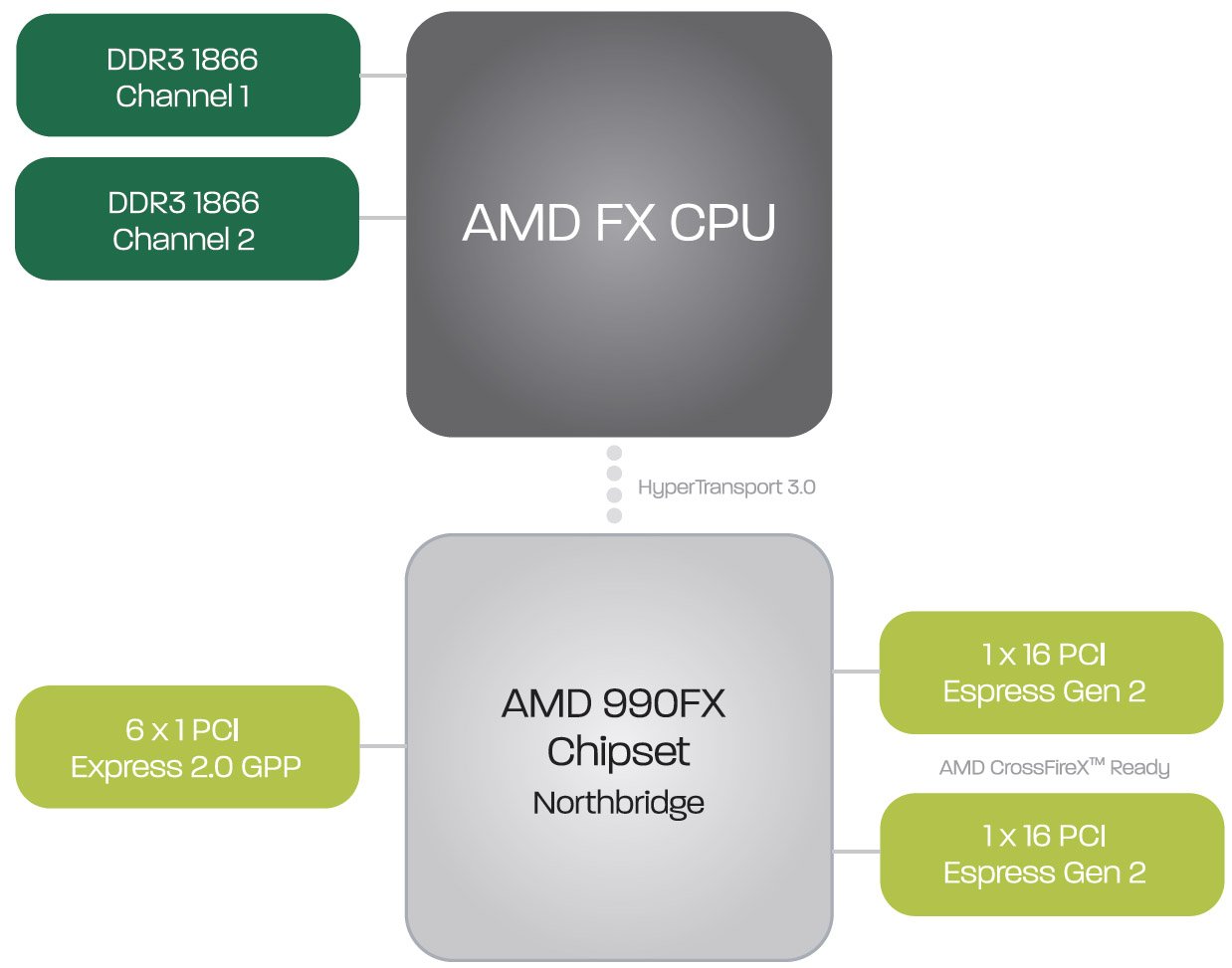
Outre le 990FX, les processeurs FX prennent en charge les chipset 990X et 970. Bien entendu, alors que le 990FX gère jusqu’à quatre cartes graphiques via ses quatre emplacements PCI Express 2.0 8x (ou deux cartes en mode 16x), le 990X vous limite à deux cartes en mode 8x (ou une en mode 16x), tandis que le 970 fait totalement l’impasse sur le CrossFire et ne gère qu’une seule et unique carte graphique en mode 16x.
AMD dispose d’un avantage de taille depuis le rachat d’ATI : étant donné que le fabricant conçoit ses propres processeurs, chipsets et cartes graphiques, il est en mesure de bâtir des plateformes complètes. Il y a deux ans, la société lançait donc la plateforme Dragon, composée des processeurs Phenom II pour socket AM2/AM2+, du chipset 790 et des GPU de la série Radeon HD 4000. L’an dernier, c’était la plateforme Leo, avec ses Phenom II pour socket AM3, les chipsets 890 et les cartes de la gamme Radeon HD 5000. Aujourd’hui, AMD lance la plateforme Scorpius, dont les éléments constitutifs sont les processeurs FX pour socket AM3+, les chipsets de la série 900 et les cartes graphiques Radeon HD 6000.
Du déblocable des cores
Les sept processeurs FX de la famille Zambezi présentés aujourd’hui sont physiquement identiques. Certains contiennent un module Bulldozer désactivé, d’autres deux. À première vue, nous nous retrouvons donc dans la même situation que lorsque nous avons mis la main sur l’AMD Zosma, une puce quad-core que nous avions pu déverrouiller pour la transformer en hexa-core (article en anglais). AMD nous a toutefois affirmé que cela ne serait pas possible cette fois-ci, car le mécanisme qui nous avait permis de débloquer les deux cores supplémentaires semble avoir été cadenassé. Qui plus est, le fabricant a poussé les fréquences des modèles contenant moins de cores ; toute tentative de réactiver les portions « éteintes » de la puce risquerait donc de causer des problèmes de stabilité.
Ceci étant dit, le déblocage des cores n’était pas non plus censé être possible sur les processeurs d’il y a quelques années, et pourtant, nous étions tout de même parvenus à déverrouiller plusieurs Phenom II X3 (article en anglais)… Bref, nous n’abandonnons pas l’idée de faire de même avec les FX, du moins pas tant que les fabricants de cartes-mères ne nous aurons pas confirmé qu’il n’y aucun moyen de transformer un FX-4100 en quelque chose ressemblant à un FX-8150.
Architecture Bulldozer : le concept
Si l’on devait résumer en un mot le concept de l’architecture Bulldozer, ce serait « évolutivité ». AMD a consacré le plus gros de ses efforts à concevoir un « bloc de construction » suffisamment petit pour pouvoir être dupliqué à l’envi, mais suffisamment puissant pour traiter rapidement les opérations sur entiers comme en virgule flottante. La société nous a d’ailleurs confirmé que le projet Bulldozer avait été démarré de zéro il y a plusieurs années, après qu’elle ait réfléchi aux marchés dans lesquels cette architecture allait devoir se faire une place, à savoir à peu près tout : des ordinateurs de bureau aux serveurs haut de gamme.
Dès la phase de conception de l’architecture, AMD s’est rendu compte que les jours des processeurs mono-core étaient révolus. De fait, même les plus basiques des processeurs pour desktop actuels sont des dual-core. Ce n’est donc pas une coïncidence si chaque « module » des processeurs reposant sur l’architecture Bulldozer est capable de gérer simultanément deux threads. À première vue, chaque « core » Bulldozer correspond donc en réalité à deux cores traditionnels. Nous allons toutefois voir que ce n’est pas si simple que cela…
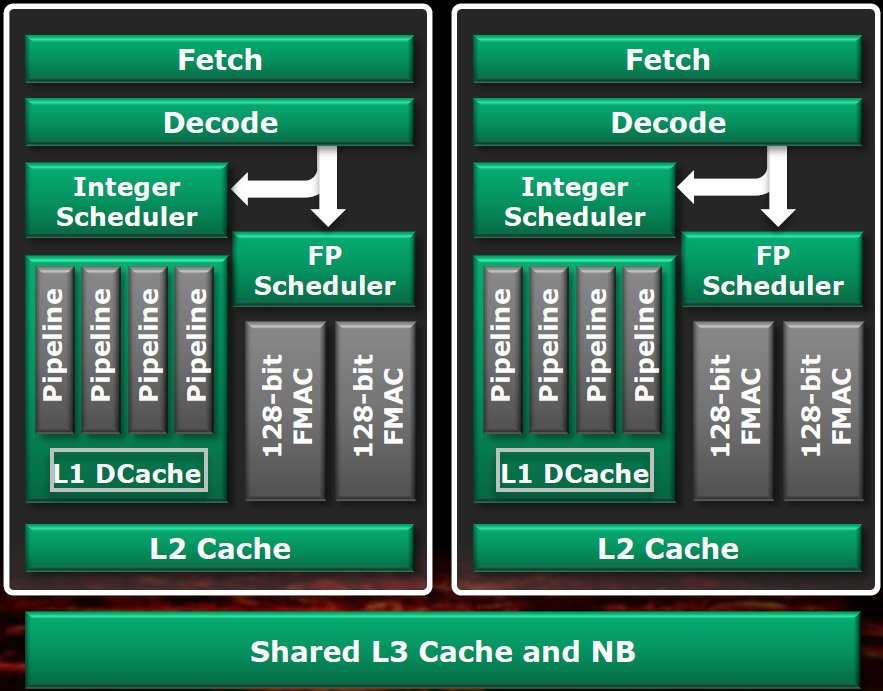
Il existe, bien entendu, diverses manières de gérer le multithreading. À une extrémité, on trouve le multitraitement physique : la méthode « brute » consistant à multiplier le nombre de cores par puce et à distribuer les instructions entre ceux-ci. C’est l’approche la plus efficace dans les applications bien conçues, mais également la plus coûteuse en termes de nombre de transistors.
À l’autre extrémité, on trouve le simultaneous multithreading (SMT), qui consiste à dupliquer les ressources nécessaires pour faire traiter les instructions provenant de plusieurs threads par un seul et même core, et ce, pour « coût » matériel le plus minime possible. Lorsqu’un thread unique ne suffit pas pour utiliser pleinement les ressources d’un core, le SMT prend le relais afin d’exploiter au maximum le core en question. C’est exactement ce que fait l’Hyper-Threading d’Intel. Malheureusement, bien que Windows ne voie pas la différence entre les cores physiques et les cores logiques, le gain de performances se révèle assez modeste dans les applications réelles.
C’est pour cette raison qu’AMD critique fortement l’Hyper-Threading d’Intel et tient à faire la distinction entre cores physiques et logiques. Le fondeur n’a pas tort : nous avons-nous-même constaté qu’un simple petit Phenom II quad-core faisait mieux qu’un Core i3 dual-core avec Hyper-Threading dans les tests de type WinRAR ou 7-Zip.
Qu’est-ce qu’un core ?
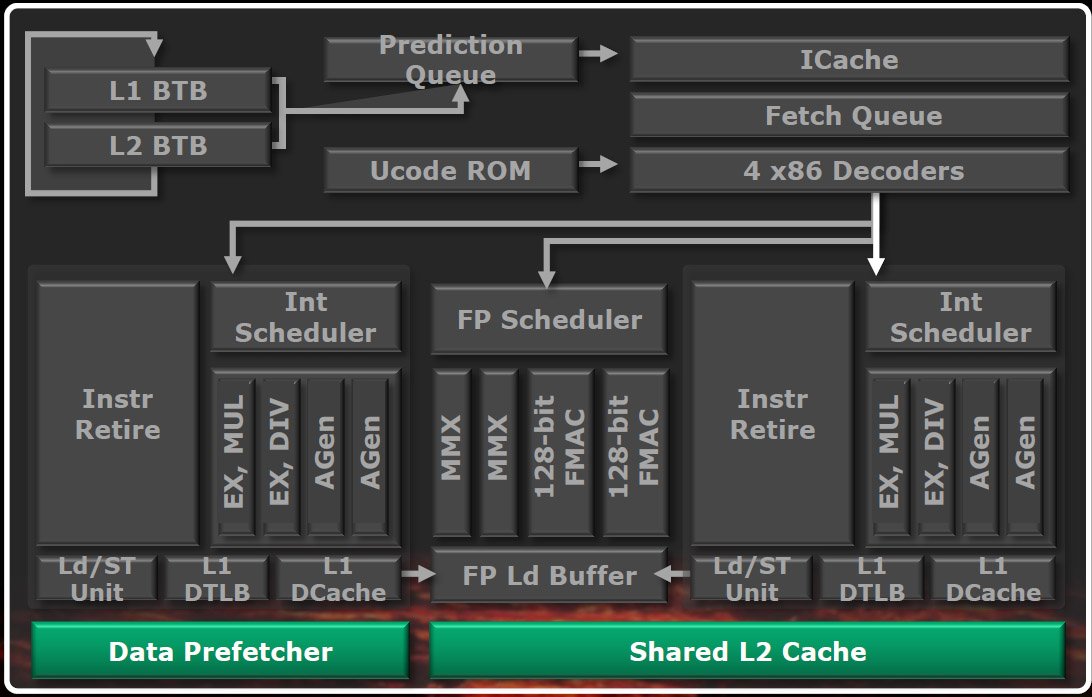
AMD va toutefois devoir cesser faire la morale à Intel, car les modules Bulldozer ne sont pas réellement des puces dual-core à part entière. Certains de leurs composants, normalement dupliqués dans les cores d’exécution traditionnels, sont partagés : les étages de fetching et de décodage des instructions, les unités de traitement des instructions en virgule flottante et le cache L2.
Mike Butler, architecte en chef responsable de Bulldozer, justifie ce choix en expliquant que les cores traditionnels, qui doivent eux aussi fonctionner dans un environnement où l’énergie disponible est comptée, n’exploitent pas leur marge thermique de manière optimale. Cela se comprend tout à fait : pour prendre une analogie, lorsqu’on tente de faire rentrer autant de cores que possibles dans un serveur, on a tendance à favoriser les ressources qui seront les plus susceptibles d’être utilisées et à éviter de consacrer inutilement de l’espace die ou de l’énergie à des composants qu’il est possible de partager sans que cela ait une incidence trop négative sur les performances.
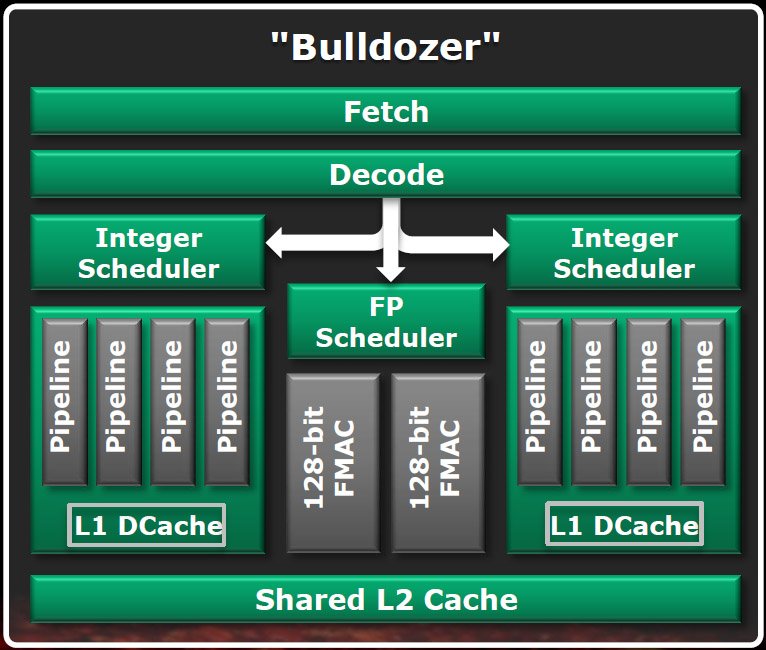
La décision de partager certains composants n’est contre-productive que lorsque les deux threads doivent accéder simultanément aux mêmes ressources physiques, auquel cas les performances retombent effectivement au niveau de celles d’un core traditionnel. AMD est toutefois optimiste : lors de la conférence Hot Chips organisée en août dernier, lorsque la société a commencé à communiquer les premiers détails de son architecture, elle estimait que chaque module Bulldozer afficherait 80 % des performances de deux cores complets, alors que le surcoût en terme de taille de die ne serait que minime par rapport à un core unique. Les processeurs bâtis selon cette architecture devraient donc faire montre de performances très intéressantes dans les environnements fortement multithreadés.
Cela signifie toutefois qu’AMD a dû redéfinir le terme « core ». Pour que la définition puisse englober ses modules Bulldozer, la société indique dorénavant qu’un core correspond à « tout composant possédant ses propres pipelines d’exécution des instructions en nombres entiers » (ce qui n’est guère surprenant, n’est-ce pas ?), ne serait-ce que parce que plupart des charges de travail se font sur des nombres entiers. Cette définition ne nous pose personnellement aucun problème. Il n’en reste pas moins que, si le partage des ressources a une influence négative sur les performances par cycle, AMD n’a pas d’autre choix que de faire monter les fréquences ou d’accentuer le multithreading pour compenser. Un point qui, comme nous le verrons plus tard, a toute son importance.
Apprendre à partager
Bien entendu, les architectes d’AMD ont pris grand soin de tenir compte des contraintes de consommation et d’efficacité lorsqu’ils ont sélectionné les parties du core à partager. Cela se remarque par exemple en cas d’erreur de prédiction d’un branchement : alors que les cores conventionnels doivent complètement vider leur front-end, ce qui constitue un gâchis de bande passante et d’énergie, les modules Bulldozer parviennent à mieux gérer les ressources dont ils disposent (un effet secondaire positif du partage des composants matériels). AMD a également cherché les domaines dans lesquels il était possible de procéder à un partage sans que cela n’ait d’incidence sur le timing des chemins les plus critiques, raison pour laquelle le planificateur des opérations en virgule flottante est partagé : ce composant est en effet considéré comme moins sensible à la latence que les unités de traitement des opérations sur entiers.
Pour le système d’exploitation, chaque module Bulldozer apparaît comme deux cores, à la manière des cores bénéficiant de l’Hyper-Threading chez Intel. AMD est naturellement peu enclin à comparer son architecture à l’Hyper-Threading (ou, de manière plus générale, au SMT) et affirme que son produit monte nettement mieux en performance qu’un core physique unique traitement simultanément deux threads. Une fois encore, nous ne pouvons donner tort au fabricant : on pourrait difficilement qualifier les modules Bulldozer de « mono-core » étant donné que bon nombre de leurs ressources sont, de fait, dupliquées.
Par contre, nous ne pouvons faire l’impasse sur une question épineuse : celle de la relation entre le matériel d’AMD et les logiciels qui vont tourner sur celui-ci. Dans notre article Core i5 et i7 Lynnfield, le coup de maître d’Intel, nous mentionnions certaines optimisations apportées à Windows 7 suite à une collaboration entre Intel et Microsoft, et plus spécifiquement le core parking, une fonction qui permet au système d’exploitation d’envoyer les threads en priorité aux cores physiques avant de faire appel aux cores logiques (« hyper-threadés »).
En théorie, AMD pourrait bénéficier de cette optimisation : si Windows répartissait la charge entre les quatre modules du FX-8150 avant de faire appel au deuxième core de chaque module, il maximiserait les performances lorsqu’y a quatre threads à traiter. Malheureusement, ce n’est pas le cas : selon Arun Kishan, software design engineer chez Microsoft, chaque module est actuellement considéré comme deux cores équivalents. Par conséquent, dans les applications à deux threads, on risque de se retrouver avec un module actif et trois modules au repos ; c’est sans le moindre doute très bon pour la consommation, mais ça l’est théoriquement moins pour les performances. Cela va aussi quelque peu à l’encontre des déclarations d’AMD, qui affirme que, lorsqu’un seul thread est actif, l’ensemble des ressources partagées du module lui sont consacrées : il suffit en effet d’ajouter un seul deuxième thread pour que ces ressources soient (potentiellement) occupées, et ce, alors même que plusieurs autres modules sont inutilisés.
Microsoft compte toutefois faire évoluer le comportement de son système d’exploitation. Arun Kishan estime que les modules dual-cores Bulldozer ont, en termes de performances, des caractéristiques plus proches de celles du SMT que des cores physiques ; la firme de Redmond étudie donc en ce moment la possibilité de les détecter et de les traiter de la même manière que les cores logiques hyper-threadés des processeurs Intel. Une telle adaptation aura des répercussions significatives sur les processeurs AMD FX : il ne fait aucun doute que leurs performances grimperaient, mais leurs modules seraient moins souvent inactifs et se mettraient donc moins souvent en veille, ce qui aurait tendance à augmenter la consommation.
Cela reste toutefois de l’ordre du réglage fin ; pour l’heure, ce sont les performances actuelles qui nous intéressent. En attendant les optimisations de Microsoft, continuons à faire le tour du propriétaire.
Détails de l’architecture (1)
Front-end partagé
Comme nous l’avons déjà signalé, les étages de chargement (fetching) et de décodage des modules Bulldozer sont partagés entre leurs deux cores. AMD utilise une approche de type « multithreading entrelacé » pour suivre à la volée l’identificateur de chaque instruction, décider quel thread a le plus besoin d’être terminé en priorité et effectuer les opérations pour le thread en question. Pour que les deux threads puisse progresser, le module peut changer son fusil d’épaule à chaque cycle.
AMD a découplé le prédicteur de cible de branchement de l’étage de fetching d’instruction, celui-ci lui permet de prendre de l’avance sur ce dernier lorsqu’il se retrouve coincé quelque part. D’après AMD, le découplage de ces composants a surtout l’avantage d’introduire une nouvelle fonctionnalité nommée prediction-directed instruction prefetch, qui se caractérise par une précision et un rendement énergétique très élevés.
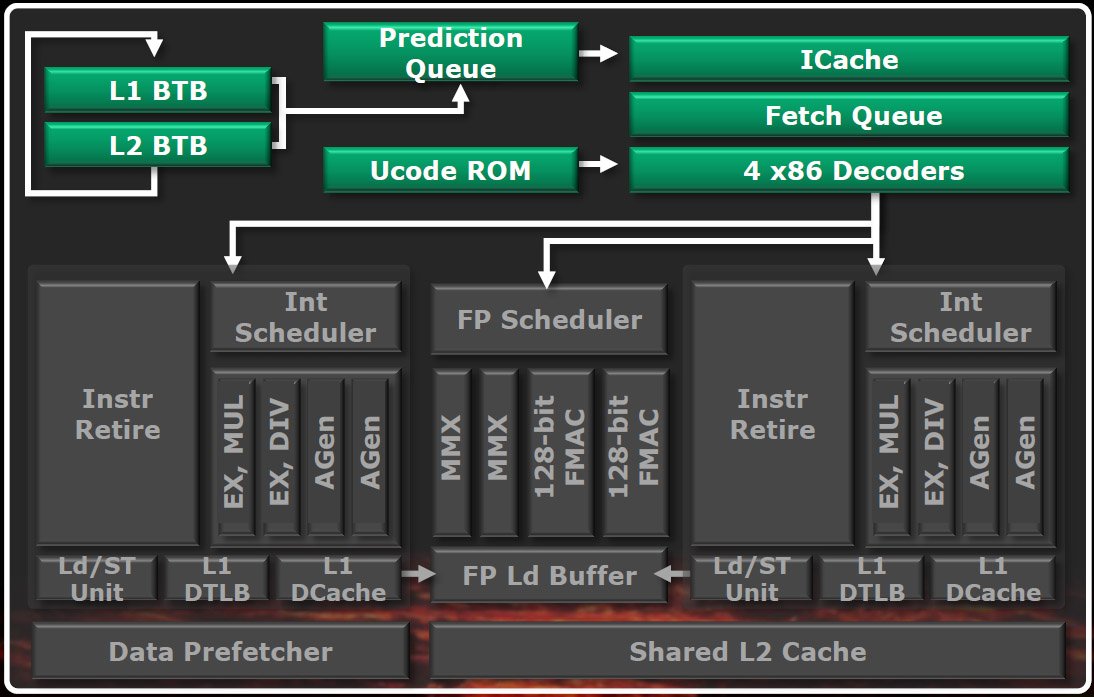
La prédiction de branchement est guidée par des caches de cibles de branchement (dits BTB) L1 (à 512 entrées) et L2 (à 5000 entrées). Ce pipeline est chargé d’effectuer les prévisions nécessaires pour remplir, et maintenir aussi pleines que possible, deux files d’attente (une par thread) contenant les futures adresses à charger (fetch) ; ce sont ces files d’attente qui alimentent ensuite le pipeline de fetching d’instructions.
Les adresses pénètrent alors dans le cache d’instructions bidirectionnel (64 Ko) du pipeline de fetching, cache partagé entre les deux threads, qui se font concurrence de manière dynamique pour y accéder. Vient ensuite la file d’attente de fetching, qui alimente en instructions x86 un pipeline de décodage composé de quatre décodeurs x86 ; ceux-ci, enfin, envoient quatre instructions par cycles aux planificateur (schedulers).
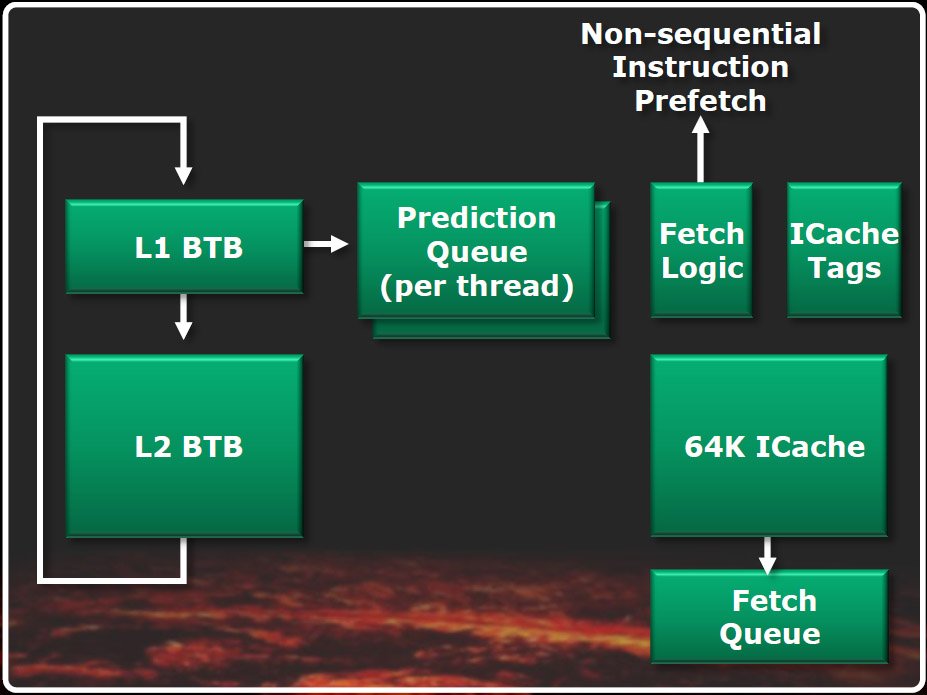
Lorsqu’une erreur de prédiction se produit (l’adresse recherchée n’est pas disponible dans le cache des instructions), une requête est envoyée au cache L2 puis, si nécessaire, transmise à la mémoire système, ce qui introduit évidemment une latence importante. Pendant que la requête est en cours de traitement, les adresses suivantes de la file d’attente sont passées en revue afin de vérifier si elles sont elles aussi absentes du cache. Si c’est le cas, une autre requête est envoyée au cache L2 pendant que la première revient, ce qui permet de gagner du temps.
Deux unités de traitement des entiers
Du front-end, les opérations décodées passent ensuite dans l’un des deux cores de traitement des nombres entiers, où elles sont entièrement exécutées dans le désordre. Chaque core contient deux unités d’exécution et de unités de génération d’adresses.
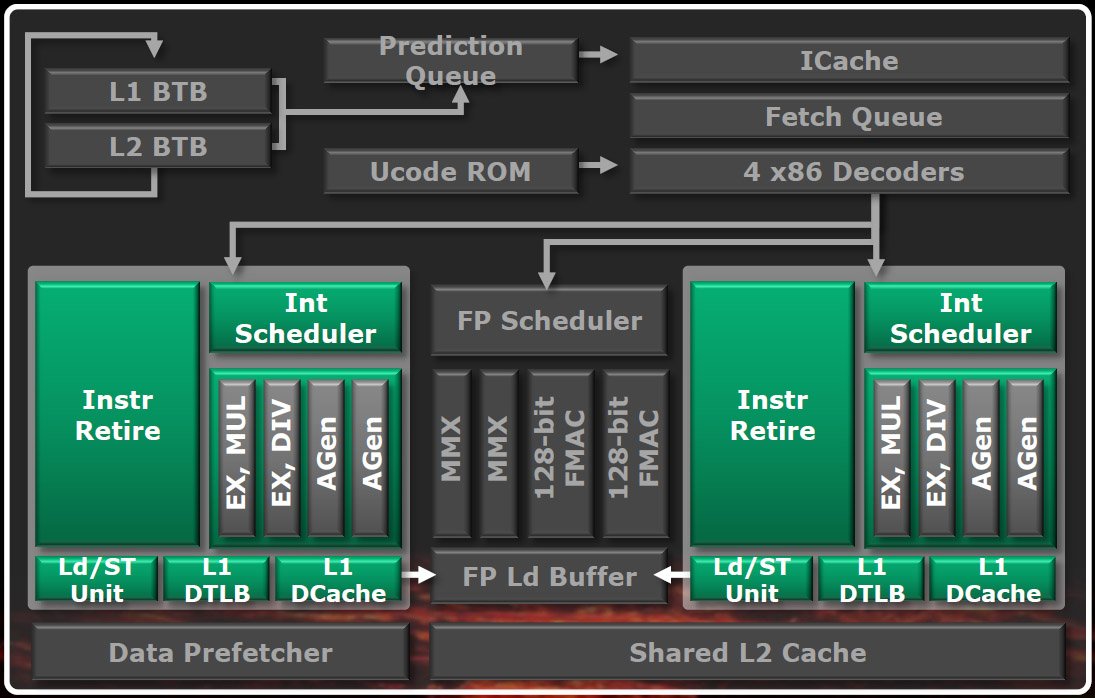
Chaque core est également doté de son propre cache de données L1, à prédiction de voie et d’une taille de 16 Ko, ainsi que de caches de données L1 nommés TLB (data translation lookaside buffers) à 32 entrées ; ils emploient par ailleurs des unités de chargement/stockage out-of-order capables d’effectuer deux opérations de chargement de 128 bits par cycle ou une opération de stockage de 128 bits par cycle ; enfin, les deux cores se partagent également un cache TLB L2 à 1024 entrées et huit voies.
Détails de l’architecture (2)
Deux cores, un FPU
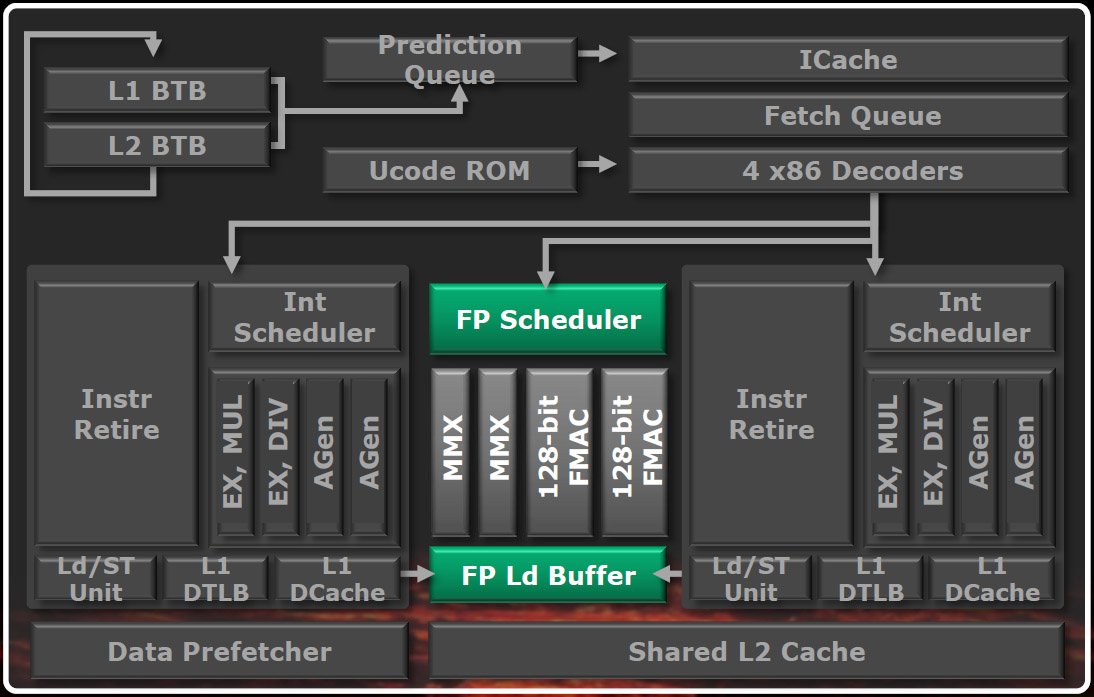
L’unité de calcul en virgule flottante (FPU) est distincte des pipelines de calcul sur nombres entiers. Lorsque les opérations arrivent à l’interface de dispatching, après l’étage de décodage mais avant les unités de calcul sur entiers, toute opération en virgule flottante est envoyée au scheduler du FPU. Une fois arrivées là, elles se font concurrence pour les ressources et la bande passante, et ce, indépendamment du thread auquel elles appartiennent.
Comme vous pouvez le voir sur le diagramme ci-dessous, l’unité de calcul en virgule flottante conçue par AMD est assez différente de la portion s’occupant du calcul sur entiers : elle ne sert qu’à l’exécution, et envoie ses données traitées, ainsi que ses erreurs, au core de traitement de entiers, qui se charge de terminer les instructions.
La FPU comporte deux pipelines MMX ainsi que deux unités FMAC (fused multiply-accumulate) de 128 bits qui gèrent les instructions à quatre opérandes et donnent un résultat non destructif. Intel prévoit d’intégrer le format à trois opérandes dans sa microarchitecture Haswell (celle qui suivra l’Ivy Bridge). AMD compte faire de même dans l’architecture qui succèdera à la Bulldozer, nommée Piledriver, en 2012.
À chaque fois que nous voyons les fabricants prévoir des fonctionnalités divergentes comme c’est le cas ici, nous ne pouvons nous empêcher de nous demander dans quelle mesure cela affectera les développeurs. Nous avons donc demandé à Adrian Silasi de la société SiSoftware ce qui, selon lui, risquait de se produire ; il nous a expliqué que la plupart des développeurs refuseraient de rédiger trois codes différentes (un pour l’AVX uniquement, un pour l’AVX + FMA3 et un pour l’AVX + FMA4), ce qui nous paraît tout à fait logique. Il faut savoir qu’il n’y a aujourd’hui qu’un nombre très restreint d’applications faisant appel à AVX et strictement aucune employant le FMA.
Reste toutefois une question relativement pressante : quelles sont les performances de l’architecture Bulldozer en matière de traitement des instructions AVX, surtout par rapport à celles d’Intel ? Le Sandy Bridge gère deux opérations AVX de 256 bits par cycle alors que le Bulldozer n’en traite qu’une.
En préparation de cet article, nous avons pris contact avec Noel Borthwick, musicien et CTO de Cakewalk, Inc., concernant le travail d’optimisation pour AVX réalisé par sa société sur le logiciel Sonar X1. Selon un document technique co-rédigé par celui-ci, la gestion des instructions AVX permet de réduire la charge de travail effectuée par le logiciel lors de certaines conversions audio (principalement la conversion d’entiers sur 24 bits en 32 bits à virgule flottante ou en 64 bits double précision et la conversion de 32 bits en virgule flottante en 64 bits double précision).
Noel Borthwick nous a donc envoyé une application de test qui compare deux routines optimisées pour l’AVX par Cakewalk à la version non optimisée. Cette application a également été transmise à AMD et Intel ; aucun des deux fabricants n’a donc « d’excuse ».
| Architecture | Opération | Résultat (cycles de traitement gagnés/perdus) |
|---|---|---|
| AMD Bulldozer | Copy Int24toFloat64 | Gain de 69 % |
| AMD Bulldozer | Copy Float32toFloat64 | Perte de 77% |
| Intel Sandy Bridge | Copy Int24toFloat64 | Gain de 61 % |
| Intel Sandy Bridge | Copy Float32toFloat64 | Gain de 14 % |
Lors de l’opération « Copy Int24toFloat64 » (conversion de 24 bits entiers en 64 bits à virgule flottante), l’optimisation pour l’AVX permet à l’Intel Core i7-2600K d’obtenir un gain de 69 % tandis que l’AMD FX-8150 affiche un gain à peine inférieur, de 61 %. Qu’est-ce que ce « gain » ? Il s’agit du nombre de cycles de traitement, et donc de la bande passante, que l’AVX permet de gagner.
Dans l’opération « Copy Float32toFloat64 » (conversion de 32 bits à virgule flottante en 64 bits à virgule flottante), le Core i7-2600K obtient un gain de 14 %, mais le FX-8150 affiche une perte de 77 % ! Il semblerait que les routines de vectorisation de Cakewalk (ou peut-être celles de Microsoft, mais c’est moins probable) ne sont pas optimisées pour l’architecture d’AMD ; il pourrait donc s’avérer nécessaire d’appliquer un correctif à l’application (ou à Visual Studio).
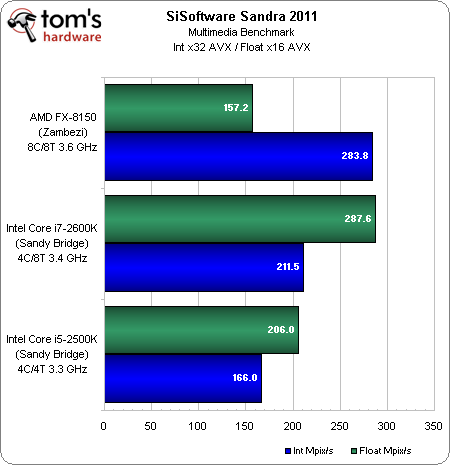
Si l’on passe en revue les résultats sous Sandra 2011, on se rend compte que la gestion de l’AVX affecte positivement les performances du FX-8150 dans le traitement des entiers comme des nombres en virgule flottante. Le Sandy Bridge se montre toutefois bien plus performant dans les calculs en virgule flottante.
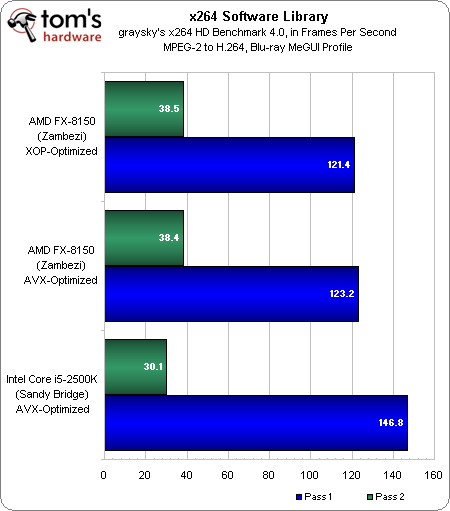
AMD nous a également fait parvenir (à la dernière minute) deux versions de x264, une bibliothèque utilisée par certains logiciels comme HandBrake, optimisées pour les instructions AVX et XOP (une technologie spécifique à AMD).
Nous avons modifié le logiciel de benchmarking Tech ARP x264 HD Benchmark 4.0 afin qu’il fasse appel à ces bibliothèques et l’avons combiné à CPU-Z 1.58 afin d’obtenir les informations concernant le système, puis avons soumis le FX-8150 et un Core i5-2500K à un test AVX.
Que l’on emploie l’AVX ou le XOP, les résultats obtenus par le nouveaux processeur d’AMD sont très similaires. Notons que le processeur Intel parvient à terminer la première passe plus rapidement, mais que l’AMD se montre plus véloce lors de la deuxième.
N’oublions toutefois pas que le nombre de tests optimisés pour l’AVX reste très restreint et qu’il faudra encore énormément de travail de développement avant que nous ne puissions avoir une idée claire de la manière dont la gestion des instructions AVX affecte réellement les deux architectures.
L2 partagé
Nous avons déjà mentionné le cache TLB L2 chargé de traiter les demandes liées aux instructions et aux données. Il existe en plus de celui-ci un autre cache L2 partagé par les deux cores ; ce cache unifié fait une taille de 2 Mo par module Bulldozer, ce qui nous donne donc 8 Mo de cache L2 sur les processeurs de la série FX-8000.
D’après AMD, le prefetcher de données présent sur chaque module accapare une certaine quantité de transistors et d’énergie, mais s’en sort au final plutôt bien car il est partagé par les deux cores.
Performances par core
Il y a une bonne raison pour laquelle, lorsque nous testons un processeur avec des applications réelles, les résultats obtenus sont souvent très différents de ceux des autres tests. Pour bien comprendre, il faut expliquer différemment ce qui fait « les performances » et tenir compte du fait que le potentiel « par core » d’un processeur dépend (1) du nombre d’instructions qu’il peut exécuter par cycle et (2) de sa fréquence (c’est-à-dire le nombre de cycles par seconde).
On détermine le nombre d’instructions par cycle, dans une certaine mesure, en comparant différentes architectures cadencées à la même fréquence à l’aide d’applications conçues pour fonctionner en mode monothreadé. C’est exactement ce que nous avions fait dans notre article intitulé Intel Core 2000 : le test des Sandy Bridge afin de nous faire une idée des améliorations qu’Intel avait apportées en la matière par rapport aux Sandy Bridge.
Les ingénieurs d’AMD nous ont expliqué que, pour l’architecture Bulldozer, l’objectif était d’obtenir un nombre d’instructions par cycle similaire à celui des derniers Phenom II tout en permettant une montée en fréquence nettement plus importante. Cette montée en fréquence ne se traduit toutefois pas vraiment en pratique pour l’instant (les spécifications techniques du FX-8150 étant ce qu’elles sont) ; le nombre d’instructions par cycle et les fréquences étant plus ou moins identiques par rapport à la génération précédente, il ne nous reste donc plus qu’à espérer que les performances en multicore de l’architecture Bulldozer seront plus élevées, sans quoi on voit mal comment elle pourrait faire mieux qu’un Phenom II X4 980 cadencé à 3,7 GHz ou qu’un Phenom II X6 1100T équipé de la fonction Turbo Core.
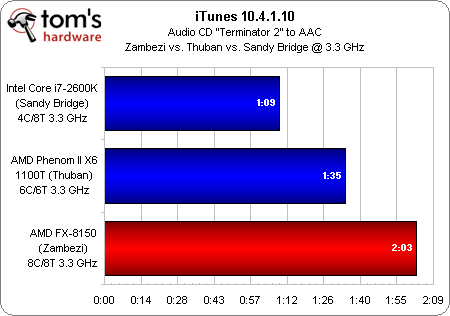
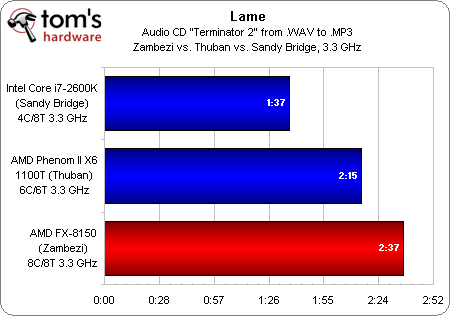
Dans ce test où nous comparons les performances dans iTunes d’un Intel Core i7-2600K (dont les fonctions Hyper-Threading, SpeedStep et Turbo Boost ont été désactivées), d’un Phenom II X6 (Cool’n’Quiet et Turbo Core désactivés) et d’un FX-8150 (Cool’n’Quiet et Turbo Core désactivés) tous cadencés à 3,3 GHz, on voit immédiatement que le Core i7 traite un nombre d’instructions par cycle nettement plus élevé que le Phenom II, lui-même plus rapide que le FX. Le résultat est identique dans Lame, autre application ne gérant pas le multithreading.
John Fruehe, directeur marketing des produits pour serveurs chez AMD, nous a confié qu’il n’appréciait pas la comparaison des performances par core dans le domaine des serveurs, car elle est intrinsèquement plus favorable à Intel. Nous sommes tout à fait d’accord sur ce point : dans le monde des serveurs, les rapports performances/watt et performances/prix sont bien plus importants que le rapport performances/core. Sur les ordinateurs de bureau, par contre, il existe encore suffisamment d’application monothreadées ou peu multithreadées pour que les performances par core conservent leur importance, d’autant plus quand on note dans ce domaine un recul d’une génération à l’autre.
Nous avons donc d’ores et déjà une idée de ce qui risque de poser problème à l’architecture Bulldozer.
Gestion de la consommation
Chaque module Bulldozer est cadencé indépendamment des autres, ce qui signifie qu’on peut se retrouver avec un processeur dont les cores fonctionnent à des fréquences différentes. Cette fonctionnalité est une nouveauté par rapport au Phenom II, dont tous les cores fonctionnaient à la même fréquence (même s’il pouvaient effectivement avoir des p-states, c’est-à-dire des états de veille, différents), mais pas par rapport aux premiers Phenom.
Vous vous souviendrez peut-être que ces différences de fréquences provoquaient à l’époque des problèmes sous Windows Vista lorsque la fonction Cool’n’Quiet était activée : le système d’exploitation tentait de maintenir la symétrie entre cores et faisait donc « sauter » les threads d’un core à l’autre. Pour quoi faire ? Comme nous l’écrivions dans notre article consacré au lancement des Intel Lynnfield :
Pour maintenir la symétrie d’un système à pleine charge, il faut éviter que les requêtes d’entrées/sorties soient concentrées sur un seul cœur. Si l’on fait sauter les threads d’un cœur à l’autre, on gagne en rapidité. Mais ce beau concept vole en éclats lorsque les cœurs inactifs sont mis en semi veille
Cette technologie fut mise au point au cours de la conception du noyau Windows NT, et d’après nos expériences avec les composants d’Intel ou AMD, elle n’était pas considérée comme un atout pour les deux fondeurs. Bien sûr, Intel n’était pas touché de la même manière qu’AMD. Le problème d’Intel avec Vista était la consommation électrique. À chaque migration d’un thread d’un cœur à l’autre, il faut par exemple réécrire le cache L3 d’un processeur Nehalem, ce qui consomme de l’énergie.
Cette situation change avec Windows 7, et une fonction appelée « cœur idéal » (ideal core). Si une tâche de calcul est exécutée par un cœur, le système d’exploitation la laissera là. Cela a deux conséquences pour Intel : d’abord, on ne perd pas d’énergie à migrer le processus, d’autre part, les cœurs inactifs peuvent descendre dans leur état de veille le plus profond, le C6. A priori, ces économies d’énergie devrait permettre de gagner 10 à 15 minutes d’autonomie sur les PC portables équipés de processeurs Nehalem (qui resteront une chimère jusqu’au lancement des CPU Arrandale plus tard cette année). Le corollaire est que les processeurs incapables de descendre en état C6 (et donc les processeurs AMD) ne montreront pas les mêmes gains.
Donc, si les Phenom étaient un peu en avance sur leur temps à cause du scheduler de Windows Vista, il n’en va plus de même des FX sous Windows 7, qui devrait les gérer de manière plus élégante. Au-delà de ce constat, Larry Hewitt, Chief SoC Engineer responsable des processeurs Zambezi, Interlagos et Valencia, affirme que les processeurs reposant sur l’architecture Bulldozer mettent moins de temps à sortir de leur état de veille minimal que les Phenom.
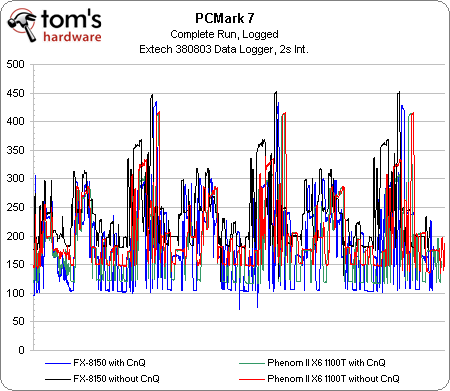
Tout naturellement, nous avons voulu vérifier cette affirmation. Cela ne se voit pas sur le graphique ci-dessus, mais le Phenom II, qui résolvait le problème de migration des threads du Phenom en faisant fonctionner tous ses cores à la même fréquence, ne souffre d’aucun écart de performances sous PCMark 7 lorsque Cool’n’Quiet est activé, ce qui était l’objectif visé. Il en vaut de même pour le FX-8150, ce qui tend à confirmer que les Zambezi et Windows 7 se comportent correctement. L’élément le plus intéressant reste toutefois l’efficacité des optimisations qu’AMD a apportées à l’architecture Bulldozer en termes de consommation. Les lignes bleu et verte sont respectivement celles du FX et du Phenom II X6 lorsque le CnQ est activé. Les lignes noire et rouge sont les mêmes puces avec le CnQ désactivé.
En moyenne, le Phenom II X6 consomme 191 watts avec CnQ et 204 watts sans, soit un écart de 13 watts. Le FX-8150, quant à lui, consomme également 191 watts avec CnQ, mais grimpe à 240 watts lorsqu’il est désactivé. En moyenne, Cool’n’Quiet réduit donc la consommation du système de 49 watts durant notre test, sans affecter les performances !
L’ensemble northbridge / cache L3 est lui aussi cadencé indépendamment du reste du processeur ; il est également alimentés indépendamment. Il semble donc qu’AMD fasse énormément appel au power gating (une fonction lancée par Intel pour ses processeurs Nehalem mais qu’AMD vient seulement d’adopter pour ses APU Llano) pour minimiser les fuites de courant lorsque certaines portions de la puce ne sont pas utilisées.
Comme les Llano, les Zambezi/Interlagos/Valencia prennent enfin en charge l’état de veille C6 par core : lorsque celui-ci est activé, le module Bulldozer concerné voit son cache vidé, son contenu exporté vers la mémoire système et sa tension mise à zéro, ce qui fait donc chuter la consommation et la dissipation thermique du processeur.
La prise en charge de l’état de veille C1E n’est pas une nouveauté chez AMD, mais elle a été améliorée, dans la mesure où tous les modules Bulldozer peuvent être cloisonnés en termes d’alimentation lorsque le northbridge, les liens HyperTransport et la DRAM passent en mode très basse tension.
Le Turbo Core remanié
AMD a introduit une fonction nommée Turbo Core lors du lancement du Phenom II X6 1090T. Réponse au Turbo Boost d’Intel, elle devait permettre au fondeur de profiter de la marge thermique disponible dans les charges de travail peu multithreadées en provoquant une augmentation de la fréquence lorsque certains cores étaient inactifs.
Comme vous le savez peut-être le Turbo Boost d’Intel fait appel à un contrôleur d’alimentation intégré au die qui évalue la température, le courant, la consommation et l’état du système d’exploitation et, en fonction de toutes ces informations, décide de désactiver les cores inactifs afin de dégager une marge thermique permettant d’accélérer les autres. Le degré d’accélération dépend du nombre de cores utilisés : bien entendu, il est plus facile de monter en fréquence dans les applications monothreadées. Petit exemple une fois encore extrait de notre article Core i5 et i7 Lynnfield, le coup de maître d’Intel :
| Turbo Boost : nombre de paliers d’accélération disponibles en fonction du nombre de cores utilisés | |||||
|---|---|---|---|---|---|
| Processeur | Fréquence | 4 cores actifs | 3 cores actifs | 2 cores actifs | 1 core actif |
| Core i7-870 | 2.93 GHz | 2 | 2 | 4 | 5 |
| Core i7-860 | 2.8 GHz | 1 | 1 | 4 | 5 |
| Core i5-750 | 2.66 GHz | 1 | 1 | 4 | 4 |
| Core i7-975 | 3.33 GHz | 1 | 1 | 1 | 2 |
| Core i7-950 | 3.06 GHz | 1 | 1 | 1 | 2 |
| Core i7-920 | 2.66 GHz | 1 | 1 | 1 | 2 |
À titre de comparaison, le Turbo Core d’AMD était présenté comme une fonction nettement dirigiste, qui s’activait dans les charges de travail faiblement threadées (trois cores actifs ou moins) et se désactivait totalement dès qu’une application utilisait plus de trois cores. La pratique, cependant, ne s’est pas révélée aussi « manichéenne » : d’après ce que nous avions pu constater dans notre article AMD Phenom II X6 & 890FX : l’hexacore abordable, les différents changeaient en permanence de fréquence sans jamais vraiment atteindre la fréquence maximale annoncée. Les gains de performances attribuables au Turbo Core étaient donc plus modestes que ceux auxquels nous nous attendions.
Fort heureusement pour l’architecture Bulldozer AMD annonce avoir apporté à cette technologie quelques modifications qui devraient la rendre plus efficace que sur les processeur de la famille Thuban.
AMD FX : un Turbo Core légèrement différent
La fonction APM (Application Power Management) est la capacité des processeurs Zambezi/Interlagos/Valencia à surveiller en temps réel la consommation de chacun de leurs cores. Plutôt que de mesurer la chaleur émise ou le courant pompé, AMD a choisi de surveiller l’activité de chaque module. Le fondeur sait combien d’énergie nécessite chaque opération et parvient donc à déterminer instantanément la consommation de chaque module. Une rapide comparaison entre la consommation réelle et le TDP indique alors s’il y a de la marge disponible pour augmenter les performances. Si, par exemple, vous faites tourner une application qui n’exploite pas pleinement les ressources du processeur, le Turbo Core oscille entre la fréquence de base et une fréquence plus élevée afin d’obtenir, en moyenne, de meilleures performances sans jamais dépasser le TDP.

Le Turbo Core ne se limite pas à la fréquence de base et une fréquence supérieure arbitraire : les modules Bulldozer disposent maintenant de trois p-states différents, à savoir la base (P2), un état intermédiaire (P1) et un état plus élevé (P0). L’amélioration est de taille car la première version du Turbo Core ne possédait que deux p-states différents, mais surtout parce qu’il est désormais possible de passer en P1 lorsque les huit cores sont actifs, pour autant que la marge thermique nécessaire soit disponible. Le passage en P0 nécessite quant à lui qu’au moins deux des quatre modules soient au repos. Notons enfin qu’AMD autorise un dépassement momentané (extrêmement bref) du TDP, mais évidemment jamais dans la durée.
Par conséquent, si vous examinez les spécifications techniques des processeurs FX, vous verrez trois fréquences : la fréquence de base, la fréquence Turbo Core et la fréquence Turbo Core maximale. La fréquence de base est dorénavant le minimum garanti (en charge, bien sûr) ; la fréquence Turbo Core sera activée pour autant que la dissipation thermique soit inférieure au TDP ; et la fréquence Turbo Core maximale le sera lorsqu’au moins la moitié des cores sera au repos.
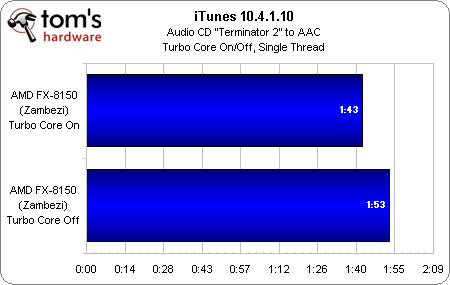
Le premier graphique illustre l’incidence du Turbo Core sur iTunes, une application monothreadées. Étant donné que sept de ses huit cores sont au repos, le FX-8150 fait monter sa fréquence à 4,2 GHz ; bien qu’il ne s’y maintienne pas en permanence et qu’il oscille en réalité entre les états P1 et P0 (soit 3,9 et 4,2 GHz), cela lui permet tout de même de terminer avec 10 secondes d’avance sur le même processeur avec le Turbo Core désactivé.
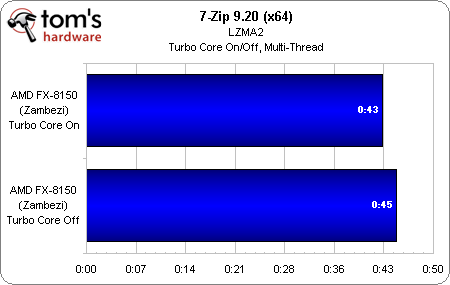
Le second graphique illustre quant à lui les performances dans 7-Zip, une application plus multithreadée et donc capable de faire appel à l’ensemble des cores du FX-8150. Une fois encore, celui-ci ne se maintient pas en permanence à 3,9 GHz, mais oscille entre 3,6 et 3,9 GHz. Le gain obtenu grâce au Turbo Core est donc relativement modeste, mais il ne faut pas oublier qu’il n’aurait pas été présent du tout avec la première version de la fonction, qui était pour rappel limitée à deux p-states.
Feuille de route AMD 2011-2014
Au vu de ce que les Bulldozer ont à offrir aujourd’hui, il apparaît comme une évidence qu’AMD est encore loin d’avoir atteint les objectifs fixés pour cette architecture. La société affirme toutefois être en mesure de produire une nouvelle version du module Bulldozer tous les ans.
Rien à voir donc avec la cadence de production d’Intel, qui procède à une révision de son architecture une année, puis passe à une gravure plus fine l’année suivante, etc. AMD prévoit d’accroître les performances de ses cores de 10 à 15 % par révision en augmentant le nombre d’instructions par cycle, le timing et la fréquence et en améliorant la consommation.

En 2012, le fondeur compte lancer l’architecture Piledriver, qui devrait accroître le nombre d’instructions par cycle et apporter des améliorations en termes de gestion de l’alimentation. Le premier produit devant en profiter sera l’APU Trinity, que nous avons déjà pu voir fonctionner lors du salon IDF. Viendront ensuite les processeurs pour ordinateurs de bureau gravés en 32 nm qui succèderont aux Zambezi actuels. D’où viendront les 10 à 15 % d’accélération ? Selon AMD, environ un tiers de ce chiffre proviendra d’une augmentation du nombre d’instructions traitées par cycle tandis que les deux tiers restant seront générés par des optimisations visant à réduire la consommation et donc à augmenter la fréquence sans changer le TDP.
AMD n’en dit pas plus sur la manière dont il compte procéder pour maintenir ces 10 à 15 % d’accélération dans les architectures Steamroller ou Excavator (qui suivront Piledriver) et se contente d’affirmer que le potentiel est bien là.
AMD Zambezi, Valencia et Interlagos
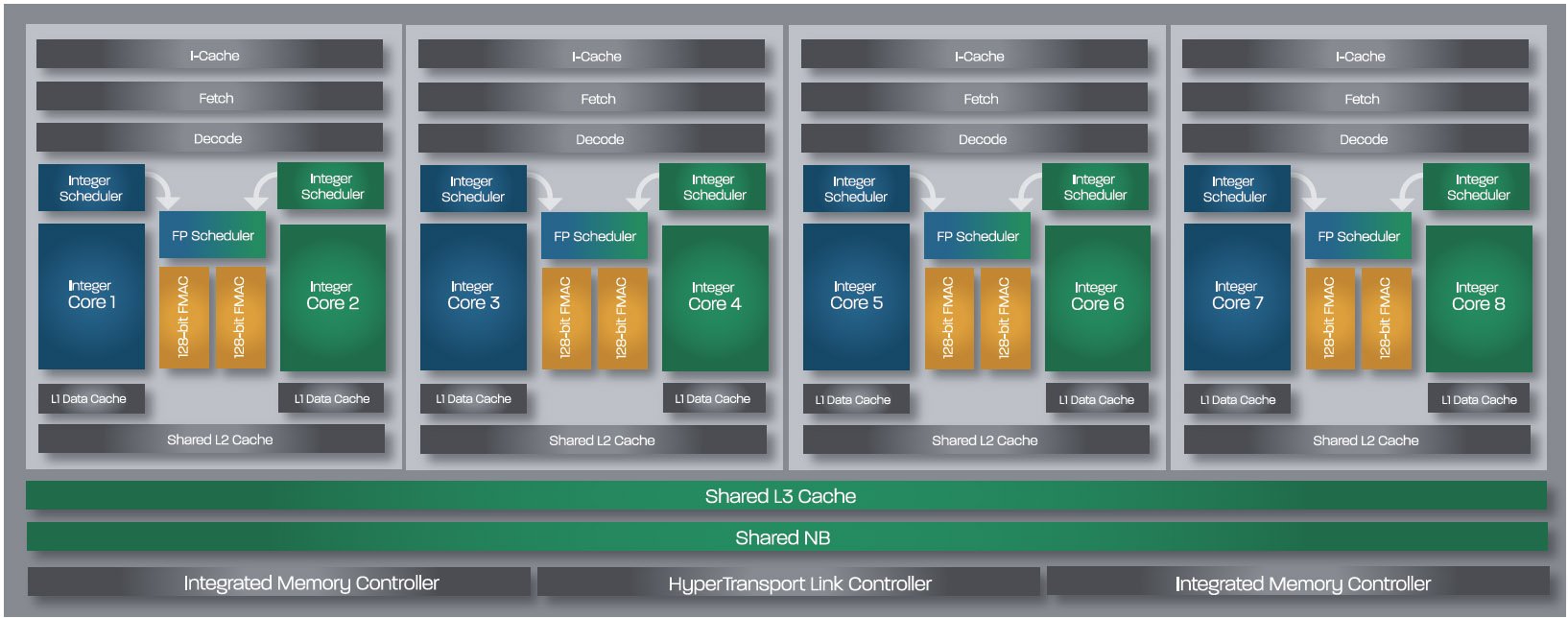
AMD emploie le même die pour tous les nouveaux processeurs basés sur l’architecture Bulldozer, qu’ils visent le marché du desktop (Zambezi), des serveurs à un ou deux processeurs (Valencia) ou des serveurs à un à quatre processeurs (Interlagos). Cette approche n’a bien entendu rien de neuf ni de surprenant : AMD et Intel commercialisent couramment des puces similaires sur plusieurs marchés différents.
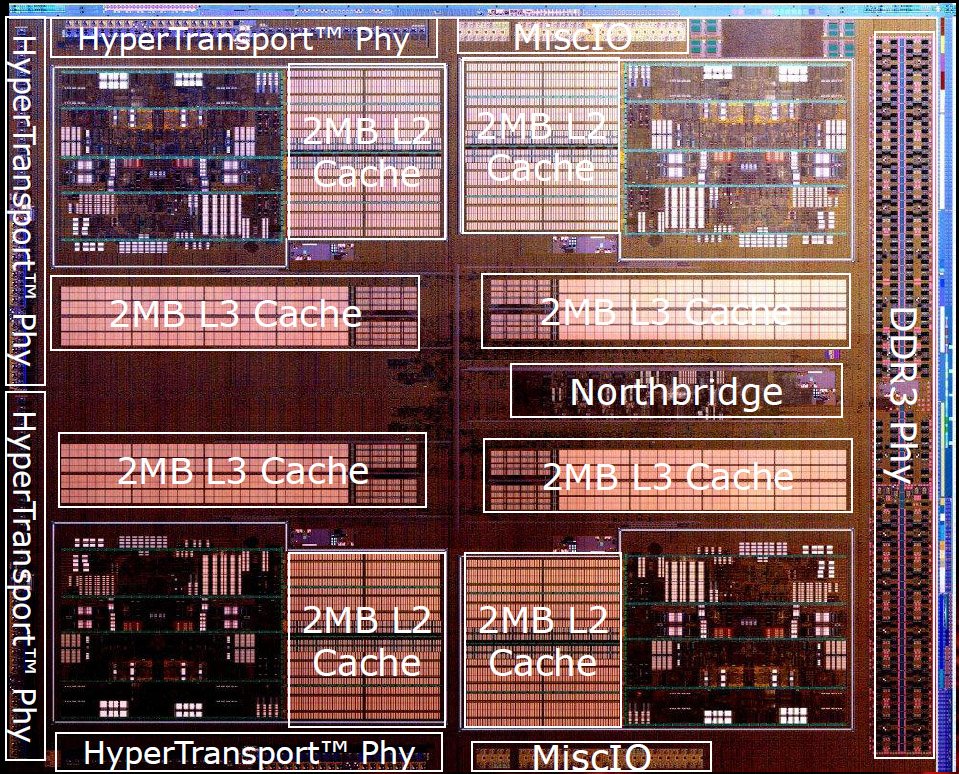
Cette première incarnation de la nouvelle microarchitecture d’AMD contient quatre modules Bulldozer et donc huit cores. Les caractéristiques de la puce sont donc faciles à déterminer : 128 Ko de cache L1 pour les données (16 Ko par core x 8), 256 Ko de cache L1 pour les instructions (64 Ko par module x 4) et 8 Mo de cache L2 (2 Mo par module x 4).
Le die comporte également 8 Mo de cache L3 partagé (quatre tranches de mémoire de 2 Mo chacune). Il est totalement inhabituel de voir un cache L3 de la même taille que le cache L2, mais selon AMD, cette structure résulte d’analyses qui ont indiqué qu’il s’agissait du rapport optimal. Le fondeur indique par ailleurs que le cache L3 n’a qu’une influence minime dans les configurations de bureau ; sa présence se ressent plus dans les serveurs.
Remontons d’une génération : le Phenom II contenait 512 Ko de cache L2 par core et un cache L3 partagé de 6 Mo. Les Sandy Bridge comptent 256 Ko de cache L2 par core et jusqu’à 8 Mo de cache L3 Cette hiérarchie en pyramide est généralement considérée comme idéale pour alimenter chaque niveau aussi rapidement que possible ; en dépit des assurances d’AMD, l’organisation des caches du Bulldozer semble donc intuitivement mauvaise.
Il y a toutefois une différence de taille entre le cache L3 du Bulldozer et celui du Sandy Bridge : le premier est exclusif alors que le second est inclusif. Cela signifie que, sur le Bulldozer, les données ne doivent pas se trouver simultanément dans le L2 et dans le L3 ; les caches des processeurs AMD FX sont donc à même de stocker plus d’informations. Les données se trouvant dans le L3 sont tout simplement plus éloignées des cores.
Pris en sandwich entre deux tranches de cache L3, on trouve le northbridge intégré, qui gère les communications entre le cache L3, les deux canaux de 72 bits de mémoire DDR3 et les liaisons HyperTransport 16 bits, au nombre de quatre maximum. En version pour ordinateur de bureau, le northbridge est cadencé à 2,2 GHz maximum ; les versions pour serveurs le seront à 2,0 et 2,2 GHz.
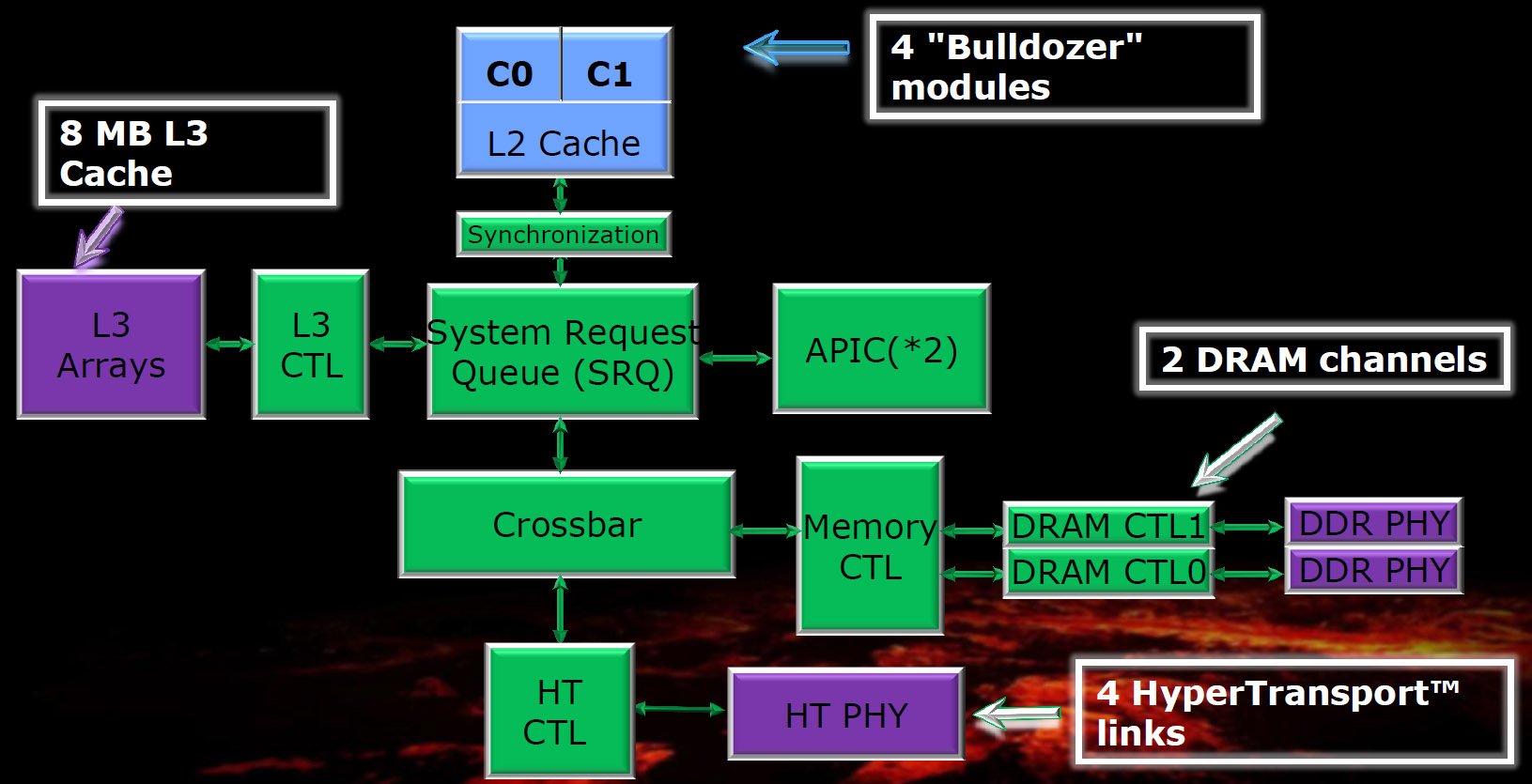
Comme on le voit sur le diagramme ci-dessus, la System Request Queue et le Crossbar du northbridge reçoivent les transactions d’un module Bulldozer, vérifient le cache L3, les dirigent vers le contrôleur mémoire puis renvoient les données au module qui les a demandées. Outre ces sous-systèmes, le northbridge gère les transactions provenant du chipset et, dans les configuration à plusieurs processeurs, des autres sockets.
Zambezi
Tous les processeurs de bureau basés sur l’architecture Bulldozer actuellement disponibles sont des Zambezi. Ces puces sont prévues pour le socle AM3+ (mais pas pour l’AM3), qui ajoute quelques optimisations liées à l’alimentation du processeur et un courant plus élevé pour les liaisons HyperTransport (qui sont donc plus rapides) ainsi que pour la mémoire à plus haute vitesse.
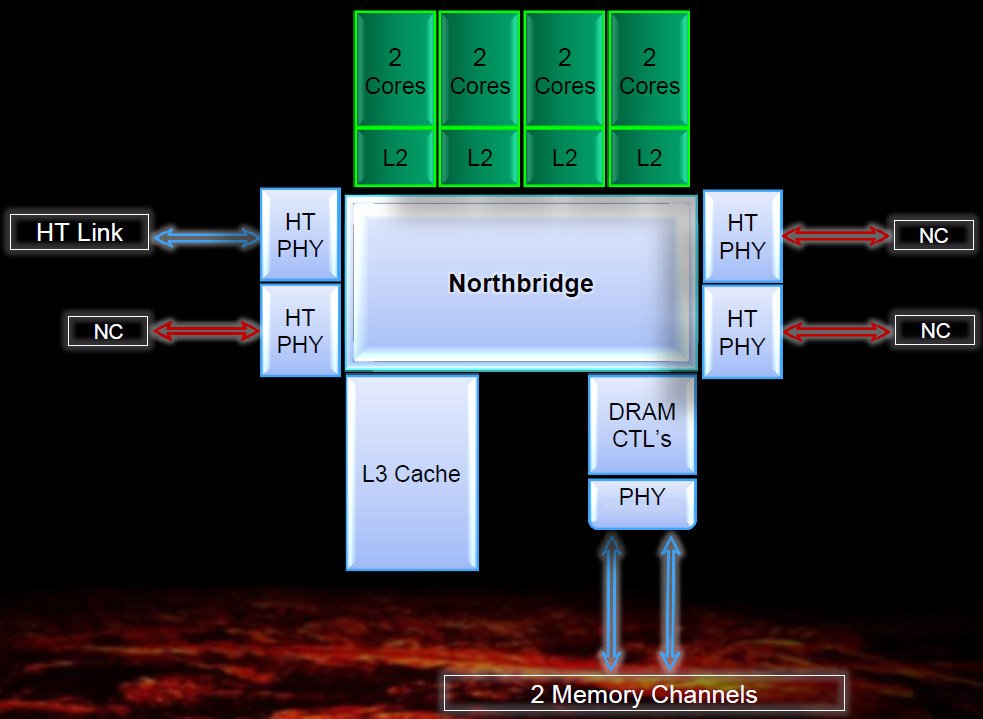
Concernant la mémoire, justement, les Zambezi gèrent deux canaux de DDR3-1866, alors que les processeurs de la génération précédente plafonnaient à la DDR3-1333. Même chose pour l’HyperTransport, qui passe de 2 GHz (4 GT/s) à 2,6 GHz (5,2 GT/s).
Valencia
Les processeurs Valencia sont destinés aux serveurs à un ou deux processeurs. Leur die est exactement identique à celui des Zambezi ; seule leur infrastructure diffère.
Ils remplacent les Opteron 4000 Lisbon, gravés en 45 nm ; comme ceux-ci, ils se branchent sur un socket C32. Seule une mise à jour du BIOS est nécessaire pour les prendre en charge.
Comme les Zambezi, les Valencia gèrent deux canaux de mémoire, mais étant orientés « entreprises », ils sont compatibles avec les barrettes de type Unregistered DIMM, Registered DIMM et Load-Reduced DIMM en DDR3-1600. Leurs liaisons HyperTransport sont quant à elles plus rapides (6,4 GT/s) afin de mieux gérer les communications entre sockets.
Interlagos
Bien que la plupart des documents de référence considèrent les Interlagos comme des processeurs à 16 cores, il s’agit en réalité de packages à deux dies conçus pour les serveurs comptant un à quatre sockets. À l’intérieur de ce package, on trouve deux modules Bulldozer reliés entre eux par une liaison HyperTransport et communicant avec l’extérieur par quatre autres cadencées à 6,4 GT/s.
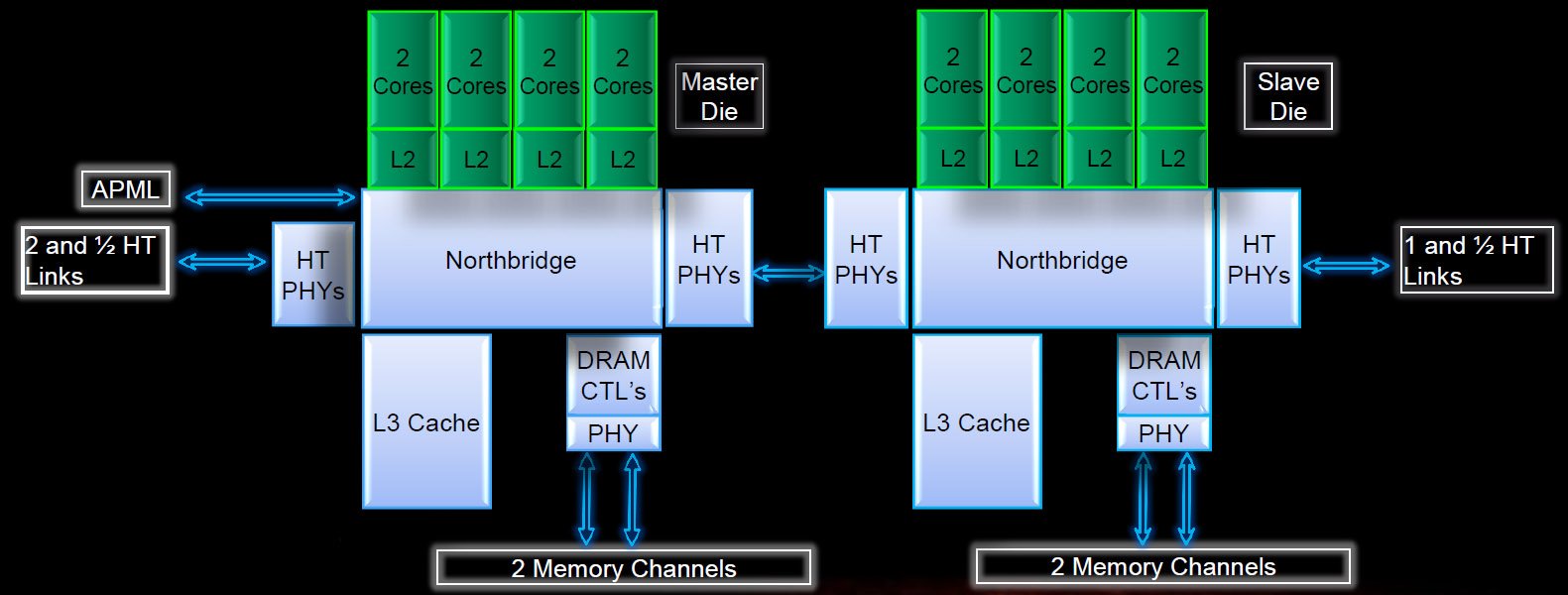
Combinés, ces deux dies offrent donc jusqu’à 16 Mo de cache L2 et autant de L3 ainsi que quatre canaux de mémoire gérant les barrettes Unregistered DIMM, Registered DIMM et Load-Reduced DIMM en DDR3-1866.
Ils remplacent les Opteron 6000 Magny-Cours gravés en 45 nm et, comme eux, se branchent sur un socket G34. Leur prise en charge ne nécessite qu’une mise à jour du BIOS.
Configuration de test et benchmarks
| Configuration de test | |
|---|---|
| Processeurs | AMD FX-8150 (Zambezi) 3,6 GHz (18 x 200 MHz), socket AM3+, 8 Mo de cache L3 partagé, Turbo Core activé, fonctions d’économie d’énergie activées |
| AMD Phenom II X4 980 Black Edition (Deneb) 3,7 GHz (18,5 x 200 MHz), socket AM3, 6 Mo de cache L3 partagé, fonctions d’économie d’énergie activées | |
| AMD Phenom II X6 1100T (Thuban) 3,3 GHz (16,5 x 200 MHz), socket AM3, 6 Mo de cache L3 partagé, Turbo Core activé, fonctions d’économie d’énergie activées | |
| Intel Core i7-2600K (Sandy Bridge) 3,4 GHz (34 x 100 MHz), LGA 1155, 8 Mo de cache L3 partagé, Hyper-Threading activé, Turbo Boost activé, fonctions d’économie d’énergie activées | |
| Intel Core i5-2500K (Sandy Bridge) 3,3 GHz (33 x 100 MHz), LGA 1155, 6 Mo de cache L3, Turbo Boost activé, fonctions d’économie d’énergie activées | |
| Intel Core i7-920 (Bloomfield) 2,66 GHz (20 x 133 MHz), LGA 1366, 8 Mo de cache L3 partagé, Hyper-Threading activé, Turbo Boost activé, fonctions d’économie d’énergie activées | |
| Cartes-mères | Asus Crosshair V Formula (socket AM3+), chipset AMD 990FX/SB950, BIOS 0813 |
| Asus Rampage III Formula (LGA 1366) Intel X58 Express, BIOS 0505 | |
| Asus Maximus IV Extreme (LGA 1155) Intel P67 Express, BIOS 0901 | |
| Mémoire | 16 Go (2 x 8 Go) de DDR3-1333 Crucial, MT16JTF1G64AZ-1G4D1 @ DDR3-1600 et DDR3-1333, tension de 1,65 V sur socket AM3+ et LGA 1155 |
| 24 Go (3 x 8 Go) de DDR3-1333 Crucial, MT16JTF1G64AZ-1G4D1 @ DDR3-1066, tension de 1,65 V sur socket LGA 1366 | |
| Support de stockage | Intel SSD 510 250 Go, SATA 6 Gbit/s |
| Carte graphique | Nvidia GeForce GTX 580 1,5 Go |
| Alimentation | Cooler Master UCP-1000 watts |
| OS et pilotes | |
| OS | Windows 7 Édition Intégrale 64 bits |
| DirectX | DirectX 11 |
| Pilote graphique | Nvidia GeForce 280.26 |
| Jeux 3D : benchmarks et paramètres | |
|---|---|
| Benchmark | Détails |
| Crysis 2 | Paramètres du jeu : paramètres de qualité « Ultra », anti-aliasing désactivé, synchronisation verticale désactivée, textures haute qualité activées, DirectX 9 et DirectX 11, 1680×1050, 1920×1200, 2560×1600, démo : « Central Park » |
| F1 2011 | Paramètres du jeu : paramètres de qualité « Ultra », antialiasing désactivé/8x, AF désactivé, synchronisation verticale désactivée, 1680×1050, 1920×1080, 2560×1600, démo Tom’s Hardware personnalisée |
| World of Warcraft: Cataclysm | Paramètres du jeu : paramètres de qualité « Ultra », antialiasing 1x/8x, AF 16x, synchronisation verticale désactivée, 1680×1050, 1920×1080, 2560×1600, démo : trajet en vol de Crushblow à Krazzworks, DirectX 11 |
| Audio : benchmarks et paramètres | |
| Benchmark | Détails |
| iTunes | Version : 10.4.10 64 bits CD audio (Terminator II SE), 53 min, conversion au format AAC |
| Lame MP3 | Version : 3.98.3 CD audio (Terminator II SE), 53 min, conversion wav en mp3, commande : -b 160 –nores (160 kbps) |
| Vidéo : benchmarks et paramètres | |
| Benchmark | Détails |
| HandBrake CLI | Version : 0.95 Source vidéo : Big Buck Bunny (720×480, 23 972 images) 5 minutes Source audio : Dolby Digital, 48 000 Hz, 6 canaux, anglais Cible vidéo : AVC ; cible audio : AC3, cible audio 2 : AAC (High Profile) |
| MainConcept Reference v2.2 | Version : 2.2.0.5440 Vidéo : MPEG-2 vers H.264, codec MainConcept H.264/AVC, 28 s de HDTV 1920×1080 (MPEG-2) Audio : MPEG-2 (44,1 kHz, 2 canaux, 16 bits, 224 kbps) Codec : H.264 Pro, Mode : PAL 50i (25 images/s), Profil : H.264 BD HDMV |
| x264 Software Library | Versions fournies par AMD, optimisées pour AVX et XOP ; TechARP’s x264 HD Benchmark 4.0, modifié pour prendre en charge les nouvelles versions de x264 et CPU-Z 1.58 |
| Applications : benchmarks et paramètres | |
| Benchmark | Détails |
| WinRAR | Version 4.01 RAR, syntaxe “winrar a -r -m3”, benchmark : 2010-THG-Workload |
| WinZip 14 | Version 14.0 Pro (8652) WinZIP ligne de commande version 3, ZIPX, syntaxe “-a -ez -p -r”, benchmark : 2010-THG-Workload |
| 7-Zip | Version 9.20 (x64) LZMA2, syntaxe “a -t7z -r -m0=LZMA2 -mx=5”, benchmark : 2010-THG-Workload |
| Adobe Premiere Pro CS 5.5 | Séquence « Paladin » sur Blu-ray H.264 Sortie : 1920×1080, qualité maximale, moteur de lecture Mercury en mode matériel |
| Adobe After Effects CS 5.5 | Création d’une vidéo comprenant 3 flux Images : 210, rendu simultané de plusieurs images : activé |
| Cinebench | Version 11.5 Build CB25720DEMO Tests CPU mono et multithreadés |
| Blender | Version: 2.59 Syntaxe “blender -b thg.blend -f 1”, résolution : 1920 x 1080, antialiasing : 8x, rendu : THG.blend frame 1 |
| Adobe Photoshop CS 5.1 (64-Bit) | Version: 11 Filtrage d’un image TIFF de 16 Mo (15000 x 7266) Filtres: Flou radial (quantité : 10 ; méthode : zoom ; qualité : bonne) Flou de forme (rayon : 46 px ; forme personnalisée : symbole « Trademark ») Médiane (rayon : 1 px) Coordonnées polaires (rectangulaires en polaires) |
| ABBYY FineReader | Version : 10 Professional Build (10.0.102.82) Lecture d’un PDF et enregistrement en DOC, source : « Political Economy » (J. Broadhurst, 1842) 111 pages |
| 3ds Max 2012 | Rendu d’un vol spatial (1440×1080) au départ d’un disque RAM Y: |
| Adobe Acrobat X Professional | Création (impression) d’un document PDF au départ de Microsoft PowerPoint 2010 |
| SolidWorks 2010 | PhotoView 360, fichier de benchmark 01-Lighter Explode.SLDASM, rendu en 1920×1080, 1,44 million de polygones, 256 échantillons AA |
| Visual Studio 2010 | Compilation de Miranda IM (scriptée) |
| Benchmarks synthétiques | |
| Benchmark | Détails |
| PCMark 7 | Version 1.0.4 |
| 3DMark 11 | Version 1.0.2 |
| SiSoftware Sandra 2011 | Version : 17.80 Processor Arithmetic, Multimedia, Cryptography, Memory Bandwidth, .NET Arithmetic, .NET Multimedia |
Résultats : PCMark 7
Comme à notre habitude, nous commençons par les résultats synthétiques, car nous aimons voir si un processeur est à la hauteur en utilisant des mesures rigoureusement contrôlées.
PCMark 7 n’isole pas forcément les capacités particulières d’une plateforme donnée, parce qu’il se compose d’éléments directement liés à Windows 7. Malgré certains rapports indiquant le contraire, cette suite utilise autant de cores qu’on peut lui en donner.
Bureautique

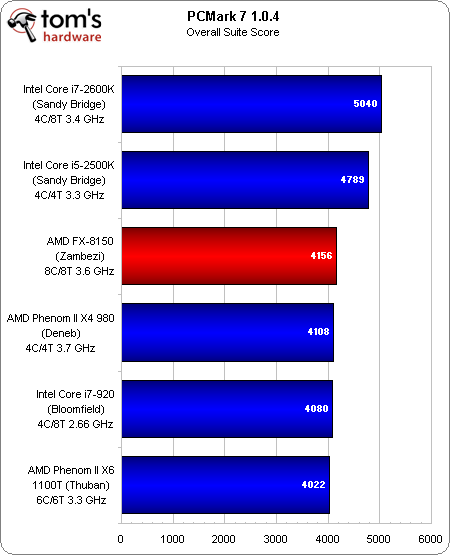
Ceci étant dit, le FX-8150 ne parvient à distancer le Phenom II X4 980, un processeur quad-core cadencé à 3,7 GHz, que de justesse. Il ressort du score global (Overall Suite score) que les cores i5-2500K et i7-2600K sont nettement plus rapides :
Score global
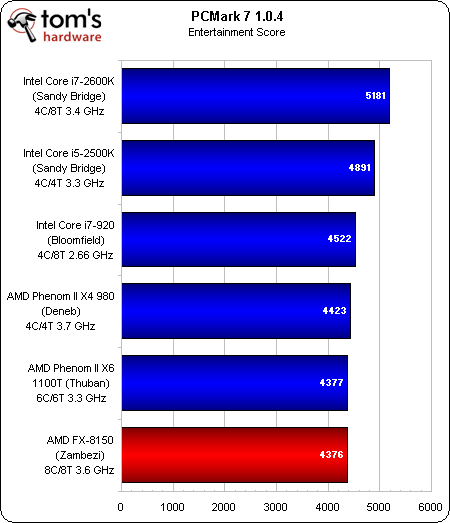
Divertissement
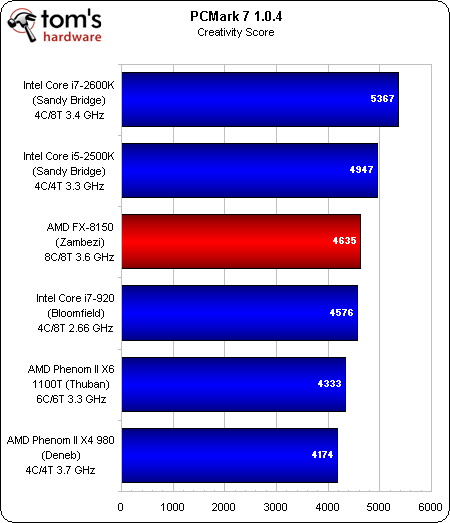
Créativité
Calcul
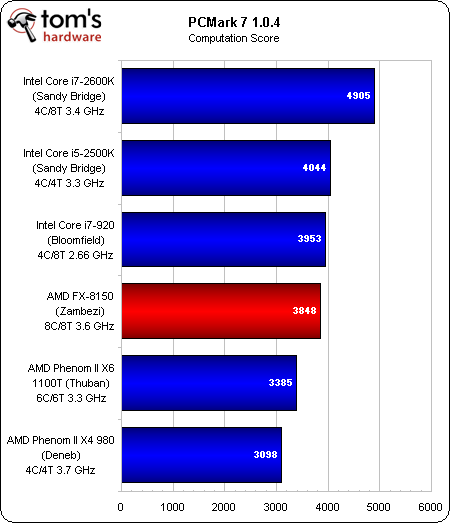
C’est dans la portion Divertissement que le FX obtient son plus mauvais classement, car elle pèse sur les calculs graphiques, la lecture/le transcodage vidéo et le stockage. Lorsque le nouveau fer de lance d’AMD se classe derrière la génération précédente, qui plus est derrière des modèles à quatre ou six cores, cela ne présage rien de bon. Heureusement, le Zambezi fait au moins jeu égale avec ces puces plus anciennes dans les autres tests.
Toutefois, dans au moins deux tests, l’AMD FX (245 $) est battu par un vénérable Core i7-920 fonctionnant à 2,66 GHz, sa valeur par défaut. Il est par ailleurs devancé dans toutes les disciplines par le Core i5-2500k à 220 $ et le Core i7-2600K à 315 $.
Résultats : 3DMark 11
Un rien plus favorable à l’égard de la nouvelle architecture AMD que PCMark 7, 3DMark 11 génère un thread par core physique dans les tests graphiques et un autre par core logique dans les tests physiques/combinés.
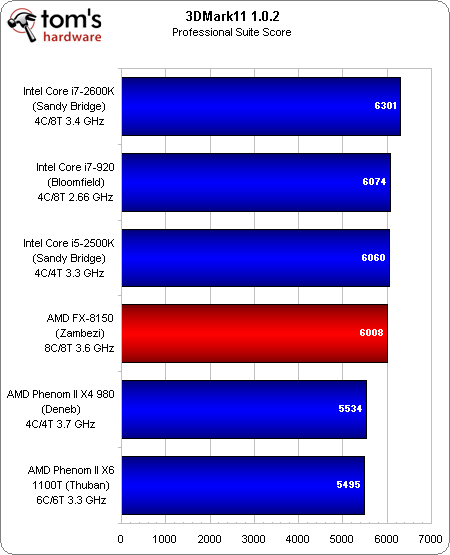
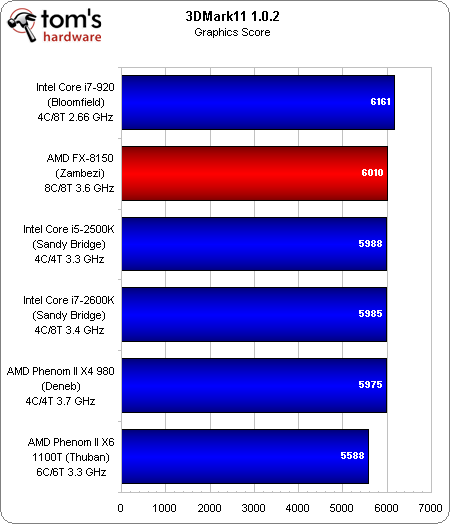
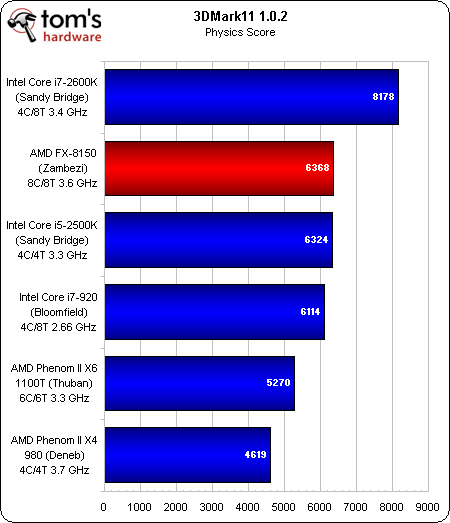
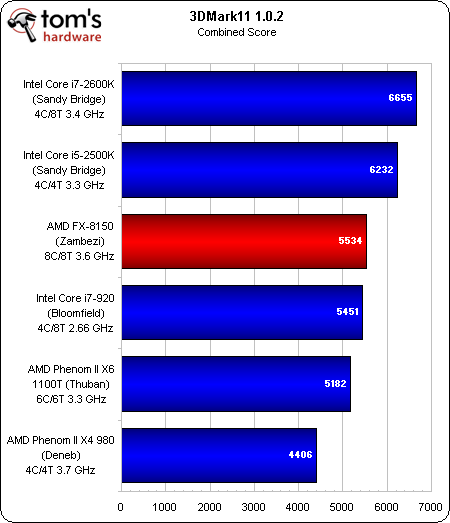
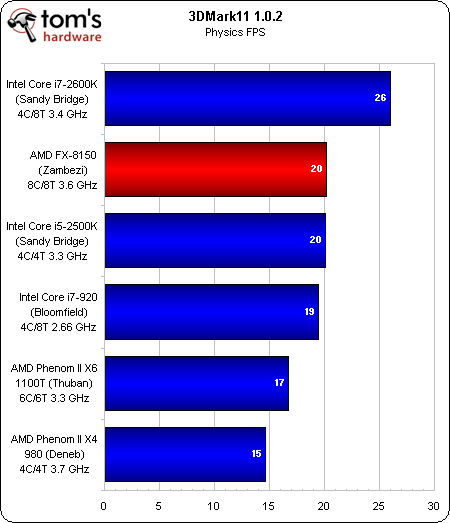
La 2e place décrochée dans la suite Graphics pourrait s’expliquer par le fait que le 3DMark reconnaît deux cores physiques par module Bulldozer.
Résultats : Sandra 2011
Arithmétique processeur
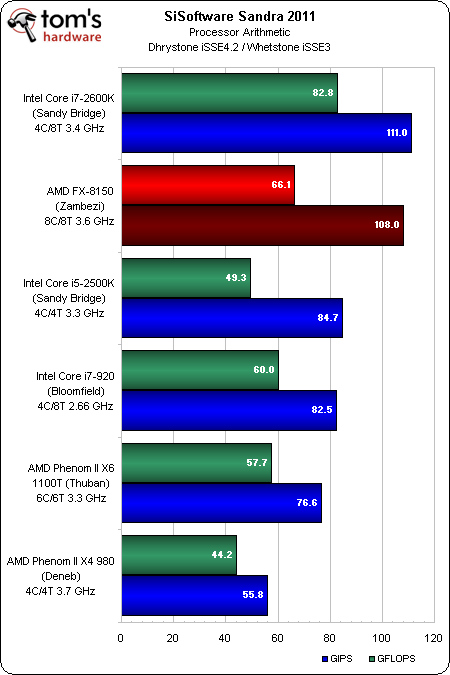
Les calculs en virgule flottante et sur nombres entiers ont tous les deux été améliorés dans l’architecture Bulldozer, ce qui permet au FX-8150 de se classer à la deuxième place derrière l’Intel Core i7-2600K ; un résultat remarquable étant donné que le Zambezi, qui ne possède que quatre FPU pour ses 8 cores, parvient néanmoins à devancer les 6 cores du Phenom II X6 lors du test portant sur le jeu d’instructions SSE3.
Multimédia
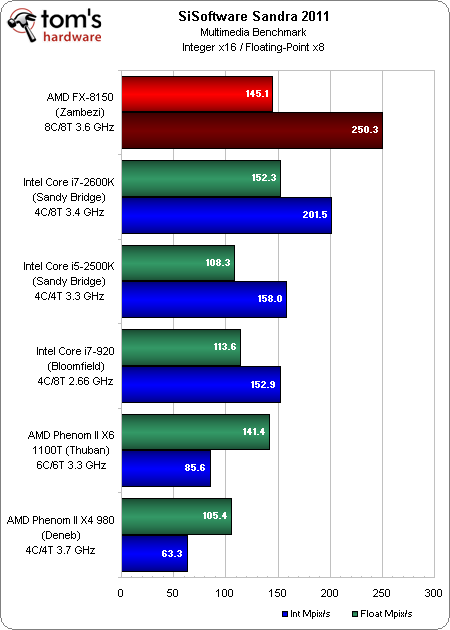
Les performances exceptionnelles du FX-8150 en SSE2 sur nombres entiers propulsent celui-ci devant le line-up d’Intel dans le test Multimédia de Sandra. Dans les calculs en virgule flottante, par contre, les FPU partagés ne peuvent atteindre les mêmes résultats, bien que le FX-8150 reste assez proche de l’Intel Core i7-2600K.
Chiffrement
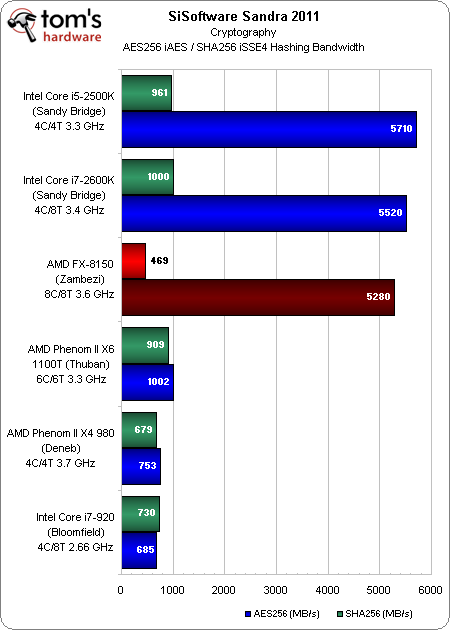
Le support matériel du chiffrement AES permet à AMD d’arriver à égalité avec ce qui fut jadis la valeur ajoutée exclusive d’Intel : le FX-8150 atteint un débit impressionnant dans cette discipline, se classant juste en-dessous du Core i5.
C’est une autre paire de manches pour la cryptographie en SHA-1, car l’architecture Bulldozer perd une marge significative relativement au Phenom II X6 et même X4 (sans même parler des trois processeurs Intel testés). Heureusement pour tous ceux chiffrent leur disque dur, l’AES reste la mesure la plus pertinente.
Bande passante mémoire
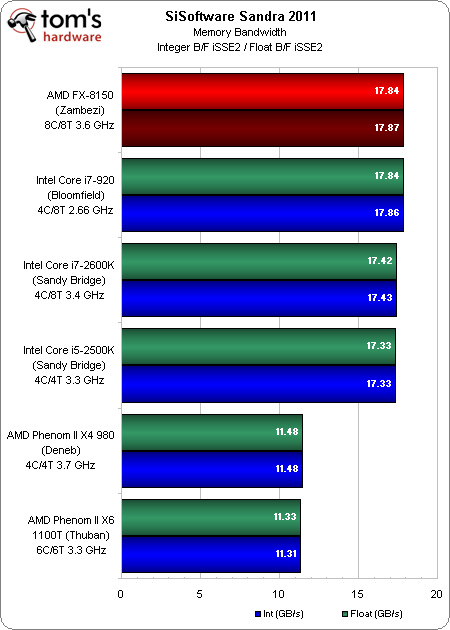
Le contrôleur mémoire DDR3 bicanale mis à jour supporte officiellement des débits de données jusqu’à 1866 MT/s, ce qui permet à AMD d’offrir une bande passante plus importante qu’auparavant. Nous utilisons ici de la DDR3-1600 pour comparaison, étant donné que nos barrettes 8 Go ne montent pas plus haut. Il est tout de même impressionnant de voir le contrôleur d’AMD rivaliser facilement avec celui d’Intel (en particulier par rapport au débit du Phenom).
L’importance du .NET
Outre les benchmarks habituels sous Sandra 2011, nous avons également exécuté les tests .NET arithmétique et multimédia. Notre raisonnement est simple : avec l’arrivée prochaine de Windows 8 (et les plans qu’a annoncés Microsoft pour son interface Metro), la façon dont chacun de ces CPU exécute un code .NET gagnera en importance. Tant que cette couche ne tirera pas avantage d’AVX, par exemple, les applications ne profiteront pas d’un support matériel, peu importe qu’il provienne d’Intel ou d’AMD.
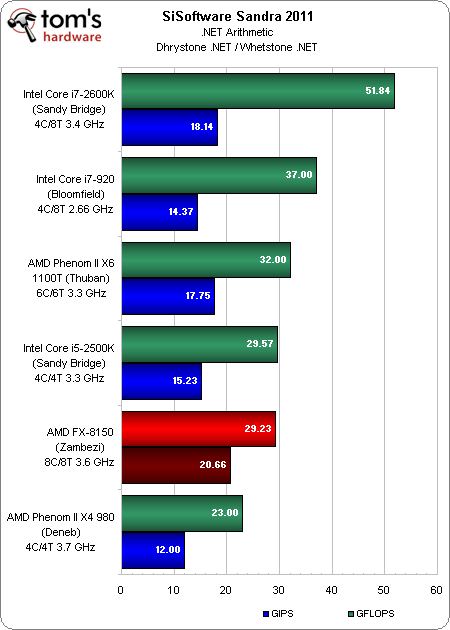
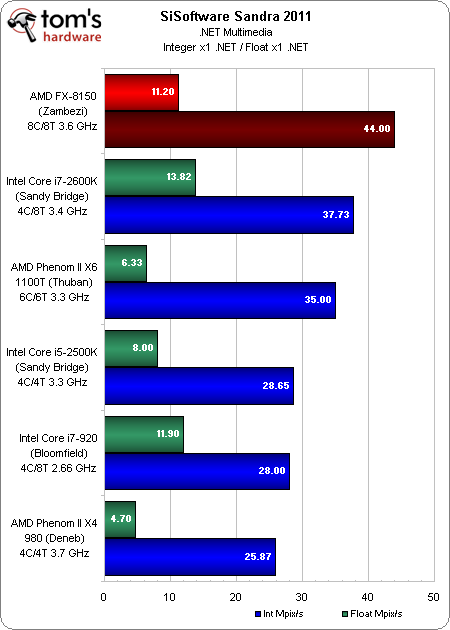
Le FPU de l’AMD FX décroche ici un bon résultat, atteignant 20,66 GFLOPS par rapport aux 18,14 du Core i7-2600K. Plus curieuse est la performance du Zambezi au niveau des nombres entiers, qui enregistre un retard important sur le Sandy Bridge. Selon l’auteur de Sandra, il pourrait s’agir d’un problème lié à la fonction ou au threading qui sera résolu dans une future version, dès qu’il mettra la main sur un processeur FX. Nous y reviendrons à la première occasion.
Résultats : création de contenu
3ds Max 2012
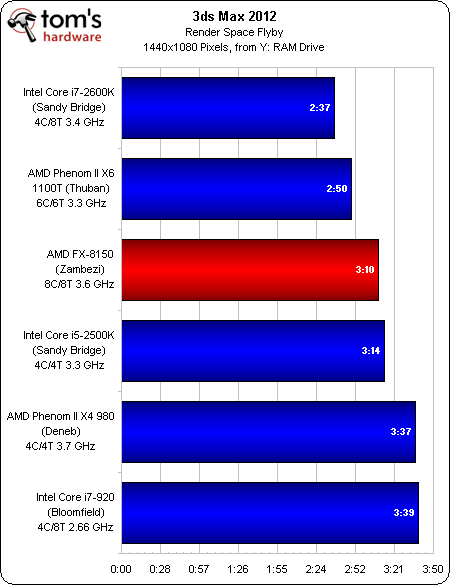
Le FX-8150 qui s’intercale entre les Core i7-2600K et 2500K ? Pas une surprise. Mais le Phenom II X6 1100T qui surpasse le FX l’est beaucoup plus ! C’est une des conséquences du partage des ressources sur les flottants de Bulldozer, alors que le Thuban dispose de 6 cores complets.
Les autres résultats sont assez différents.
Adobe Photoshop CS 5.1
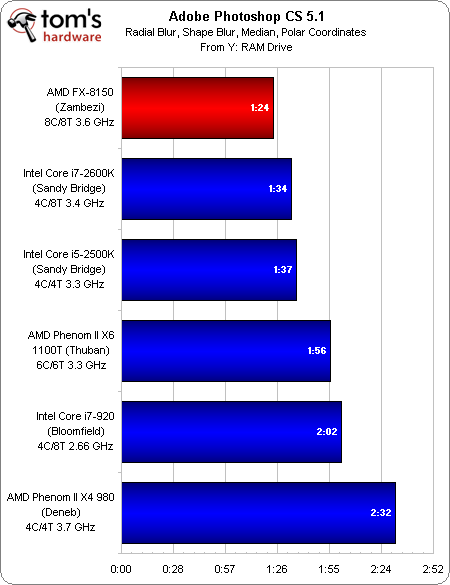
Ce test utilise des filtres threadés et gère autant de cores qu’on lui en donne. Cela profite évidemment aux huit unités de traitement sur nombres entiers du Zambezi, qui parvient à dépasser les Cores i5 et i7 et à battre à plate couture le Phenom II X6 110T et ses 6 cores.
Adobe Premiere Pro CS 5.5
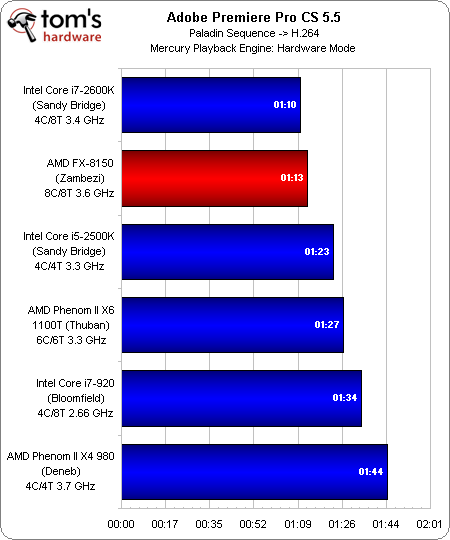
Avec une Nvidia GeForce GTX 580, l’accélération matérielle du Mercury Playback Engine transforme un rendu de pratiquement une heure en une opération prenant moins de deux minutes. Toutefois, les performances du processeur joue également un rôle. Le FX-8150 d’AMD prend la deuxième place derrière le Core i7-2600K d’Intel et devant le Core i5, son concurrent direct.
Adobe After Effects CS 5.5
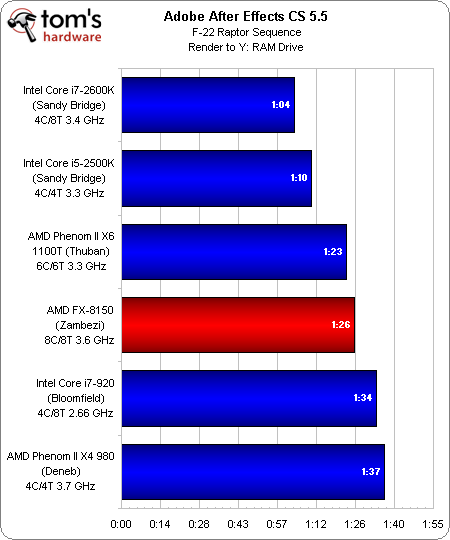
Le classement final du Zambezi n’est pas génial dans After Effects CS 5.5. Non seulement ses deux concurrents basés sur Sandy Bridge le précèdent, mais le Phenom II X6 110T d’AMD se révèle également plus rapide.
Blender
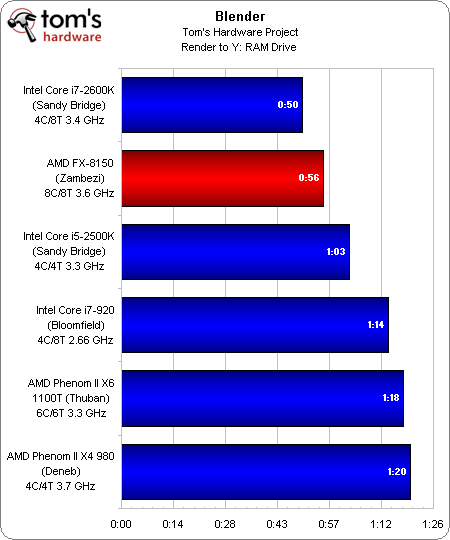
Les résultats sous Blender sont beaucoup plus favorables ; le produit phare d’AMD se classe juste derrière le Core i7-2600K d’Intel. Tandis qu’After Effects s’est montré incapable d’utiliser l’entièreté des ressources de traitement disponibles, Blender exploite tous les cores disponibles à 100 %, ce qui profite au Zambezi.
SolidWorks 2010
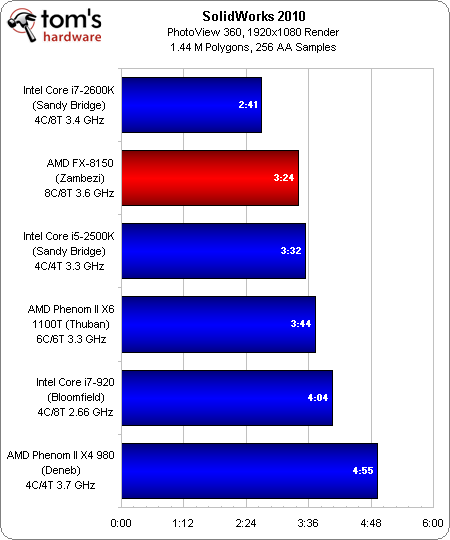
L’application PhotoView 360 de SolidWork est également capable de charger entièrement l’ensemble des processeurs testés, ce qui permet au FX-8150 d’AMD de prétendre à une deuxième place sur la ligne d’arrivée, entre le Core i7 et le Core i5. Sans surprise, le Phenom II X6 arrive en quatrième position, tandis que les deux modèles à quatre cores ferment la marche.
Au final, cette catégorie de logiciels est la plus à même de tirer profit de ce que le Zambezi apporte en tant que solution de bureau. La création de contenu est connue pour utiliser toutes les ressources disponibles et, vu son prix plus proche du Core i5-2500K que de l’i7-2600K, le FX-8150 semble être dans son élément.
Résultats : bureautique
ABBYY FineReader
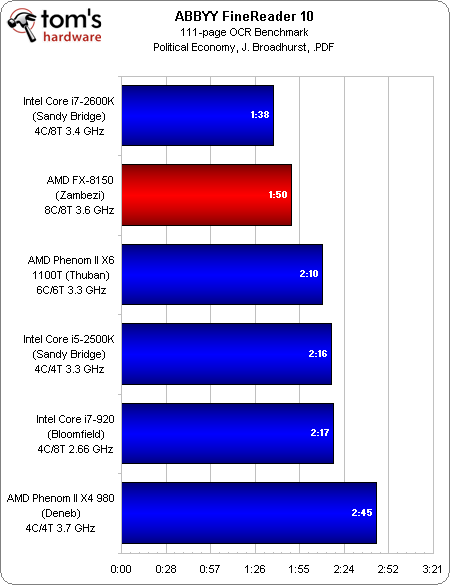
La capacité de l’application OCR ABBYY FinReader à charger entièrement des cores de traitement permet au FX-8150 de prendre la deuxième place, entre le Core i7-2600K et le Core i5-2500K.
Une fois de plus, ce résultat montre le meilleur de ce que le Zambezi peut réaliser, cette fois dans un titre orienté bureautique.
Lame
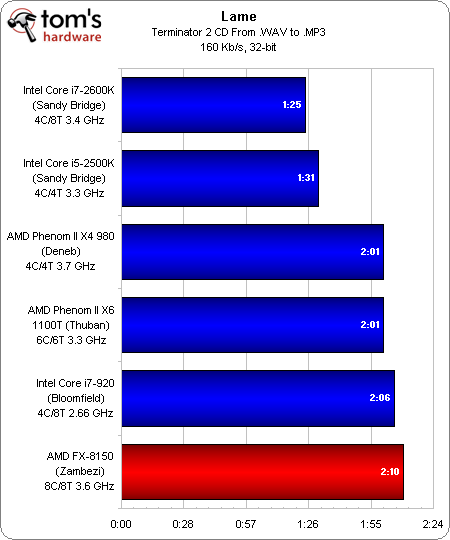
Les applications monothreadées telles que Lame révèlent avec dépit qu’AMD a perdu beaucoup de performance par cycle avec Bulldozer. Ici, le FX-8150 monte jusqu’à 4,2 GHz ; et pourtant, il se fait toujours battre par l’ancien Intel Core i7-920 à 2,93 GHz (2,66 GHz plus 2 crans de Turbo Boost), un processeur pourtant vieux de trois ans !
WinZip
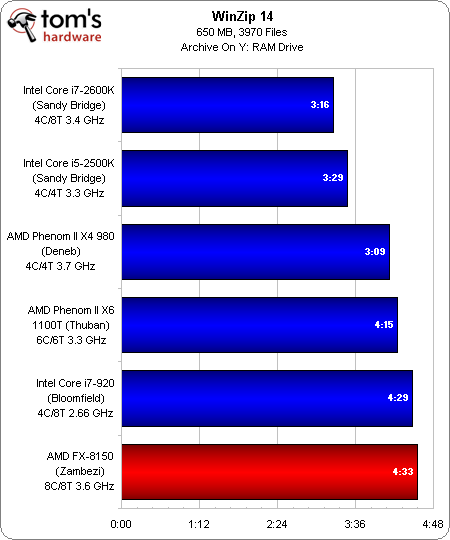
C’est aussi le cas dans WinZip 14, un logiciel d’une catégorie totalement différente mais également monothreadé. Le FX-8150 occupe la dernière place à cause de son nombre d’instructions traitées par cycle, plutôt lamentable.
WinRAR
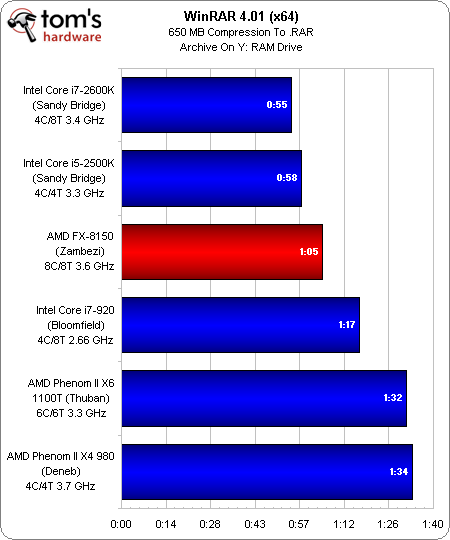
Contraste saisissant, nous savons que WinRAR est bien multithreadé (bien qu’il soit incapable d’éprouver entièrement un processeur multi-core). Même si le FX-8150 d’AMD finit toujours par être battu par les processeurs basés sur l’architecture Sandy Bridge, il améliore son résultat et devance le Core i7-920, le Phenom II X6 et le Phenom II X4.
7-Zip
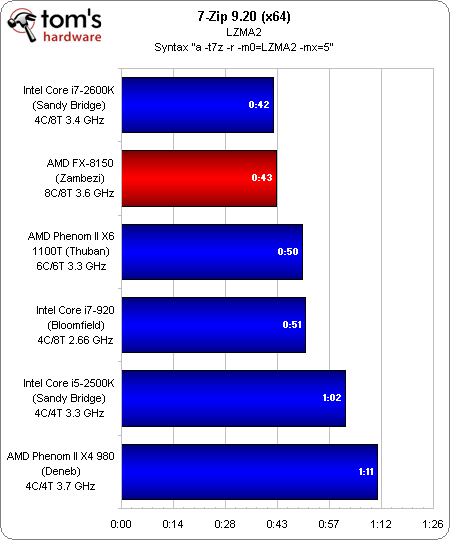
7-Zip nous offre un excellent troisième point de comparaison. Par rapport à WinZip (monothreadé) et WinRAR (multithreadé), 7-Zip pousse tous les cores à presque 100 %, ce qui permet au FX-8150 de combler quasiment son retard sur le Core i7-2600K et surtout à battre à plate couture le Core i5-2500K. Les processeurs Thuban, Bloomfield et Deneb sont également tous les trois surclassés.
Adobe Acrobat X Professional
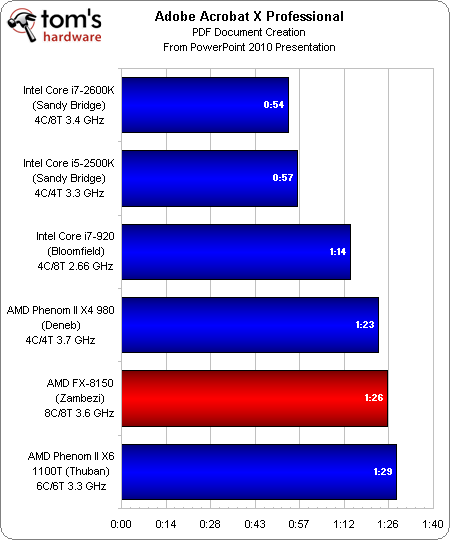
À ce stade, nous avons eu suffisamment de résultats pour évaluer la charge réellement appliquée par un logiciel en nous basant sur le classement final du FX-8150.
Les performances par cycle exceptionnelles de l’architecture Sandy Bridge d’Intel lui confèrent un avantage insurmontable dans les tests monothreadés et peu multithreadés. Lorsque nous imprimons une présentation PowerPoint dans un fichier Adobe PDF, le Zambezi retombe à l’arrière du peloton.
Visual Studio 2010
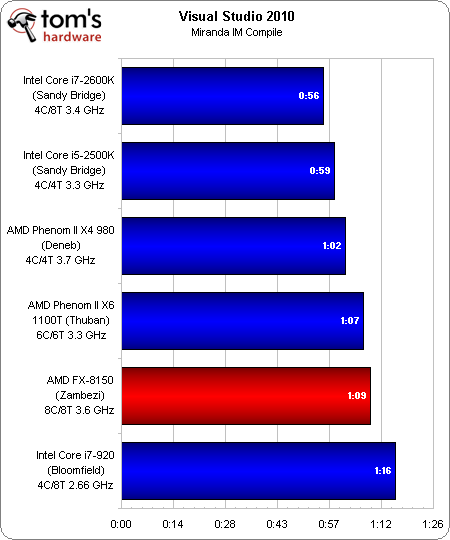
La position de Zambezi dans le graphique ci-dessus pourrait laisser croire que Visual Studio est monothreadé. Pourtant, un coup d’œil au gestionnaire des tâches de Windows nous montre que, la plupart du temps, tous les cores tournent à 100 % avec cette charge.
Pourquoi le FX-8150 obtient-il un résultat aussi mauvais ? Difficile à dire. Le classement des processseurs suivant les puces basées sur l’architecture Sandy Bridge d’Intel pourrait suggérer que Visual Studio est plus dépendant de la fréquence qu’on ne le penserait. Le Zambezi en regorge, mais son nombre d’instructions par cycle est suffisamment mauvais pour le classer derrière Phenom II X4 et X6.
Comparé à la page précédente, les applications monothreadées et peu multithreadées pourraient être qualifiées de M. Hyde dans cette histoire, tandis que les applications intensives et fortement multithreadées seraient notre Dr Jekyll. Alors que le rapport performances/prix du FX-8150 semblait raisonnable auparavant, AMD nous demande désormais d’accepter un compromis significatif en termes de performances, ce qui obligera les amateurs à y regarder à deux fois.
Résultats : encodage
iTunes
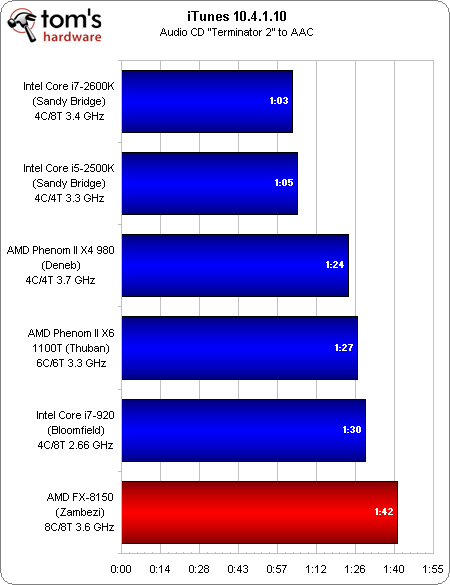
iTunes, application notoirement incapable de tirer parti de plus d’un seul core à la fois, ne fait sans surprise aucun cadeau au nouveau fer de lance d’AMD, le renvoyant à l’arrière du peloton après avoir étalé son incapacité à à tenir tête à l’ancienne architecture, alors qu’il est tout de même cadencé à 3,7 GHz (voire à 4,2 GHz grâce au Turbo Core).
MainConcept
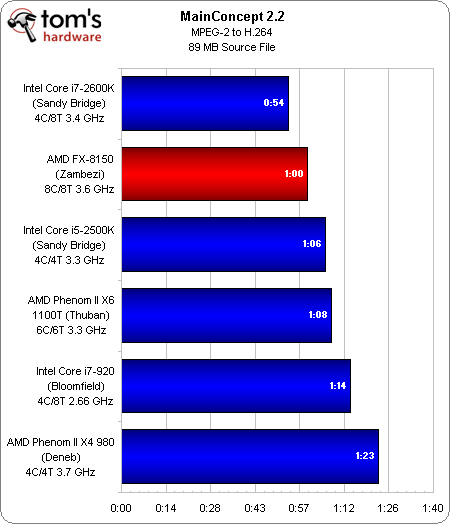
La situation se renverse sous MainConcept, qui exploite toutes les ressources du Zambezi et ramène le FX-8150 à la deuxième place, entre ses deux concurrents basés sur l’architecture Sandy Bridge. Les six cores du Thuban permettent au Phenom II X6 de prendre la quatrième place, suivi des processeurs Bloomfield et Deneb.
HandBrake
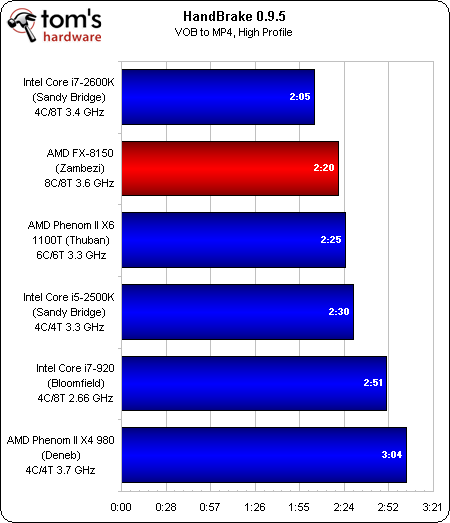
La même hiérarchie vaut pour HandBrake, qui place le FX-8150 juste après le core i7-2600K. Le Phenom II X6 1100 T dépasse le Core i5, qui se retrouve de ce fait 3e au classement.
Résultats : Crysis 2
Aujourd’hui, nous testerons 3 jeux
très différents : Crysis 2, F1 2011 et World of Warcraft: Cataclysm. Commençons par Crysis 2.
1680 x 1050
1920 x 1080
2560 x 1600
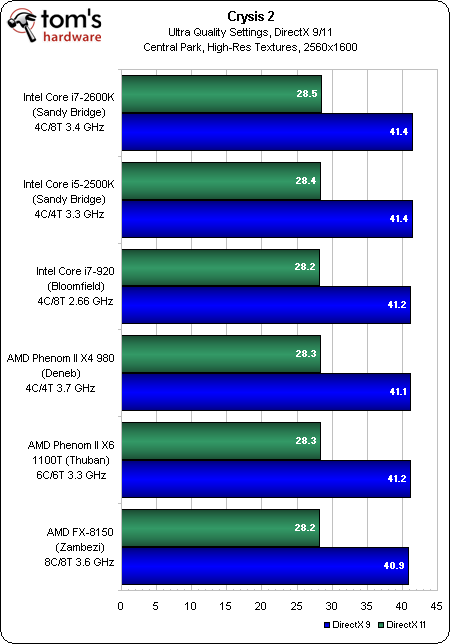
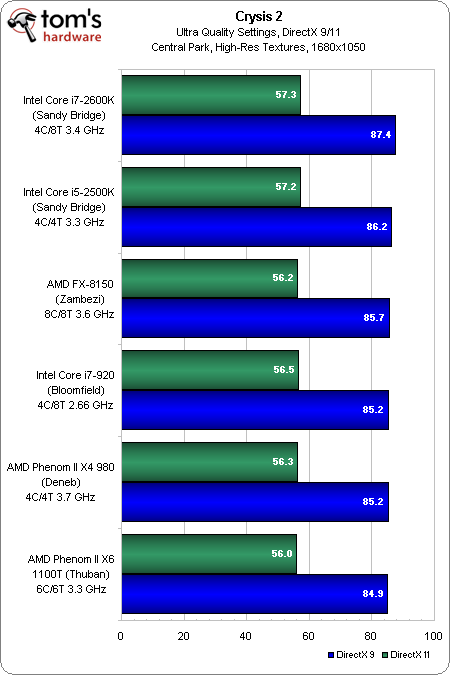
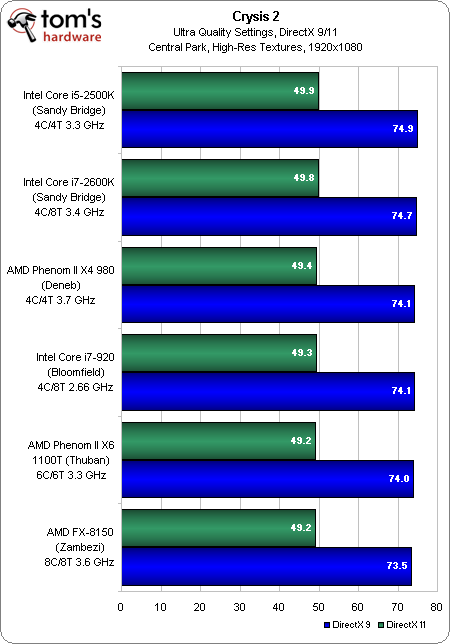
Crysis 2, notre FPS favori, est révélateur des titres les plus visuels qui poussent les joueurs à dépenser de grandes sommes d’argent dans du multi-GPU. Tel est le type d’applications qu’AMD aimerait que vous associez à FX. Pourtant, peu importe que vous achetiez un processeur à 250 € ou à 1000 € ; c’est le potentiel de la carte graphique qui détermine la performance globale.
De 1680×1050 à 2560×1600, que ce soit avec DirectX 9 ou 11, les résultats sont quasiment identiques. Passons donc à la suite.
Résultats : F1 2011
1680 x 1050
1920 x 1080
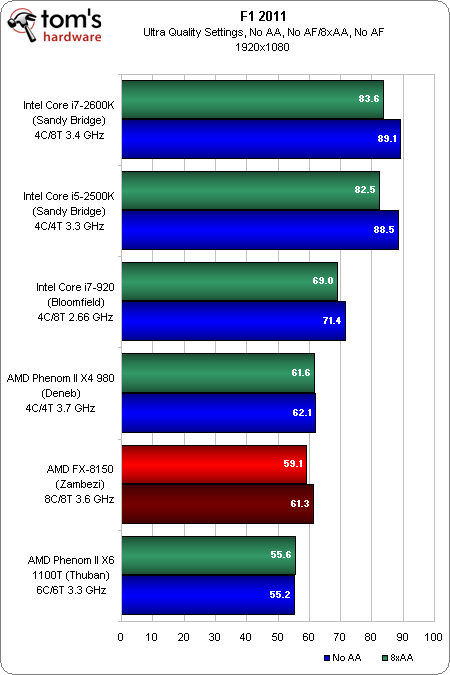
2560 x 1600
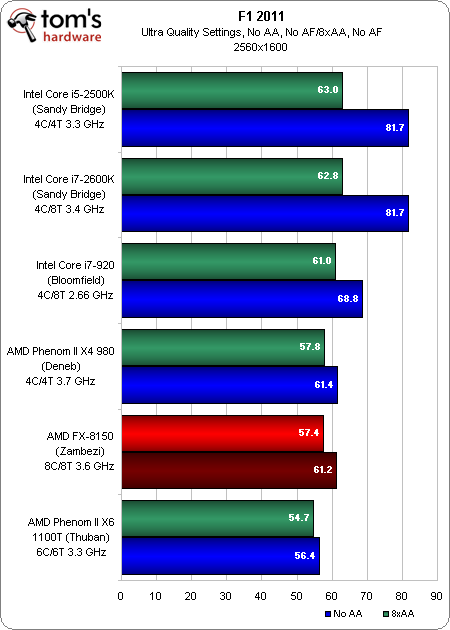
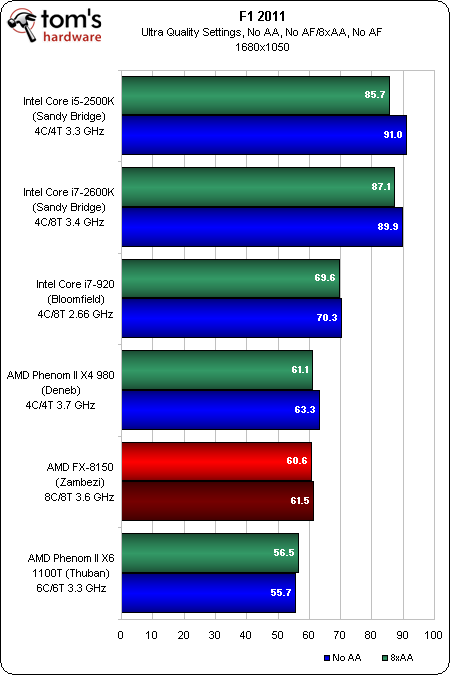
Nous avons souligné la performance du FX-8150, parce que le delta entre le niveau le plus faible et le plus élevé est bien plus important.
Les puces basées sur l’architcture Sandy Bridge d’Intel occupent le top 2 pour les trois résolutions, et avec une marge confortable. Le Bloomfield décroche la 3e place sur l’ensemble. Dans le même temps, le FX-8150 se classe avant-dernier dans les trois résolutions.
Nous avons rencontré de sérieux problèmes avec les processeurs AMD sur F1 2010. Ces performances limitées semblent également se reporter ici. Fondamentalement, nous les voyons se heurter à un plafond lié au CPU à 1680×1050, tandis que la charge graphique n’est pas suffisamment importante pour supprimer le goulot d’étranglement, même en 2560×1600.
Les deux puces basées sur Sandy Bridge nous révèlent pourquoi : dépassant facilement les 80 images par seconde en 1680×1050 et 1920×1080, il faut du 2560×1600 avec antialiasing 8x et des réglages d’une qualité extrême pour réduire la performance à environ 60 images/s, ce qui reste toujours mieux que ce qu’atteint le Zambezi.
Résultats : World of Warcraft: Cataclysm
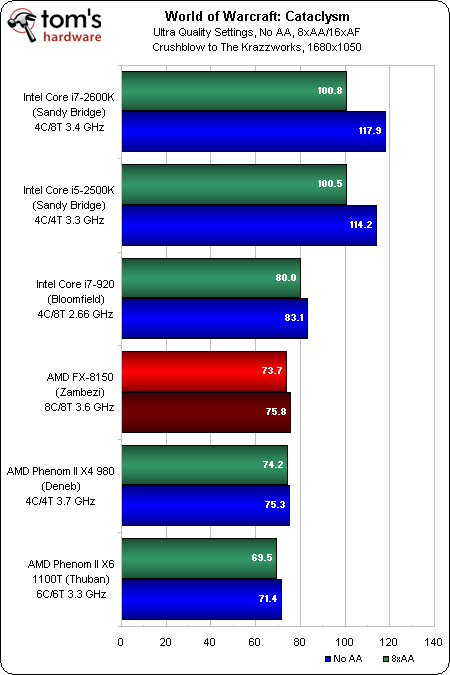
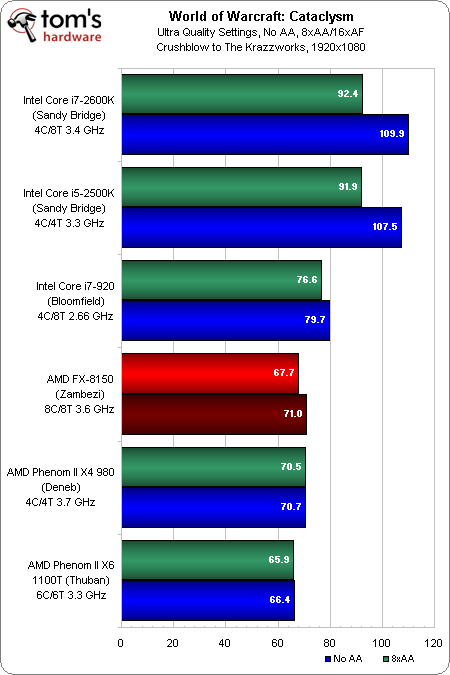

Il y a un peu moins d’un an, nous avons publié un article afin d’évaluer les performances de Cataclysm suivant les paramètres graphiques, CPU et GPU. Il en était ressorti trois tendances de fond : le rendu DX11 expérimental améliorait grandement les performances, les GeForce se comportaient bien mieux que les Radeon et enfin, les processeurs Intel étaient très nettement supérieurs à ceux d’AMD.
Le code DX11 est maintenant officiellement géré par le jeu. Quand bien même on utilise une GTX 580 de manière à éviter les goulets d’étranglement GPU, on constate que les processeurs AMD continuent à souffrir.
En 1680×1050 sans AA, Zambezi accuse un retard d’environ 40 ips par rapport au Core i5-2500K. A l’opposé des deux Sandy Bridge, le Core i7-920 et l’ensemble des processeurs AMD ne souffrent que très peu de l’activation de l’anti-aliasing vu que ce sont eux qui limitent les performances, même si l’on reste dans une fourchette allant à peu près de 70 à 80 ips avec une GTX 580.
En 2560×1600, la charge graphique due à la résolution ainsi qu’aux filtrages fait fléchir les performances jusqu’à 60 ips environ. En parallèle, on voit également que le Core i5-2500K continue de mette 25 ips dans la vue de l’AMD FX-8150 sans filtrages.
Il est vraiment regrettable que Bulldozer soit incapable de surpasser les précédents quad- et hexacore d’AMD sur un jeu aussi populaire, même s’il faut rappeler que nous utilisons une GTX 580 qui reste à ce jour la carte mono-GPU la plus puissante du marché. Avec une carte graphique moins performante, le FX-8150 fera meilleure figure du fait que les limitations seront bien moins flagrantes. Les faits sont là : AMD est obligé de jouer sur les limitations des composants autres que le CPU pour que Zambezi paraisse aussi compétitif que la concurrence, ce que l’on ne peut que déplorer.
Comparer ce qui est comparable
Cette situation nous amène à la communication d’AMD : le géant de Sunnyvale tente de dénigrer le haut de gamme d’Intel en comparant le coût d’une machine basée sur un Core i7-980X contre une autre équipée d’un FX-8150. Naturellement, le surcoût du au kit mémoire triple canal, à la carte mère X58 ainsi qu’au processeur Extreme Edition est considérable puisque l’on arrive à 800 $ … mais on est aussi et surtout en train de marcher sur la tête.

Comme nous l’avons déjà dit lors du test du Core i7-990X, les processeurs Gulftown s’adressent à un marché de niche bien précis pour lequel les performances ludiques sont accessoires.
Le marketing d’AMD est donc complètement à côté de la plaque sachant que le FX-8150 est en concurrence directe avec le Core i5-2500K et le Core i7-2600K, mais sûrement pas le Core i7-980X. Le coût des plateformes est alors très proche, à l’avantage d’Intel si l’on prend le 2500K et à l’avantage d’AMD avec le 2600K. Le FX se comporte donc très bien sur les titres qui sont avant tout limités par les performances du GPU (comme Crysis 2), mais il montre aussi un visage moins séduisant que Sandy Bridge lorsque la charge est plus équilibrée (tout du moins sur F1 2011 et WoW : Cataclysm).
Overclocking (refroidissement par air)
D’après les ingénieurs d’AMD, Bulldozer a été conçu pour exécuter un nombre instructions par seconde (IPC) stable et permettre des fréquences élevées. On s’attend donc logiquement à un beau potentiel d’overclocking.
AMD a quelque peu tué le suspense en nous envoyant un guide d’overclocking, qui donne des prévisions basées sur les essais réalisés en interne : l’équipe d’AMD a ainsi pu atteindre 4,6 GHz stables sur tous les cores avec un dissipateur à air et 4,9 GHz en watercooling. L’azote puis l’hélium liquide, utilisés pour trouver un écho médiatique et prouver l’absence de « cold bug », leur ont permis d’atteindre respectivement 7,7 et 8 GHz (tous cores actifs).
Le FX-8150 affiche une fréquence native de 3,6 GHz. Le Turbo Core intermédiaire (pallier que les 8 cores peuvent atteindre en simultané) est à 3,9 GHz et enfin, le Turbo Core maximal (jusqu’à 4 cores actifs) plafonne à 4,2 GHz.
De notre côté, nous avons atteint 4,5 GHz stables sur tous les cores avec une tension de 1,425 Volt. Le benchmark sous SolidWorks 2010 n’a alors duré que 2 minutes et 57 secondes contre 3’24 à fréquence d’origine, mais on était vraiment aux limites de la stabilité (nous ne sommes pas habitués à voir des températures supérieures à 66°C sur des puces AMD comme on peut le voir ci-dessous).
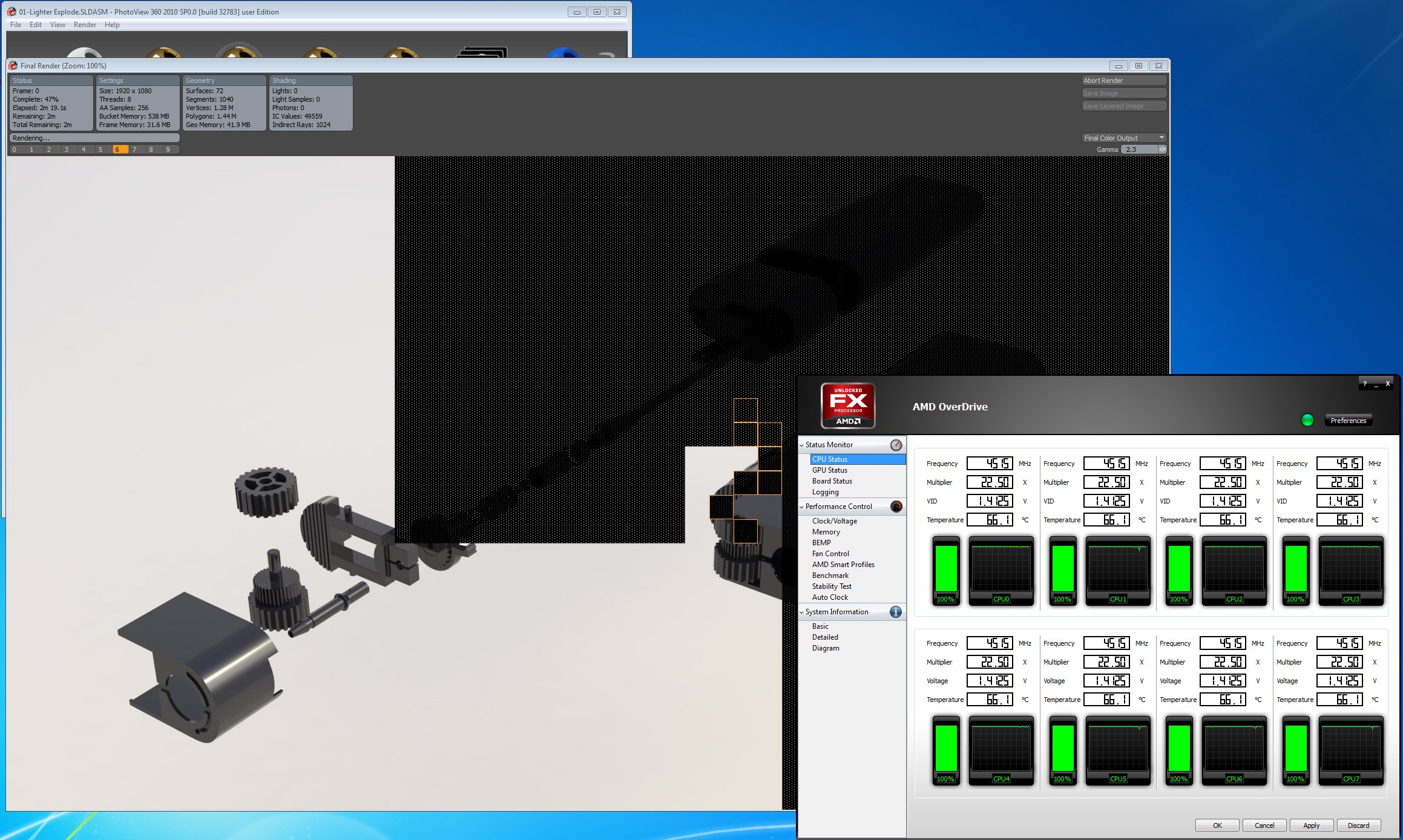
On pourrait opter pour une approche plus fine en baissant la fréquence du bus via l’AMD Overdrive tout en configurant de manière agressive les états processeur P1 et P0 du mode Turbo Core, de manière à mieux gérer les modules inactifs. Les programmes multithreads n’y gagneraient pas grand-chose, mais on aurait ainsi plus de chances d’atteindre des fréquences optimales à moindre tension dans le cas de logiciels comme iTunes et WinZip, qui n’utilisent qu’un seul core.
Echelonnement des performances mémoire
Grâce aux améliorations apportées par le socket AM3+, Bulldozer propose un contrôleur mémoire bien plus souple que son prédécesseur : le débit de données maximum est officiellement de 1866 MT/s, mais on peut aller encore plus loin avec une bonne carte mère.
A 1600 MT/s, le FX-8150 peut rivaliser avec Sandy Bridge, ce qui est assez impressionnant quand on considère la bande passante du Phenom II X6 avec deux canaux de DDR3.
Peut-on justifier l’achat d’un kit mémoire haute fréquence pour une configuration à base d’AMD FX ? Après avoir été jusqu’en DDR3-1600 avec deux barrettes de 4 Go, nous sommes passés à un kit 2×2 Go en DDR3-2133 pour évaluer le gain de performances sous WinRAR, programme que l’on a déjà vu sensible aux performances mémoire par le passé.
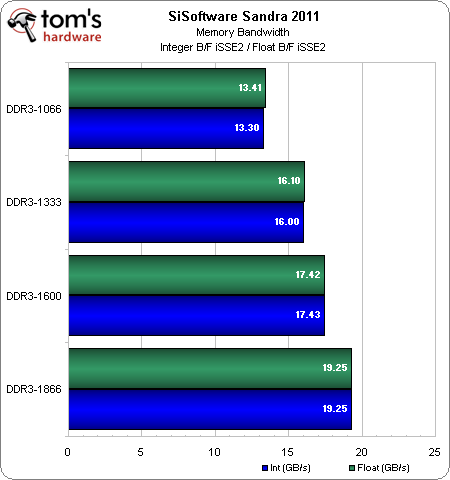
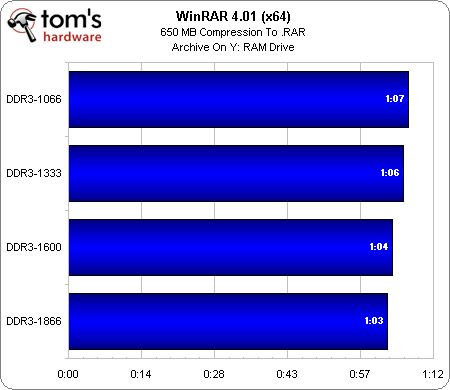
SiSoft Sandra 2011 illustre le fait que la bande passante mémoire continue d’augmenter jusqu’à la limite officielle du contrôleur, mais WinRAR montre que des gains apparemment conséquents en bande passante ne se traduisant pas par une augmentation proportionnelle des performances en pratique. Ceci étant dit, il est toujours bon de savoir que l’on peut gagner en performance lorsque l’on est prêt à optimiser la gestion mémoire.
Quid du refroidissement ?
AMD a prévu de lancer ses FX version boîte avec le même dissipateur que ceux des Phenom II X4 et X6 Black Edition. Plusieurs rumeurs suggèrent que le géant de Sunnyvale pourrait vendre certains modèles avec des kits watercooling prêts à l’emploi, ce qui est véridique mais limités à certains marchés dont le Japon en premier lieu. La possibilité de voir ce genre d’offre arriver en France n’est pas exclue mais nous n’avons aucune visibilité sur les disponibilités. De même, AMD devait nous envoyer un de ces watercooling mais nous n’avons rien reçu à ce jour.
Consommation
D’après AMD, les ingénieurs qui ont travaillé sur la conception de Bulldozer se sont attachés à optimiser le rendement. Cette approche est parfaitement sensée pour tirer un maximum de performances de chaque core tout en respectant un TDP contraignant dans le cas des processeurs à plusieurs puces comme Interlagos (2x huit cores), mais reste à voir si cette architecture échelonnable paye dans les configurations de particulier autant qu’elle promet du côté des serveurs.
| Processeur (fréquence d’origine) | Consommation globale au repos |
|---|---|
| AMD FX-8150 (Zambezi) 8C/8T, 3,6 GHz | 107 watts |
| AMD Phenom II X6 1100T (Thuban) 6C/6T, 3,3 GHz | 114 watts |
| AMD Phenom II X4 980 BE (Deneb) 4C/4T, 3,7 GHz | 100 watts |
| Intel Core i7-2600K (Sandy Bridge) 4C/8T, 3,4 GHz | 90 watts |
| Intel Core i5-2500K (Sandy Bridge) 4C/4T, 3,3 GHz | 90 watts |
| Intel Core i7-920 (Bloomfield) 4C/8T, 2,66 GHz | 130 watts |
En idle, la configuration à base d’AMD FX-8150 consomme 107 Watts soit légèrement moins que l’équivalent avec un Phenom II X6 1100T mais également un peu plus qu’un Phenom II X4 980, sachant que tous trois ont un TDP annoncé à 125 Watts. Seul le Core i7-920 (Bloomfield) affiche une consommation supérieure avec 130 Watts.
En comparaison, les deux configurations Sandy Bridge se contentent de seulement 90 Watts (les deux processeurs ont un TDP de 95 Watts).
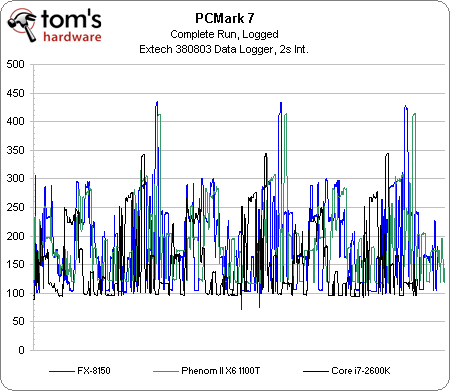
Nous avons retiré les Phenom II X4, Core i7-920 et Core i5-2500K de ce graphique pour qu’il reste lisible, les trois restants nous semblant être les plus intéressants.
La consommation moyenne de la configuration Core i7-2600K au cours d’une session sous PCMark 7 est de 155 Watts. On pourrait discuter sur le fait que le Core i5-2500K est plus proche d’un point de vue tarifaire mais le fait est qu’il ne consomme que 2 Watts de moins que le 2600K avec 153 Watts en moyenne sur ce benchmark. Les courbes seraient donc superposées sur le graphique.
En comparaison, le FX-8150 est à 191 Watts. Cet écart de 34 Watts par rapport au 2600K est très proche de celui annoncé en TDP (95 Watts contre 125 Watts). On retient surtout que le Phenom II X6 1100T arrive lui aussi à 191 Watts tandis que le Phenom II X4 980 est à 184 Watts.
Le Core i7-920 s’illustre donc ici comme étant le seul processeur Intel à consommer plus que le nouveau fer de lance d’AMD avec 193 Watts en moyenne.
Premier aperçu de Bulldozer sous Windows 8
Soyons clairs : il est beaucoup trop tôt pour juger des performances de Bulldozer sous Windows 8. Ceci étant dit, Windows 7 n’est pas spécialement optimisé pour les modules de Bulldozer. Arun Kishan (développeur Windows chez Microsoft) est responsable de la gestion des processus et du sous-système de threading et d’après lui, Windows 7 planifie les tâches vers les modules Bulldozer de manière égale quand bien même cette approche n’est pas optimale. La situation est d’autant plus intéressante que la prochaine version de Windows ne devrait très probablement pas les traiter de la même manière.
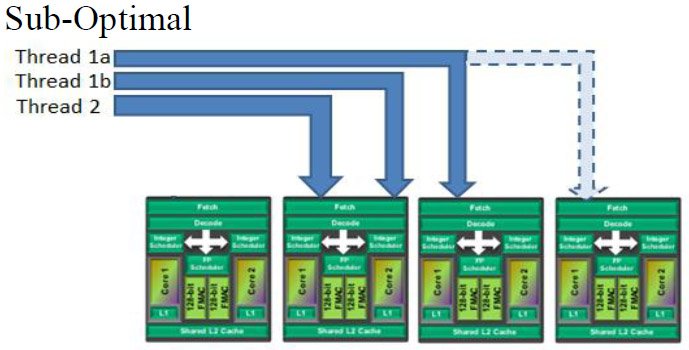
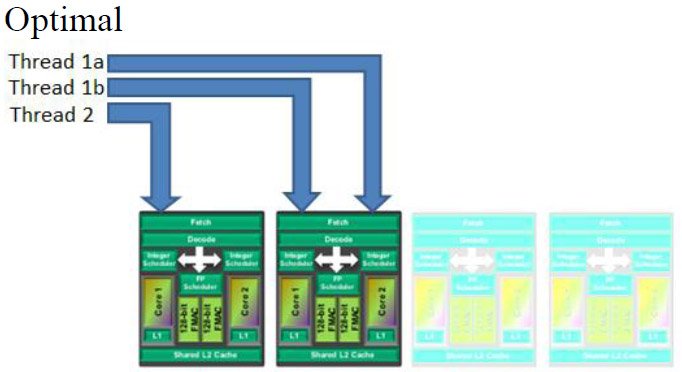
D’après AMD, Windows 8 répartira les threads de manière plus intelligente, à savoir que le partage d’un module sera effectué s’il y a un effet positif sur les performances à la clé. Ceci implique que lorsque deux threads peuvent être regroupés sur un seul module (ils sont alors contraints de partager les ressources), un autre sera mis en veille : le fait de pouvoir accéder à un palier Turbo Boost supplémentaire permettrait de prendre le pas sur la perte de performance causée par le partage des ressources.
Nous avons voulu essayer une série de tests pratiques pour voir ce qu’il en était, mais la version développeur de Windows 8 s’est montrée récalcitrante : la majorité de nos benchmarks sont scriptés et aucun d’entre eux n’a fonctionné, tandis que les programmes qui ne le sont pas (comme 3ds Max 2012) ont tout simplement refusé de s’installer.
En revanche, SolidWorks 2010, Premiere Pro CS5.5 et World of Warcraft nous ont permis d’avoir un aperçu des performances :
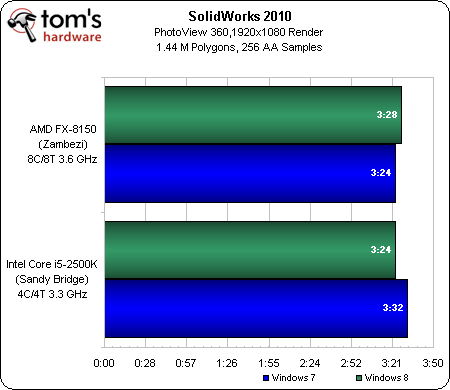
SolidWorks comme Premier Pro utilisent toutes les ressources disponibles. Si nous n’avons pas constaté le moindre écart avec le second, le premier donne un avantage de 8 secondes au Core i5-2500K et pénalise le FX-8150 de 4 secondes sous Windows 8 par rapport à Windows 7.
A priori, on ne peut pas s’attendre à un réel gain de performance dans le cas de programmes qui utilisent déjà toutes les ressources CPU : tous les cores sont déjà actifs et la réorganisation des threads ne facilitera pas l’accès à un palier Turbo Boost supplémentaire. Il est par contre bien plus vraisemblable de constater un effet positif avec des programmes moins intensifs.
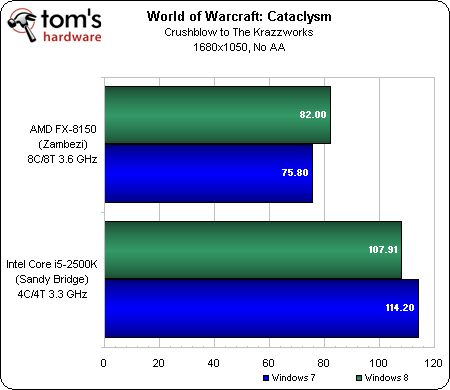
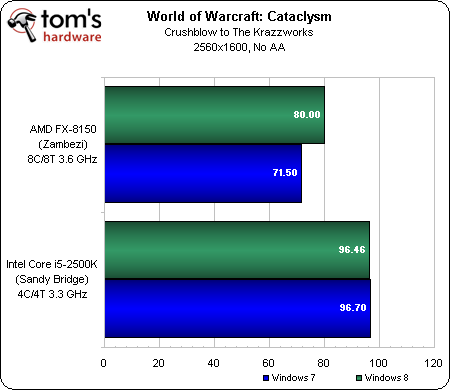
A ce stade, le FX progresse d’environ 8,5 % sur WoW en 1680×1050 alors que le Core i5 perd 5,5 % (on ne s’attend pas à ce constat avec la version finale de Windows 8, reste donc à voir si ce n’est pas lié à une latence de traitement).
En 2560×1600, le 2500K affiche des performances équivalentes quelle que soit la version de l’Os, tandis que le FX-8150 gagne 12 %.
« Core parking » : une fonctionnalité déjà au point
Le plus intéressant des changements tient au « core parking », une fonctionnalité de planification des tâches qui permet de répartir la charge de travail sur un minimum de cores tout en désactivant ceux qui ne sont pas utilisés : les cores de Bulldozer sont déjà reconnus et gérés en conséquence. Là où Windows 7 maintient tous les cores actifs, Windows 8 permet de les mettre au repos par paire.
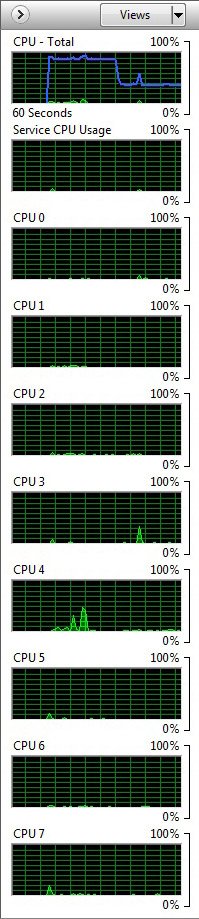
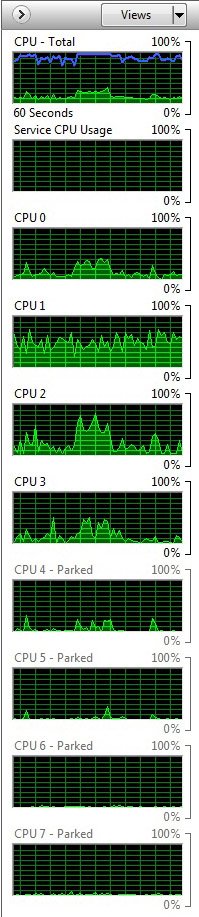
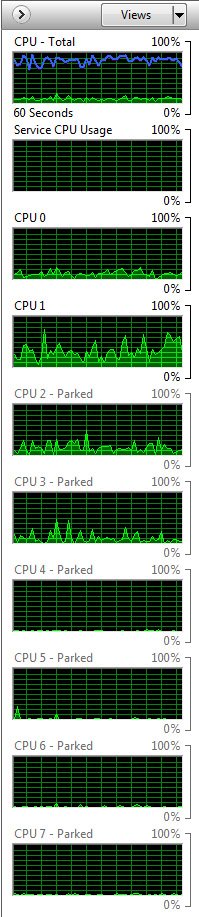
Voici un exemple concret sous Windows 7 (à gauche), sous Windows 8 avec deux modules Bulldozer au repos (centre) puis trois modules (droite).
Il en résulte des économies d’énergie bien réelles : la configuration passe de 107 Watts en idle sous Windows 7 à 99 Watts sous Windows 8 lorsque trois modules sont désactivés. Il n’y a donc plus que 9 Watts d’écart entre le FX-8150 et les deux Sandy Bridge série K sachant que leurs TDP respectifs sont annoncé à 125 et 90 Watts.
Pour dire les choses franchement, Windows 8 ne changera pas fondamentalement les performances de l’architecture Bulldozer, mais il ne faut donc pas négliger l’apport de l’OS quand on teste des composants : on peut tout de même s’attendre à quelques hausses de performance une fois que Windows 8 sera finalisé. L’influence positive de l’OS sur la consommation de Bulldozer semble déjà acquise vu que le futur OS de Microsoft prend déjà en compte les choix architecturaux d’AMD à ce stade.
Conclusion
S’il fallait faire un choix entre un Core i5-2500K à 190 euros et un FX-8150 à 245 $ (ce qui devrait se traduire par environ 220 euros chez nous à en juger par les premiers référencements en Europe), notre choix se porterait vers le premier. Nous lui avions déjà décerné un prix lors de son test en janvier dernier et près d’un an plus tard, il offre encore un rapport performances/prix très bon.
Dans le meilleur des cas de figure pour AMD, c’est-à-dire un environnement multithread qui sollicite pleinement les huit cores de Zambezi, le FX-8150 se place entre le 2500K et le 2600K. Compte tenu de son positionnement tarifaire ce devrait toujours être le cas, mais le processeur d’AMD peut tout aussi bien dépasser le 2600K que s’incliner de manière embarrassante devant le Phenom II X6 1100T suivant les situations.
Lorsque l’on a affaire à des programmes monothread comme Lame ou WinZip, le FX-8150 est même surclassé par le Core i7-920 qui en plus d’avoir trois ans n’est cadencé qu’à 2,66 GHz (contre 3,6 GHz). Les ingénieurs d’AMD ont beau affirmer que Bulldozer a été conçu pour exécuter un nombre instructions par seconde (IPC) stable et permettre des fréquences élevées, on sent que la firme texane a rencontré des problèmes en route.
Le discours officiel a quelque chose d’ironique vu qu’AMD met en avant la possibilité d’échelonner les performances de Bulldozer ainsi que leur stabilité. On voit le même problème se répéter : la compétitivité du processeur dépend du logiciel et lorsque celui-ci ne permet pas d’exploiter les possibilités multi-thread, on se retrouve avec des performances légèrement inférieures à celles de Thuban. Bien qu’AMD ait implémenté un mode Turbo Core plus efficace pour optimiser les performances monothread, les écarts de performances entre les programmes pas ou peu threadés et ceux qui le sont massivement est criante.
Néanmoins, AMD précise à juste titre que Bulldozer est une jeune architecture pour laquelle une feuille de route offensive a été prévue : on distingue déjà une architecture de jeu d’instructions (ISA) portée vers l’avenir. Le prix du FX-8150 est justifié lorsque les logiciels peuvent tirer parti de ces choix, mais les compromis dans les autres cas de figure rendent tout de même la pilule amère.

Une architecture aux bases saines ?
AMD prévoit de faire gagner 10 à 15 % de performances supplémentaires par an à Bulldozer. Si l’importance des progrès architecturaux est évidente, l’évolution du logiciel devra l’être tout autant. Vu la modularité de Zambezi, les progrès passeront par une hausse des fréquences, une vraie amélioration du nombre d’IPC ainsi qu’une consommation optimisée.
On peut donc s’attendre à ce que Piledriver (prévu pour 2012) corrige le tir en commençant par s’appuyer sur des améliorations au niveau IPC, ce qui est indispensable pour que l’architecture offre des performances plus équilibrées.
Le problème est que le temps presse : Sandy Bridge a presque un an et c’est donc face à Ivy Bridge qu’AMD devra lutter l’année prochaine… la situation actuelle n’est pas satisfaisante parce que l’on veut voir une vraie concurrence à tous les niveaux de prix, un contexte dans lequel AMD et Intel seraient contraints d’innover sans cesse. Le FX Zambezi peut-il se comparer à l’Athlon 64 FX-51 ? La réponse est évidemment non, AMD ayant frappé tellement fort il y a 8 ans qu’Intel avait du renommer un Xeon avec le suffixe Extreme Edition pour se remettre dans la course. Pire encore, les 2500K et 2600K n’ont même pas besoin d’une baisse de prix pour rester compétitifs.
Si l’on compte bien sur Valencia et Interlagos pour donner plus de fil à retordre aux Xeon du côté des serveurs, nous sommes déçus de voir Zambezi afficher des performances comparables à celles des CPU Intel milieu de gamme 2010, une consommation équivalente à celle des processeurs très haut de gamme de la concurrence et enfin porter un préfixe qui faisait trembler le géant de Santa Clara il y a 8 ans.