L’entreprise affiche ses ambitions sur ce secteur avec des GPU en 7 nm.
Lors de sa journée des investisseurs, AMD a présenté son architecture GPU RDNA2 avec ray tracing matériel et du VRS. Mais la société en a également profité pour dévoiler une autre architecture GPU, baptisée CDNA. Si les cartes graphiques RDNA ciblent le graphisme, avec les marques Radeon RX et Radeon Pro, les cartes CDNA se destinent aux accélérateurs avec la gamme Radeon Instinct. Actuellement, ces cartes utilisent la vieillissante architecture Vega. Autant dire que pour concurrencer les GPU Tesla de NVIDIA, un renouvellement drastique s’imposait chez AMD.



Le secteur du HPC ayant des besoins très spécifiques, ces cartes n’embarquent pas de matériel graphique matriciel comme les moteurs d’affichage multimédia ou d’autres composants associés. En revanche, elles sont dopées en matériel de calcul tensoriel, semblables aux cœurs Tensor qu’on trouve sur les GPU de NVIDIA. Elles s’appuient aussi sur une interconnexion Infinity Fabric et de la mémoire HBM2e. Le premier GPU, gravé en 7 nm, arrivera dans le courant de l’année. AMD n’a pas précisé s’il était question de 7 nm EUV, comme les GPU RDNA2, ou de 7 nm DUV, comme les actuels GPU Navi.
Intel n’est pas très optimiste pour le 10 nm
CDNA2 et Infinity Fabric 3.0
La suite, l’architecture CDNA2, prendra forme entre 2021 et 2022. Elle n’est, pour l’heure, toujours pas finalisée. On peut supposer qu’elle profitera, à l’instar de l’architecture CPU Zen4, d’une gravure en 5 nm. La CDNA2 mettra le paquet sur l’hyper-scalabilité et la capacité à faire cohabiter un grand nombre de GPU sur de vastes pools.
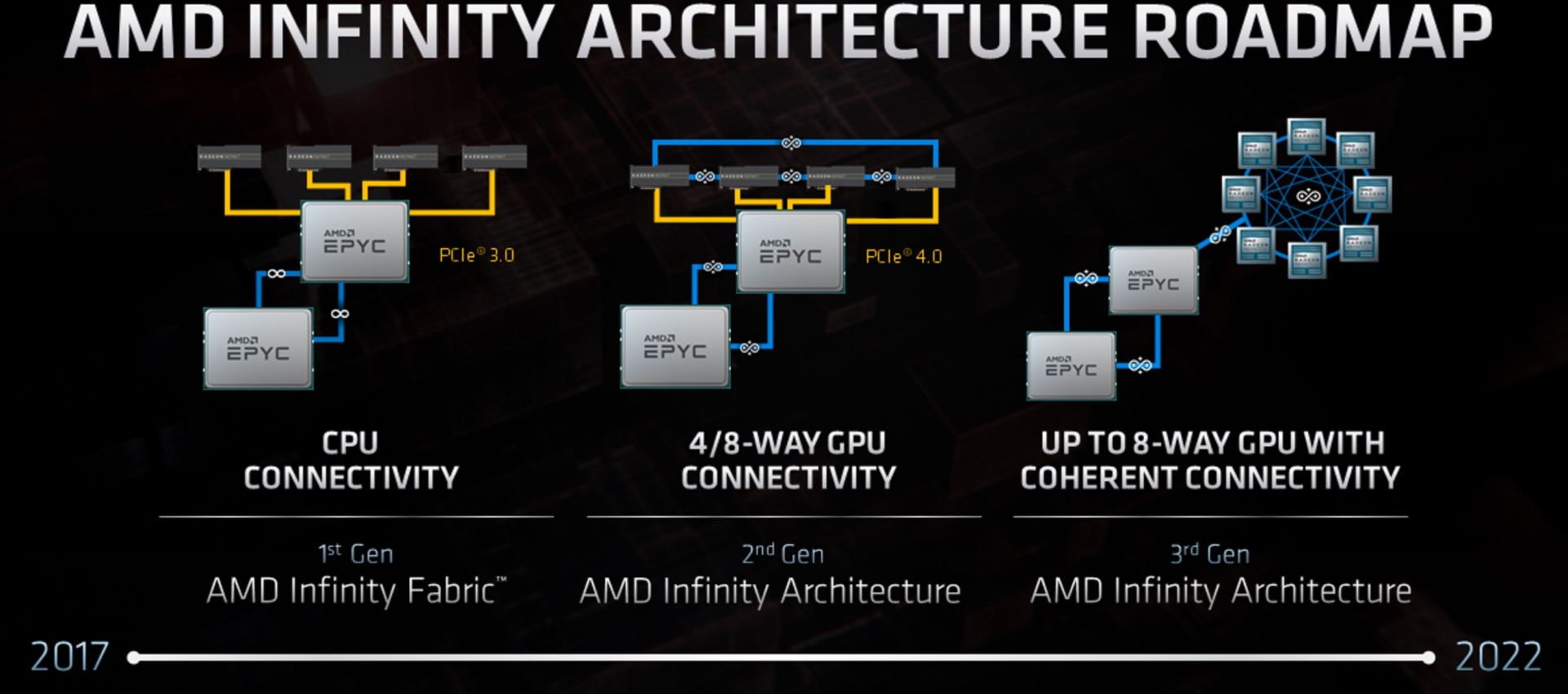
Pour y parvenir, AMD aura recours à une une technologie Infinity Fabric de troisième génération et à l’utilisation d’une mémoire unifiée. En effet, comme le Compute eXpress Link (CXL) d’Intel, l’Infinity Fabric 3.0 sera en mesure de gérer de la mémoire partagée entre les CPU et les GPU. Vous l’imaginez, cette mémoire unifiée permet de réduire les transferts de données entre la mémoire DRAM des CPU et la mémoire HBM des GPU. Les CPU sont ainsi en mesure de traiter directement des calculs GPU depuis la mémoire HBM. Enfin, sur le plan logiciel, AMD mise sur son écosystème open-source ROCm.












