Introduction

Quand la donnée prend le dessus. C’est ainsi que pourrait être, très vulgairement, résumé le Web sémantique. Un vaste projet qui a éclaté aux yeux de tous suite à l‘intervention de Tim Berners-Lee, patron du W3C – et également père du Web -, le consortium en charge de définir les standards du Web. Dans un entretien réalisé par le Courrier Unesco en 2000, il est parvenu à transmettre sa vision d’un autre web. Non pas le web 2.0, qui aujourd’hui bouleverse les usages du Web en donnant la parole aux internautes, en rendant le web plus participatif, non pas le Web 3.0 dont les contours restent encore aujourd’hui à géométrie variable – on parle notamment d’Internet des objets. Mais, bien un principe qui doit doter le Web d’une part d’intelligence qui lui fait défaut aujourd’hui.
“J’ai un double rêve pour le Web. D’une part, je le vois devenir un moyen très puissant de coopération entre les êtres humains. Et dans un second temps, j’aimerais que ce soit les ordinateurs qui coopèrent. […] Quand mon rêve sera réalisé, le Web sera un univers où la fantaisie de l’être humain et la logique de la machine pourront coexister pour former un mélange idéal et puissant.”
Une vision un peu magique d’un environnement connecté où seul le sens de l’information, de la donnée serait pris en compte pour livrer à l’internaute une information riche, contextualisée et fortement qualifiée. Bref logique. Une logique décrite informatiquement par des technologies, des standards qui créent des liaisons entre chaque donnée et chaque information pour lui donner du sens. Autrement dit, pousser beaucoup plus loin le concept de l’information comme on le conçoit aujourd’hui, pour débarquer dans un monde contrôlé par des vocabulaires, des thésaurus. Un monde où la donnée n’est pas considérée uniquement comme une donnée, mais comme une bulle sémantique.
Les activités liées au Web sémantique existent depuis 1998 au sein du W3C, et ont débouché depuis sur l’éclosion d’une série de technologies qui forment l’ossature de l’ensemble. Désormais presque matures, ces standards restent malgré tout peu utilisés, tout simplement car les principes du Web sémantique demeurent, eux aussi, un peu flous dans l’esprit des internautes et dans celui des entreprises.
Ce dossier vise à décrypter les mécanismes du Web sémantique, en tentant de livrer une définition aussi claire que possible, de faire un état des lieux des technologies qui orchestrent ce beau concept. Avant de faire un focus sur les usages, puis sur les ouvertures qu’apporte l’approche sémantique, notamment au niveau du poste de travail. En route vers le web des données.
Structurer et qualifier la donnée…
 Donner de l’intelligence aux données. Si nous avions à définir de façon imagée ce que peut être le Web sémantique, c’est ainsi que nous pourrions nous y prendre. Une approche qui pousse alors beaucoup plus loin la conception ainsi que les usages du Web, y compris 2.0.
Donner de l’intelligence aux données. Si nous avions à définir de façon imagée ce que peut être le Web sémantique, c’est ainsi que nous pourrions nous y prendre. Une approche qui pousse alors beaucoup plus loin la conception ainsi que les usages du Web, y compris 2.0.
Pour assimiler le concept du web sémantique, il convient d’abord de rappeler comment fonctionne, de façon succincte, le web classique. Le web, comme l’a créé Tim Berners-Lee, repose sur deux idées fondamentales : fournir un moyen d’échange de documents pour permettre aux chercheurs – à l’époque ceux du Cern – de concentrer les résultats de leurs travaux au sein d’un même lieu consultable par tous. Tim Berners-Lee crée alors une couche normalisée sur TCP/IP, qu’il baptise HTTP, pour partager des requêtes. Restait ensuite à créer un langage structurant, HTML, indépendant du reste, avec une particularité qui aujourd’hui fait la force du Web : le lien hypertexte. Ici, donc, le web prend une couleur très “document”.
Les technologies du Web sémantique poussent le concept beaucoup plus loin. Leur objectif : structurer de l’information pour créer informatiquement du sens qui serait compréhensible par les machines. On parle alors d’automatisation de la gestion de la connaissance. En structurant et qualifiant très fortement l’information et donc les données – par le biais de méta-données et d’annotations -, on parvient à enrichir le périmètre d’une donnée et de créer ainsi un champ sémantique. C’est la première étape. Suit ensuite celle qui va illustrer la puissance du Web sémantique : donner de la logique entre toutes ces données, et ce encore une fois de façon informatique, pour que l’ordinateur puisse livrer une représentation de la connaissance.
Nous entrons, si on se réfère à la vision de Tim Berners-Lee – bien qu’un peu utopique aujourd’hui -, dans un monde de dictionnaires, thésaurus, vocabulaires qui connectent et relient ensemble les données. La valeur sémantique de ces dernières prime avant tout.
Autre atout du web sémantique, les données, ainsi que le champ sémantique qu’on y attribue, sont par définition intéropérables. Selon le W3C, il s’agit de transformer le Web en une gigantesque base de données où tout serait partagé par tous et chaque bout d’information pourrait dialoguer avec un autre. Le web sémantique est donc bien un web de données – et non pas un web orienté document, comme nous le mentionnions précédemment. Ce sont les données qui, qualifiées, structurées et reliées en de multiples endroits puis placées dans un environnement distribué – le Web – forment la logique d’ensemble du web sémantique.
… pour la rendre ”intelligente”
Plutôt que de termes informatiques, le Web sémantique emprunte ses termes au domaine de la logique, c’est-à-dire aux logiciens. Un point évident car rappelons le, le Web sémantique vise à traduire informatiquement une représentation de la connaissance. L’exemple le plus probrant est le terme “Ontologie”, qui constitue une brique fondamentale de l’approche sémantique. L’ontologie, dans le cadre du Web sémantique, fournit les règles de logiques qui unissent et connectent les données, qui ont été au préalable définies. On parle également de règles d’inférence, autre terme également emprunté aux logiciens.
Un exemple ? Imaginons les technologies du web sémantique appliquées à un vaste catalogue d’un site de commerce électronique. En décrivant minutieusement chaque produit (en y ajoutant des méta-données), l’utilisateur dispose d’une vaste somme d’informations riches et logiques, auxquelles il a accès en fonction de sa recherche. Au produit est associé un nombre de données qui, elles-même, sont connectées à d’autres grâce à des règles pré-définies. Je recherche une cafetière, l’application m’affichera pour résultat, sa nature, son matériau, un comparatif de prix, sa provenance, mais également des informations sur le café. A chaque information, une autre se déclenche, logiquement.
Dans un contexte de recherche d’information, là encore, l’avantage du web sémantique est évident. Grâce à une somme de données connectées entre elles par des liaisons structurantes, les résultats d’une requête livre, non plus de seuls documents HTML contenant les termes de la recherche, mais un ensemble d’informations pertinentes et logiques. Les résultats de la recherche ne reposent plus sur les termes que renferment une page Web (comme pourrait le faire Google), mais sur des informations fournies par des données entrelaçées.
Reste alors à définir très précisément les données et à y ajouter ces logiques qualifiantes qui permettent de créer ce vaste réseau de liaisons. C’est ce que nous allons aborder dans la deuxième partie, consacrée aux technologies qui soutiennent le mécanisme du Web sémantique.
Une fusée Web à plusieurs étages
Comment ça marche ? Après une tentative de définition du web sémantique, entrons de plain pied dans les technologies qui coordonnent le concept.
Le web sémantique est une fusée à plusieurs étages, dont les premiers (qui servent de socle à l’ensemble) ne sont ni plus ni moins que des technologies 100% web, et normalisées par le W3C. Et donc considérées comme stables. Voici comment le W3C représente l’architecture du Web sémantique. Nous nous contenterons de notre côté de n’aborder que les pièces maîtresses de ce puzzle. Voici le “layercake” du Web Sémantique, comme le voit le W3C.
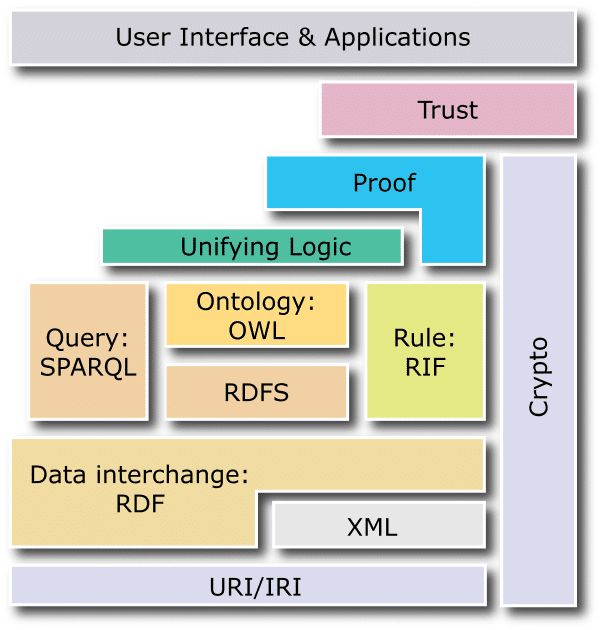
URI : localiser la ressource
C’est le premier pilier de l’édifice. Et un premier élement qui donne la couleur à l’ensemble. L’URI (Universal Resource Identifier) permet, comme son nom l’indique, d’identifier la localisation de la donnée et la méthode pour y parvenir (via HTTP, donc). L’application la plus connue de l’URI est l’URL (Uniform Resource Locator). Dans le web sémantique, les données sont identifiées grâce à ce processus, qui permet à l’agent intelligent qui scanne les données, d’aller rechercher la donnée – et l’information donc – là où elle est stockée.
RDF : la description des relations
Si XML sert également de fondation au web sémantique, en apportant la sérialisation – il structure l’information qui doit s’afficher -, le langage ne permet pas de définir les structures de données. C’est le rôle de RDF (Resource Definition Framework), qui constitue le pilier central indéboulonnable du web sémantique, en formant notamment une cartographie par graphe de l’information et de ses méta-données. C’est le langage qui permet de formuler les définitions propres aux données, de définir la structure des données.
Par exemple, pour traduire l’information “le tigre appartient à la familles des mammifères”, il faut définir comment est connectée la donnée “tigre” avec la donnée “mammifères”, et ce via la création de catégories et de sous-ensembles dans lesquels sont étiquetées les informations par propriété. Comme un thésaurus (dictionnaire hiérarchisé). C’est la notion de graphe RDF, qui illustre ainsi le classement entre les données.
Pour formaliser ces définitions, RDF s’appuie sur un schéma que l’on nomme “triplet”, sur le modèle “sujet – verbe – complément”. Chaque donnée est décrite sur ce type de définition – que l’on nomme prédicat de premier ordre (sujet – prédicat – objet).![]()
En reprenant notre exemple précédent, “le tigre appartient à la famille des mammifères”, cela donne : “Le tigre” = sujet ; “mammifères” = objet ; “appartient à la famille des” = prédicat. Si par exemple, des relations sont partagées, on parle de noeuds. Exemple :
- “le tigre”, “appartient à la famille des”, “mammifères”
- “mammifères”, “appartient à la famille”, “vertébré”
Dans ce cas, “mammifères”, alors objet dans la première relation, devient sujet dans la seconde. On parle dans ce cas de noeuds.
C’est ainsi que s’imbriquent les définitions avec RDF, permettant d’élaborer des graphes de la connaissance, matérialisant des groupes d’objets et les connexions qui les relient. Notons que chaque donnée de l’exemple précédent est identifiée grâce à des URI, qui localisent l’information.
OWL et SPARQL, compléments de RDF
OWL : les logiques qualifiantes

RDF, s’il décrit la structure, peine en revanche à décrire les liaisons logiques entre les triplets. C’est là qu’intervient OWL (Web Ontology language), dont la version 2.0 a été normalisée par le W3C en octobre 2009. Son principe : fournir des règles et des contraintes logiques entre les triplets définis en RDF de façon à permettre d’assurer un mécanisme d’interconnexion entre chaque élément. Et ce dans une grammaire également XML.
Par exemple, et toujours à partir de notre premier exemple, OWL va permettre d’écrire une ontologie qui décrira que le sujet relié au prédicat “appartient à la famille de” doit obligatoirement être un animal. OWL constitue dès lors le ciment du web sémantique car il donne la cohérence nécessaire aux imbrications formalisées en RDF. OWL fournit ici les inférences.
OWL pousse également le raisonnement plus loin, en proposant notamment des relations de transitivité. Si le tigre appartient à la famille des mammifères et qu’un mammifère est un vertébré, alors le tigre est un vertébré, pour reprendre notre exemple précédent. Autant dire qu’avec RDF, OWL forme un puissant duo de description, de relations et de logiques qui transmettent aux machines un semblant “d’intelligence”.
Pour cette raison, transposée dans le monde des systèmes d’entreprise, l’ontologie peut également servir à énoncer des règles métiers, qui viennent décrire les mécanismes d’un processus, propre à l’entreprise. Pour automatiser la gestion du savoir en interne, par exemple, surtout dans le cas d’entreprises à fort volume de données.
SPARQL : les requêtes sur RDF
Dernier étage clé de la fusée du Web sémantique, SPARQL (Query Language for RDF) est un langage de requête RDF, normalisé par le W3C en janvier 2008. Ce langage permet d’interroger n’importe quel élément du triplet que forme RDF. C’est le maillon essentiel qui permet de manipuler les données. Il s’apparente quelque peu à SQL – à qui il emprunte une partie de sa syntaxe -, dans le monde des bases de données relationnelles. SPARQL permet par exemple d’extraire un sous-graphe à partir d’un graphe RDF ou tout simplement d’en former un autre. Bref, SPARQL constitue la brique technologique qui vient compléter l’éco-système du Web sémantique et le rendre parfaitement exploitable. Le stack est complet.
Aussi complexe que cela puisse paraître, il existe des façons de faire du web sémantique, à la portée de tous. Une façon d’intégrer simplement des méta-données dans une simple page HTML. C’est ce qu’on appelle les microformats. Cela fera l’objet de la troisième partie de notre dossier.
Microformats : “sémantiser” HTML et xHTML
![]()
Appliquer les principes du web sémantique à une simple page HTML. C’est la promesse que tiennent les microformats : permettre d’intégrer au coeur de simples documents HTML des briques sémantiques afin de faciliter l’échange d’informations entre machines. L’un des avantages des microformats est que leur simplicité d’intégration et leur grammaire réduite les rendent également lisibles par l’humain.
Il s’agit ainsi d’apporter des marqueurs sémantiques dans les attributs HTML classiques – finalement un peu comme on pourrait le faire avec des feuilles de style CSS – de façon à qualifier l’information contenue. Ce que ne fait pas HTML, rappelons le, qui se contente quant à lui d’afficher le contenu. Les microformats ont pour objectif de se fondre dans les comportements du Web actuel, comme l’indique le site microformats.org.
Côté usage, les microformats servent aujourd’hui à décrire des données liées à la personne, comme son profil, son carnet d’adresse, l’agenda ou encore les données liées aux coordonnées géographiques. Des informations susceptibles d’être traitées par une autre application en ligne, échangées, ou tout simplement sauvegardées.
Il existe aujourd’hui un certain nombre – quoique assez réduit – de microformats, qui fournissent des marquages spécifiques, prêts à être insérés dans le code HTML. Parmi les plus connus, on retrouve :
- hCard, pour l’échange d’informations liées aux contacts – qui sert notamment de base à la populaire vCard (signature des emails)
- hCalendar, pour qualifier les événements
- hResume, pour les CV
- XFN, pour les relations entre personnes – ce microformat est le concurrent de FOAF (Friend of a friend)
- hReview, pour les critiques
Aujourd’hui, de nombreux sites à fort trafic implémentent les microformats, comme Yahoo Local, Flickr, Meet-up, Upcoming, Technorati, Ice Rocket, le .Mac d’Apple.
Microformats : comment ça marche ?
 Les marqueurs sémantiques s’insèrent via les attributs “class”, “rel” , propres au (x)HTML. Voici un exemple de code qui utilise hCard. D’abord le code HTML sans marqueur sémantique :
Les marqueurs sémantiques s’insèrent via les attributs “class”, “rel” , propres au (x)HTML. Voici un exemple de code qui utilise hCard. D’abord le code HTML sans marqueur sémantique :
<div class=”vcard-ex”>
<p><a href=”http://www.presence-pc.com/” title=”Tom’s Hardware”>Tom’s Hardware</a></p>
<p>Marc Hypollite</p>
<p>Puteaux, France</p>
<p>Mobile : 06.10.09.08.07</p>
</div>
Le même code, intégrant le microformat hCard :
<div class=”vcard”>
<a class=”url” href=”http://www.presence-pc.com/”>Tom’s Hardware</a>
<p class=”fn n”>
<span class=”given-name”>Marc </span>
<span class=”family-name”>Hypollite</span>
</p>
<p class=”adr”>
<span class=”locality”>Puteaux</span>
<span class=”country-name”>France</span>
</p>
<p class=”tel”>
<span class=”type”>Mobile :</span>
<span class=”value”> 06.10.09.08.07</span>
</p>
</div>
“given-name”, “family-name”, “country-name” et “fn n” sont des classes définies dans hCard, pour former une vCard. Il faut se référer à la documentation officielle pour connaître les classes disponibles.
Il existe une liste d’outils qui permettent de manipuler les formats ainsi que les implémentations qui en ont été faites sur le site microformats.org. On remarque notamment que Facebook supporte hCard et qu’il existe certaines extensions pour Firefox, dont le populaire Operator.
La sémantique intégré à HTML 5
Et le concept devrait peu à peu se propager au fur et à mesure des avancées des travaux du W3C. Le consortium en charge de normaliser les standards du Web a décidé d’intégrer la norme RDFa à HTML 5, la prochaine évolution du langage de structuration de web, qui doit notamment révolutionner la conception de pages Web (voir le dossier sur HTML 5). Et pour accélérer les développements, le consortium a ré-activé début février 2010 le groupe de travail sur RDFa, un groupe dissous après la publication de la version 1.0 du standard, comme il est de coutume au sein du W3C.
RDFa partage la même vision que les microformats : permettre d’intégrer au sein de documents HTML – via les attributs de ce même langage -, des éléments sémantiques destinés à enrichir la page. Clairement, associer des méta-données à un document HTML de façon à automatiser l’échange d’informations entre machines. Une des particularités des microformats est également d’être facilement implémentable et d’être lisible par l’humain. Le gros avantage est évidemment qu’il repose sur RDF, permettant ainsi de créer un stack de normes plus cohérent. Notons qu’à l’inverse les microformats ont été définis par la communauté de microformats.org. Ce ne sont dès lors pas des standards.
Les microformats représentent ainsi une façon pour le grand public de toucher du doigt la puissance du Web sémantique, partant d’un existant comme (x)HTML. Pour autant, ce n’est pas l’unique moyen d’entrer dans cet univers. Depuis plusieurs années, des laboratoires travaillent à transposer ces technologies vers le poste de travail. Donnant alors une autre application au concept. C’est ce que nous allons aborder dans notre dernière partie.
Le Web sémantique s’étend sur le poste de travail

Reposant pourtant sur une architecture 100% Web, comme nous avons pu le voir dans notre dossier, le Web sémantique et les technologies qui le motorisent trouvent des débouchés au sein d’environnements moins distribués.
Si l’ontologie peut notamment être utilisée pour décrire des processus métiers dans les entreprises, pour orchestrer l’automatisation de la gestion de la connaissance, à un degré moindre, on peut également retrouver le principe sur le poste de travail.
C’est notamment le cas avec le projet Nepomuk (pour Networked Environment for Personal Ontology-based Management of Unified Knowledge). Un projet de longue date auquel Mandriva, auprès de Thalès, SAP, HP et IBM pour ne citer qu’eux, a participé depuis son lancement en 2006. L’éditeur Open Source a publié le premier prototype d’implémentation Nepomuk avec la version 2010 de sa distribution Linux (Mandriva 2010, donc au sein du bureau KDE). Nepomuk apparaît alors sous la forme d’un Smart Desktop, pour reprendre le dialecte de la marque.
Son principe est simple et repose sur le constat suivant : l’utilisateur lambda croule sous un amas d’informations de sources différentes. Mail, flux Twitter, messagerie instantanée, autant de sources et de messages à gérer, classer et digérer par le biais d’applications différentes. L’objectif de Nepomuk est d’offrir la possibilité aux utilisateurs de se défaire du principe d’applications, et adopter celui de tâches, au sein desquelles seront rassemblés l‘ensemble des messages (de sources différentes). Ce tri “par action” est alors opéré par un module TaskTop qui permet à l’utilisateur de créer ses tâches et de trier les informations qui se retrouvent stockées dans une base de données RDF commune à chaque application. L’ontologie crée ici les liaisons logiques entre les tâches pour rendre l’ensemble cohérent.
Un premier pas, certes, mais qui rend visible toute l’ampleur des technologies liées au Web sémantique. Notons au passage que ce projet met également en lumière Scribo, qui intégré à Smart Desktop, permet d’extraire la connaissance à partir de textes et d’images et favorise l’annotation semi-automatique de documents numériques. Bref, les briques sont là. Et ne demandent qu’à évoluer.









